Mysql优化之索引
前言
这几天抽了个时间将《高性能Mysql》看了一下忽觉索引非常之重要,习之然后总结巩固知识。本文索引使用的是InnoDB存储引擎。因为本文并不是说用索引的好处,所以并不会书写QPS之类的测试结果请大家见谅。我的mysql版本是8.0.11。
目录
(一)索引使用优化
①独立的列
②覆盖索引
③索引匹配
(二)索引创建优化
①前缀索引和索引选择性
②选择合适的索引顺序
③不创建冗余和重复索引
索引使用优化
我们有时候虽然创建了合适的索引但是使用不当依然会使索引失效,所以我将书上的索引使用大致总结了一下。在这之前我先介绍一下EXPLAIN生成结果中字段type和Extra的意义,先说一下type常出现的结果。
(1)const 表中最多只有一行用于主键和唯一索引的匹配
(2)all全表扫描
(3)ref使用索引并符合最左匹配
(4)index :❶
a.当查询是索引覆盖的,即所有数据均可从索引树获取的时候(Extra中有Using Index);
b.以索引顺序从索引中查找数据行的全表扫描(无 Using Index);
c.如果Extra中Using Index与Using Where同时出现的话,则是利用索引查找键值的意思;
d.如单独出现,则是用读索引来代替读行,但不用于查找
接下来我们解释一下Extra出现的结果:
(1)using index 使用覆盖索引。
(2)using where 条件语句中部分条件使用的是索引,其他条件需要去表中筛选。
(3)using inex condition 条件语句中所有条件都在索引中,但是所需要的数据不在索引中。
(4)using where;using index 条件和所需数据都在索引中。
独立的列
独立的列一眼上看去以为是针对于一个单独的列创建索引但是实际上并不是这样的。“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数❷。这句话的前面一句话在书上是:如果使用独立的列则mysql不会使用索引。这句话有点模棱两可,“不会使用索引”到底是包括索引全扫描还是不包括索引全扫描,如果包括的话则与实验结果不相符,如果不包括的话那就没问题了。废话不多说还是用结果来证明吧。首先我的数据库表结构是这样子的,如下图所示:

我创建了两个单独列的索引用来测试表达式和函数如下图所示:


测试sql: explain select age from user where age =2;

从测试结果中我们可以看到type为ref(使用BTree索引),Extra为Using index(使用了覆盖索引)
如果我们把sql语句改为: explain select age from user where age+1=2;解释结果如下所示:

可以看到这条查询语句是使用了索引的,不过是扫描索引的全部数据。接下来测试一下如果条件语句中使用了函数是否会使用索引我的sql语是:EXPLAIN SELECT id from user where TO_DAYS(birthday) >= 50000000;测试结果如下图所示:
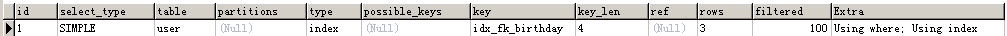
OK,结果也是index。至于书上那句话是对是错我就不得而知了,不过大家可以自己去测试一下。
覆盖索引
如果把使用索引比作你开了一辆五菱宏光的话,那么你使用覆盖索引就是开了一辆兰博基尼(兰博基尼的性能是由你自己来决定的)。覆盖索引简单的来讲就是你所要查询的字段和条件语句都在一条索引中。接下来又是证明的过程,我创建一个新的索引如下图所示:

然后我使用这条sql语句 EXPLAIN SELECT first_name,age from user where first_name='张' and age >0,在这条sql语句中我查询两个不同索引中的列查询结果如下所示;

在这条sql语句中我使用了两个索引idx_fk_name和idx_fk_age,查询的列和查询条件都是在这两个索引中,测试的结果为using where(需要回表查询所需要的数据)。接下来我们使用这个sql语句 EXPLAIN SELECT last_name FROM user where first_name = '张',使用结果如下图所示:

