极小极大搜索方法、负值最大算法和Alpha-Beta搜索方法
1. 极小极大搜索方法
一般应用在博弈搜索中,比如:围棋,五子棋,象棋等。结果有三种可能:胜利、失败和平局。暴力搜索,如果想通过暴力搜索,把最终的结果得到的话,搜索树的深度太大了,机器不能满足,一般都是规定一个搜索的深度,在这个深度范围内进行深度优先搜索。
假设:A和B对弈,轮到A走棋了,那么我们会遍历A的每一个可能走棋方法,然后对于前面A的每一个走棋方法,遍历B的每一个走棋方法,然后接着遍历A的每一个走棋方法,如此下去,直到得到确定的结果或者达到了搜索深度的限制。当达到了搜索深度限制,此时无法判断结局如何,一般都是根据当前局面的形式,给出一个得分,计算得分的方法被称为评价函数,不同游戏的评价函数差别很大,需要很好的设计。
在搜索树中,表示A走棋的节点即为极大节点,表示B走棋的节点为极小节点。
如下图:A为极大节点,B为极小节点。称A为极大节点,是因为A会选择局面评分最大的一个走棋方法,称B为极小节点,是因为B会选择局面评分最小的一个走棋方法,这里的局面评分都是相对于A来说的。这样做就是假设A和B都会选择在有限的搜索深度内,得到的最好的走棋方法。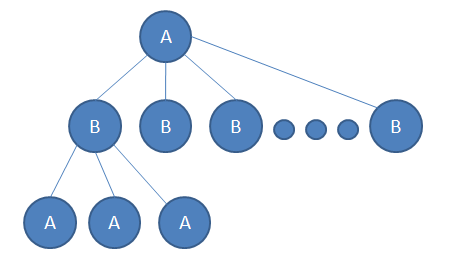
图-极大节点(A)与极小节点(B)
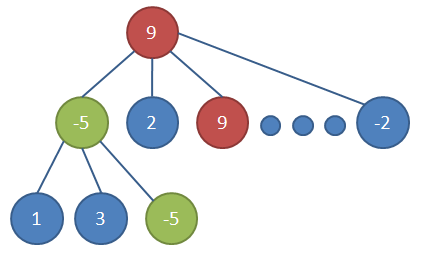
图-极大极小搜索
伪代码如下(来自维基百科):
function minimax(node, depth) // 指定当前节点和搜索深度
// 如果能得到确定的结果或者深度为零,使用评估函数返回局面得分
if node is a terminal node or depth =
return the heuristic value of node
// 如果轮到对手走棋,是极小节点,选择一个得分最小的走法
if the adversary is to play at node
let α := +∞
foreach child of node
α := min(α, minimax(child, depth-))
// 如果轮到我们走棋,是极大节点,选择一个得分最大的走法
else {we are to play at node}
let α := -∞
foreach child of node
α := max(α, minimax(child, depth-))
return α;
更加具体一些的算法:
int MinMax(int depth) { // 函数的评估都是以白方的角度来评估的
if (SideToMove() == WHITE) { // 白方是“最大”者
return Max(depth);
} else { // 黑方是“最小”者
return Min(depth);
}
}
int Max(int depth) {
int best = -INFINITY;
if (depth <= ) {
return Evaluate();
}
GenerateLegalMoves();
while (MovesLeft()) {
MakeNextMove();
val = Min(depth - );
UnmakeMove();
if (val > best) {
best = val;
}
}
return best;
}
int Min(int depth) {
int best = INFINITY; // 注意这里不同于“最大”算法
if (depth <= ) {
return Evaluate();
}
GenerateLegalMoves();
while (MovesLeft()) {
MakeNextMove();
val = Max(depth - );
UnmakeMove();
if (val < best) { // 注意这里不同于“最大”算法
best = val;
}
}
return best;
}
上面这段代码与前面的伪代码的思路都是一样的,只不过把最大算法和最小算法分为了两个函数。
2. 负值最大算法
前面的两段代码都是分别用两部分代码处理了极大节点和极小节点两种情况,其实,可以只用一部分代码,既处理极大节点也处理极小节点。
