Hadoop初探
本文转自:https://blog.csdn.net/column/details/14334.html
前言
Hadoop是什么? 用百科上的话说:“Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。” 可能有些抽象,这个问题可以在一步步学习Hadoop的各种知识以后再回过头来重新看待。
Hadoop大家族
Hadoop不是一个单一的项目,经过10年的发展,Hadoop已经成为了一个拥有近20个产品的庞大家族。 其中最核心的包括以下9个产品,并且我们将按照下面的顺序一步步学习。
Hadoop:是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构 Hive:基于Hadoop的一个数据仓库工具 Pig:基于Hadoop的大规模数据分析工具 Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务 HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群 Mahout:基于Hadoop的机器学习和数据挖掘的一个分布式框架 Sqoop:是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 Cassandra::是一套开源分布式NoSQL数据库系统 Flume:是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
好,接下来开始正式学习Hadoop。
1 环境搭建
Hadoop安装有如下三种方式:
单机模式:安装简单,几乎不用作任何配置,但仅限于调试用途; 伪分布模式:在单节点上同时启动NameNode、DataNode、JobTracker、TaskTracker、 Secondary Namenode等5个进程,模拟分布式运行的各个节点; 完全分布式模式:正常的Hadoop集群,由多个各司其职的节点构成
接下来,我们进行伪分布式环境的搭建。
操作系统:Ubuntu 16.04 LTS JDK: JDK1.8 Hadoop:2.6.0
S1 创建hadoop用户
首先切换到root用户
su root
创建用户,设置密码,并为其分配管理员权限
useradd -m hadoop -s /bin/bash
passwd hadoop
adduser hadoop sudo创建成功后注销当前用户,使用hadoop用户重新登入。
S2 更新apt
后续需要使用apt进行软件的安装,在这里先更新一下apt,执行如下命令:
sudo apt-get updateS3 安装vim
安装用于修改文件的vim
sudo apt-get install vimS4 安装SSH
安装SSH用于远程登陆控制。 ubuntu默认安装了SSH client,我们需要安装SSH server,使用如下命令:
sudo apt-get install openssh-server使用如下命令即可登入本机
ssh localhostS5 安装JDK
首先在官网下载jdk1.8安装包,我下载的是: jdk-8u111-linux-x64.tar.gz 在usr/lib目录下新建jvm文件夹并授权:
cd /user/lib
sudo mkdir jvm
sudo chown hadoop ./jvm
sudo chmod -R 777 ./jvm将下载的安装包拷贝到jvm目录下。 在jvm目录下,执行下面命令进行解压,并重命名
sudo tar zxvf jdk-8u111-linux-x64.tar.gz
sudo mv jdk1.8.0_111 java继续在jvm目录下执行下面命令进入vim编辑器,按”I”进入编辑模式,
vim ~/.bashrc光标移到最前面,输入下面内容(必须写到开头,写在末尾在后边会出现找不到java_home的情况):
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib;${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH先按ESC键,然后按shift+zz保存退出,回到命令行模式输入下面命令使修改生效
source ~/.bashrc这样就配置完了,可以使用下面命令验证是否安装成功。
echo ¥JAVA_HOME