索引匹配
如果我们书写的sql语句符合索引匹配原则,那么我们就可以不进行索引的全部数据扫描,结果就是我们的查询效率又变高了。那么索引匹配原则是啥?我就简略的总结一下吧。
全值匹配
全值匹配就是查询条件和索引中的所有列进行匹配。如我上面创建的idx_fx_name索引。select * from user where first_name='张' 和 last_name = '三' 这条sql语句就是全值匹配。注意如果写成last_name='三' and first_name='张'也是全值匹配
最左匹配
我把书中匹配最左前缀和匹配列前缀都划分为最左匹配,因为我觉得它都是从最左边开始匹配的,好像网上也是这么说的。
最左前缀就是你写的条件查询语句针对于某个索引来说它符合从左边一个一个进行匹配的方式(经过实测条件语句的顺序不影响最左匹配的原则),再拿我的idx_fx_name索引来举个例子。如select * from user where last_name = '三'和 select * from user where first_name = '张' 这两个sql语句查询索引的方式都不一样,前者是扫描索引所有数据,第二个就只扫描了索引的部分数据。测试结果如下所示:


匹配范围值
在符合最左匹配的基础上可以使用范围进行查询。
精确匹配加范围匹配
在符合最左匹配的基础上最后一个查询条件可以记性范围查询。
索引创建优化
前缀索引和索引选择性
我们先说说索引的选择性吧。索引的选择性是指不重复的索引值(也称为基数,cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间❸。这句话通俗的理解就是你选择作为索引(当然是只能选择某个字段,字段的全部或者部分)的数据在表中这个字段列中重复率越低越好,因为这样可以过滤更多的数据行。前缀索引就是可以拿某个字段的前缀作为索引之所以把前缀所以和索引选择性放到一起说是为了解决当我们选择一个特别长的字段作为索引时首先会很浪费空间其次是查询的时候速度肯定会比较慢。
那么我们怎么计算索引选择性的高低呢?这个有方法的,方法就是通过关键字DISTINCT 和 Count来计算索引的选择性。如我计算first_name的选择性高低可以这样计算:
select count(DISTINCT first_name) / count(1) as a1 from user;
如果我要计算以first_name前三个字符作为索引的话计算选择性可以这样写:
select count(DISTINCT LEFT(first_name,3)) / count(1) as a1 from user;
通过不断的修改所包含的前缀的大小我们就能找到选择性高的索引。
选择合适的索引序列
其实选择合适的索引序列我觉得根据实际情况来做分析。不过一般来说我们都把选择性高的放在前面,其他的就是要根据where子句中的排序、分组和范围条件等其他因素来选择索引的序列
不创建冗余和重复的索引
这里有两个问题摆在我们的面前什么是冗余的索引?什么是重复索引?
重复索引:具有相同列的索引就是重复索引。如(A,B)和(B,A)就是重复索引。
冗余索引:一个索引的子集就是冗余索引。如(A,B,C) 和(A,B) (B,C)就是冗余索引。
从一般情况来说就是尽量不创建重复索引和冗余索引,但是在特殊的情况下我们可以创建冗余索引。
总结
以上就是我学习《高性能mysql》书籍的总结。如果有什么问题请大家及时反馈给我毕竟互相交流才能促进学习。
借鉴书籍或博客
❶http://blog.51cto.com/lijianjun/1881208
❷《高性能mysql》第五章第三节
❸《高性能msql》第五章第三节第二小节
Mysql优化之索引的更多相关文章
- mysql 优化之索引的使用
mysql 优化之索引的使用 1:MySQL 索引简介: MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL ...
- mysql优化之索引篇
对mysql优化是一个综合性的技术,主要包括 a: 表的设计合理化(符合3NF) b: 添加适当索引(index) [四种: 普通索引.主键索引.唯一索引unique.全文索引] c: 分表技术(水平 ...
- mysql优化之索引优化
Posted by Money Talks on 2012/02/23 | 第一篇 序章第二篇 连接优化第三篇 索引优化第四篇 查询优化第五篇 到实战中去 索引优化 索引优化涉及到几个方面,包括了索引 ...
- Mysql优化之索引和字段