不同的是,前面的评估函数是针对白方即,指定的一方来给出分数的,这里的评估函数是根据当前搜索节点来给出分数的。每个人都会选取最大的分数,然后,返回到上一层节点时,会给出分数的相反数。
int NegaMax(int depth) {
int best = -INFINITY;
if (depth <= ) {
return Evaluate();
}
GenerateLegalMoves();
while (MovesLeft()) {
MakeNextMove();
val = -NegaMax(depth - ); // 注意这里有个负号
UnmakeMove();
if (val > best) { // 都是选择最大的分数,因为评估分数的对象变化了
best = val;
}
}
return best;
}
这个负值最大算法,主要是代码量上的减少,时间与空间上的效率没有什么提升。
3. Alpha-Beta搜索方法
举例来说,考虑下面的例子:
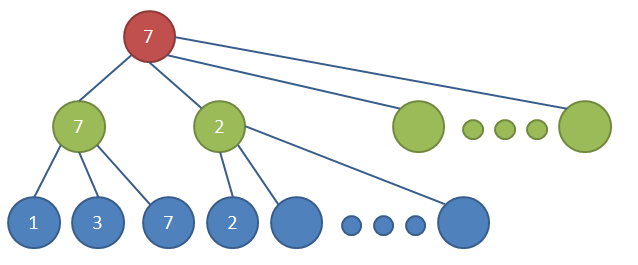
图-alpha-beta搜索
极小极大搜索是一个深度搜索,当搜索到第二层的第二个绿色的节点时,已知其第一个子节点返回值为2,因为这是一个极小节点,那么这个节点得到的值肯定是小于2的,而第二层的第一个绿色节点的值为7,因此这个节点后面即使都搜索了,也不会超过2,更不会超过7,因此这个节点后面的节点可以忽略,即图中第三册没有数字的节点。这属于Alpha剪枝,可能是剪掉的节点是极大节点的原因吧。相应的也有Beta剪枝,图中忽略了。
下面的维基百科伪代码,其中两个值,α表示搜索到的最好的值,β表示搜索到的最坏的值。
function alphabeta(node, depth, α, β, Player)
if depth = or node is a terminal node
return the heuristic value of node
if Player = MaxPlayer // 极大节点
for each child of node // 极小节点
α := max(α, alphabeta(child, depth-, α, β, not(Player) ))
if β ≤ α // 该极大节点的值>=α>=β,该极大节点后面的搜索到的值肯定会大于β,因此不会被其上层的极小节点所选用了。对于根节点,β为正无穷
break (* Beta cut-off *)
return α
else // 极小节点
for each child of node // 极大节点
β := min(β, alphabeta(child, depth-, α, β, not(Player) )) // 极小节点
if β ≤ α // 该极大节点的值<=β<=α,该极小节点后面的搜索到的值肯定会小于α,因此不会被其上层的极大节点所选用了。对于根节点,α为负无穷
break (* Alpha cut-off *)
return β
(* Initial call *)
alphabeta(origin, depth, -infinity, +infinity, MaxPlayer)
4. 参考资料
维基百科-极小化极大算法
最小-最大搜索 http://www.xqbase.com/computer/search_minimax.htm
Alpha-Beta搜索 http://www.xqbase.com/computer/search_alphabeta.htm
原文地址:http://www.cnblogs.com/pangxiaodong/archive/2011/05/26/2058864.html
极小极大搜索方法、负值最大算法和Alpha-Beta搜索方法的更多相关文章
- 转:极小极大搜索方法、负值最大算法和Alpha-Beta搜索方法
转自:极小极大搜索方法.负值最大算法和Alpha-Beta搜索方法 1. 极小极大搜索方法 一般应用在博弈搜索中,比如:围棋,五子棋,象棋等.结果有三种可能:胜利.失败和平局.暴力搜索,如果想通 ...