java -version
$JAVA_HOME/bin/java -versionS6 安装Hadoop2
在http://mirror.bit.edu.cn/apache/hadoop/common/ 页面下载hadoop-2.6.0.tar.gz和hadoop-2.6.0.tar.gz.mds
新建hadoop文件并授权
cd /usr/local
sudo mkdir hadoop
sudo chown hadoop ./hadoop
sudo chmod -R 777 ./hadoop将下载好的文件拷贝到该目录下 执行下面命令(我也不清楚干嘛用)
cat /usr/local/hadoop/hadoop-2.6.0.tar.gz.mds|grep 'MD5'
md5sum /usr/local/hadoop/hadoop-2.6.0.tar.gz|tr "a-z" "A-Z"切换到/usr/local/hadoop目录,进行解压并重命名:
cd /usr/local/hadoop
sudo tar -zxf hadoop-2.6.0.tar.gz
sudo mv hadoop-2.6.0 hadoop2hadoop解压后即可用,使用下面命令验证:
cd /usr/local/hadoop/hadoop2
./bin/hadoop versionS7 伪分布式配置
Hadoop的运行方式是以配置文件决定的。 文件位于/usr/local/hadoop/hadoop2/etc/hadoop/中,需要对core-site.xmlh和hdfs-site.xml文件进行修改。 先为用户授权:
cd /usr/local/hadoop
sudo chown hadoop ./hadoop2
sudo chmod -R 777 ./hadoop2执行下面命令:
cd /usr/local/hadoop/hadoop2
gedit ./etc/hadoop/core-site.xml修改为如下配置并保存:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>执行下面命令:
gedit ./etc/hadoop/hdfs-site.xml修改为如下配置并保存:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>如果需要改为非分布式,再把修改的内容删掉即可。 执行下面命令进行namenode的格式化(hadoop2目录下执行)
./bin/hdfs namenode -format看到Successfully formatted即为成功。 执行下面命令开去NameNode和DataNode的守护进程
./sbin/start-dfs.sh按提示一步步操作,启动完成后使用下面命令验证:
jps出现“NameNode”、”DataNode” 和 “SecondaryNameNode”即表示启动成功。SecondaryNameNode没有启动的话请重新启动,其他两个没有启动的话检查之前的配置。 启动成功后,浏览器地址栏输入:localhost:50070可以查看NameNode和Datanode的信息。
2 Hadoop初探
把环境搭建好,心里就踏实了,接下来先了解一些必要的理论知识。
2.1 为什么用Hadoop?
任何事物的产生都有其必然性。 从2012年开始,大数据这个词被越来越多的提及,现在我们已经进入了大数据时代。在这个信息爆炸的时代,每天产生的数据量十分庞大。而大数据也不仅仅只是说数据多,大数据有四个特点: 数据量大,类型繁多,价值密度低,速度快时效高。 根据这几个特点,我们需要一个东西,具备以下功能:
1.可以存储大量数据
2.可以快速处理大量数据
3.可以从大量数据中进行分析
于是就产生了Hadoop这个模型:

看起来就像一个系统,HDFS和MapReduce是底层,Hive,Pig,Mathout,Zookeeper,Flume,Sqoop,HBase是基于底层系统的一些软件。 所以Hadoop核心中的核心是HDFS和MapReduce。
所以说: Hadoop就是一个用于处理大数据的计算框架,Hadoop具有分布式、可靠、可伸缩的特性。 分布式:Hadoop通过将文件和任务分配到众多的计算机节点上来提高效率。 可靠:由于是分布式的,所以其中一个或几个节点出现故障,并不会影响整个程序的运行。 可伸缩:任何一个节点的添加和删除都不会影响程序的运行。
2.2 单节点体系