Mysql优化是一个老生常谈的问题, 优化的方向也优化很多:从架构层;从设计层;从存储层;从SQL语句层; 今天讲解一下从索引和字段: 字段优化: ① 尽量使用TINYINT.SMALLINT.ME ...
- 第九课——MySQL优化之索引和执行计划
一.创建索引需要关注什么? 1.关注基数列唯一键的数量: 比如性别,该列只有男女之分,所以性别列基数是2: 2.关注选择性列唯一键与行数的比值,这个比值范围在0~1之前,值越小越好: 其实,选择性列唯 ...
- mysql优化之索引建立的规则
索引经常使用的数据结构为B+树.结构例如以下 如上图,是一颗b+树,关于b+树的定义能够參见B+树,这里仅仅说一些重点.浅蓝色的块我们称之为一个磁盘块,能够看到每一个磁盘块包括几个数据项(深蓝色所看到 ...
- MySQL优化四 索引优化
索引为什么能提高数据访问性能? 很多人只知道索引能够提高数据库的性能,但并不是特别了解其原理,其实我们可以用一个生活中的示例来理解. 我们让一位不太懂计算机的朋友去图书馆确认一本叫做<MySQL ...
- 【Mysql优化】索引优化策略
1:索引类型 1.1 B-tree索引 注: 名叫btree索引,大的方面看,都用的平衡树,但具体的实现上, 各引擎稍有不同, 比如,严格的说,NDB引擎,使用的是T-tree Myisam,in ...
- MySQL优化之索引原理(二)
一,前言 上一篇内容说到了MySQL存储引擎的相关内容,及数据类型的选择优化.下面再来说说索引的内容,包括对B-Tree和B+Tree两者的区别. 1.1,什么是索引 索引是存储引擎用于快速找 ...
随机推荐
- ZT 80-90年代港台300部电视剧 你看过多少?
80-90年代港台300部电视剧 你看过多少? [复制链接] 噗噗 738主题 18精华 万家金领 发消息 发表于 2010-4-27 09:01:02 |显示全部楼层 1.(珍珠传奇) ...
- My Heart Will Go On(我心永恒)
My Heart Will Go On(我心永恒) 歌词(英文) 歌词(中文) 简介:电影<泰坦尼克号>插曲 歌手:Celine Dion(席琳·迪翁) 词作:韦尔·杰宁斯(Wil ...
- php 中使用cURL发送get/post请求,上传图片,批处理
cURL是利用url语法规定传输文件和数据的工具.php中有curl拓展,一般用来实现网络抓取,模拟发送get post请求,文件上传. 在php中建立curl的基本步骤如下: 1 初始化 ...
- 安装配置maven私服-nexus
1.ubuntu下的Bundle安装方式 1.1. 去官网下载安装包:http://www.sonatype.org/nexus/ 我这里下载的是:nexus-2.8.1-01-bundle.zip, ...
- C语言利用 void 类型指针实现面向对象类概念与抽象。
不使用C++时,很多C语言新手可能认为C语言缺乏了面向对象和抽象性,事实上,C语言通过某种组合方式,可以间接性的实现面对对象和抽象. 不过多态和继承这种实现,就有点小麻烦,但是依然可以实现. 核心: ...
- 1251. 序列终结者【平衡树-splay】
Description 网上有许多题,就是给定一个序列,要你支持几种操作:A.B.C.D.一看另一道题,又是一个序列 要支持几种操作:D.C.B.A.尤其是我们这里的某人,出模拟试题,居然还出了一道这 ...
- 20155314 2016-2017-2 《Java程序设计》实验二 Java面向对象程序设计
20155314 2016-2017-2 <Java程序设计>实验二 Java面向对象程序设计 实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UM ...
- 美团热修复Robust的踩坑之旅-使用篇
最近需要在项目中使用热修复框架,在这里以美团的Robust为主写一篇文章总结一下学习的过程. 一直认为要学习一个框架的原理,首先需要让他跑起来,从效果反推回去,这样更容易理解. 一.美团Robust的 ...
- [笔记] Delphi 10.2.1 Tokyo 安装使用笔记
Android 平台: ListView 滑动速度已有改善,但比起 Berlin 还是略慢一些(在较慢的机子可感觉的到)仅于 Android 平台,其它平台没差. TMemo, TEdit 输入文字的 ...
- VIM - tab 相关的简单配置
1. 概述 vim 是强大的文本编辑器 使用 vim 前, 需要做些简单配置, 来让 vim 更符合自己的操作习惯 想看配置项的, 直接到最后 2. 准备 安装 vim 略 配置文件 位置 /etc/ ...