- IRT模型的参数估计方法(EM算法和MCMC算法)
1.IRT模型概述 IRT(item response theory 项目反映理论)模型.IRT模型用来描述被试者能力和项目特性之间的关系.在现实生活中,由于被试者的能力不能通过可观测的数据进行描述, ...
- 最小生成树的两种方法(Kruskal算法和Prim算法)
关于图的几个概念定义: 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图. 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连 ...
- 最短路径——Dijkstra算法和Floyd算法
Dijkstra算法概述 Dijkstra算法是由荷兰计算机科学家狄克斯特拉(Dijkstra)于1959 年提出的,因此又叫狄克斯特拉算法.是从一个顶点到其余各顶点的最短路径算法,解决的是有向图(无 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- MP算法和OMP算法及其思想
主要介绍MP(Matching Pursuits)算法和OMP(Orthogonal Matching Pursuit)算法[1],这两个算法尽管在90年代初就提出来了,但作为经典的算法,国内文献(可 ...
- BM算法和Sunday快速字符串匹配算法
BM算法研究了很久了,说实话BM算法的资料还是比较少的,之前找了个资料看了,还是觉得有点生涩难懂,找了篇更好的和算法更好的,总算是把BM算法搞懂了. 1977年,Robert S.Boyer和J St ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
随机推荐
- L2tp协议简单解析
1.L2TP简介 L2TP(Layer 2 Tunneling Protocol,二层隧道协议)是VPDN(Virtual PrivateDial-up Network,虚拟私有拨号网)隧道协议的一种 ...
- jQuery:总体掌握
链式编程....方法多,属性无法得到对象进行链式.vs10自动完成.书籍锋利的jQuery vsdoc有智能提示开发时候用,开发完之后,换成min压缩版的. 经验:打开网站文件夹.可以把vs网站上的解 ...
- Java静态初始化,实例初始化以及构造方法
首先有三个概念需要了解: 一.静态初始化:是指执行静态初始化块里面的内容. 二.实例初始化:是指执行实例初始化块里面的内容. 三.构造方法:一个名称跟类的名称一样的方法,特殊在于不带返回值. 我们先来 ...
- 疯狂JAVA——第二章 理解面向对象
面向对象的三大特征:继承.封装和多态 面向对象的方式实际上由OOA(面向对象分析).OOD(面向对象设计)和OOP(面相对象编程)三个部分组成,其中OOA和OOD的结构需要用一个描述方式来描述并记录, ...
- JFR 与 JProfilter Jvmisualvm
只有JFR 是可以在生产环境使用 采用C++独立写的采样手机功能 而 JProfilter/JVisualvm 都只能在测试环境下使用 使用instrument 机制 ,还有debug 框架 最早是 ...
- 如何在java中发起http和https请求
一般调用外部接口会需要用到http和https请求. 一.发起http请求 1.写http请求方法 //处理http请求 requestUrl为请求地址 requestMethod请求方式,值为&qu ...
- $.ajax dataType设置为json 回调函数不执行
请求方式如下: $.xpost = function (url, data) { return $.ajax({ url: url, type: "POST", dataType: ...
- dubbo通信协议
对dubbo的协议的学习,可以知道目前主流RPC通信大概是什么情况,本文参考dubbo官方文档 http://dubbo.io/User+Guide-zh.htm dubbo共支持如下几种通信协议: ...
- Java工具类_随机生成任意长度的字符串【密码、验证码】
import java.util.Random; public class PasswordCreate { /** * 获得密码 * @param len 密码长度 * @return */ pub ...
- 工作流和过程自动化框架 Camunda BPM
Camunda BPM 是一个灵活的工作流和过程自动化框架,它的核心是一个在Java虚拟机内部运行的原生BPMN 2.0流程引擎,因此它可以嵌入到任何Java应用程序或运行时容器中.Camunda B ...