实际应用中我们是使用一个有N多台计算机构成的集群(也可以使用多个创建多个虚拟机来模拟)来使用Hadoop的,如果仅仅只有一台计算机,那就失去了Hadoop存在的意义。 每台计算机,我们称之为一个节点,我们需要为每一个节点都配置Hadoop,通过上边的配置过程,我们可以知道,单节点(即每一台计算机)adoop的体系结构就像下面的图;

2.2 HDFS
HDFS全称是Hadoop Distribute file system ,即Hadoopp分布式文件系统。 现在的数据量已经达到了PB级(1PB=1024T),对于单个硬盘来说,存储这个数量级的数据具有相当大的压力。所以很自然的我们就会想到将数据切割开来,存储到多个计算机中,由此诞生了分布式文件系统。 为了实现数据的可靠性安全性,HDFS会对每份数据创建副本,默认值是3,及默认情况下一份数据存储在三个不同的节点上,由此导致HDFS具有如下特点:
1.高度的数据冗余**:这也是没有办法的事,要提高可靠性,冗余是必不可少的。
2.适合一次写入,多次读取:由于在写入数据的时候需要为数据创建副本,所以写入的成本很高,如果涉及到了高频率的IO写入,不适合使用Hadoop
3.适合存储大文件,不适合小文件:在HDFS中存在Block的概念,Block是HDFS的存储单元,默认是64M,很多企业已经调整为128M。在存储文件时,会把大文件分割开来存储在一个个的Block块中,一个Block块只会存储一个文件。所以如果存储的小文件过多将造成大量存储空间的浪费。
4.对硬件的要求低:可以运用于廉价的商业服务器上,不需要使用性能很高但昂贵的服务器。
2.2.1 NameNode,dataNode以及secondary namenode
HDFS集群是以Master-Slave模式运行的,其实也可以像nginx中那样说成是Master-worker,一个意思。主要涉及到两种节点,一是nameNode,即Master,另一个是大量的dataNode即worker. 下图是Apache官网关于NameNode和dataNode的关系图:
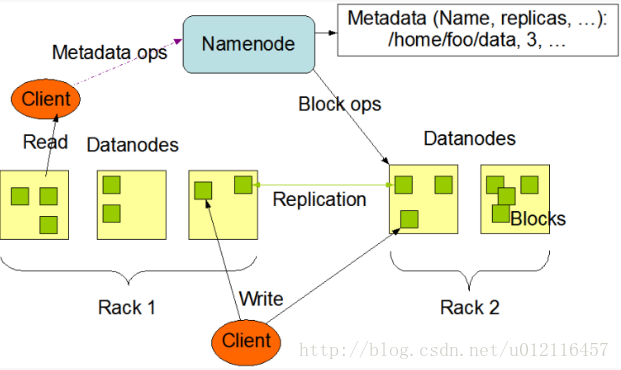
NameNode只有一个,负责维护整个文件系统的元数据,这里的元数据包含每个文件、文件位置以及这些文件及其所在的DataNode内的所有数据块的内存映射。 dataNode存在于每一个节点中,负责具体的工作,包括为读写请求提供服务以及按照NameNode的指令执行数据块创建、删除和复制。 客户端(client)代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一些列的文件系统接口,因此我们在编程时,几乎无须知道datanode和namenode,即可完成我们所需要的功能。 secondary NameNode 要了解secondary NameNode,首先需要先了解namenode的容错机制。 从上图可以看出,一个Hadoop集群中只要一个nameNode,一旦namenode出现故障,整个集群将会瘫痪,所以namenode必须要有良好的容错机制。 第一种方式是远程备份:即在namenode将数据写入磁盘时,同步在一个远程服务器上创建数据的副本。 第二种方式是使用辅助namenode即secondary namenode: 首先我们需要知道的是namenode将数据保存在了Namespace镜像和操作日志中,secondary namenode的主要作用是将这两个文件定期进行合并。 但是由于是定期执行,secondaryname并不能实时同步主namenode的数据,所以一旦namenode挂掉,不可避免的会造成数据丢失,所以稳妥的方式就是结合两种方法,当主namenode宕掉时,将secondary namenode的数据拷贝到secondary namenode,然后再让secondarynamenode充当namenode的作用。
2.3 MapReduce
MapReduce是Hadoop的分布式计算框架,现在我们只做初步的了解。 MapReduce=Map+Reduce,即MapReduce分为Map的过程和Reduce的过程。这两个刚才都是需要我们通过程序来控制的。 先看下面这张图:
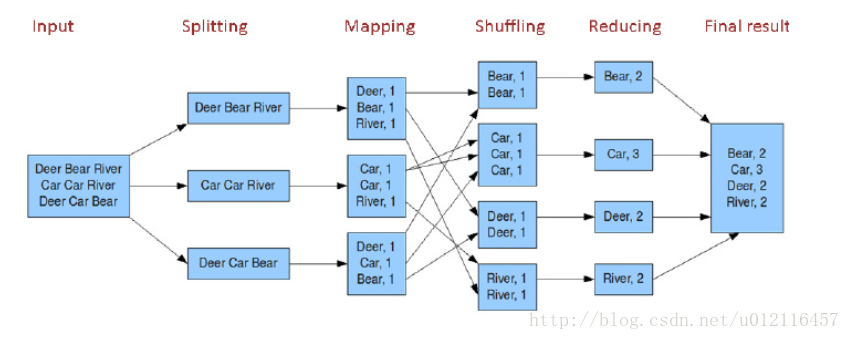
这张图是在网上找的。 如上图所示就是MapReduce处理的一个完整的过程。 Input:最左边是输入的过程,输入了图示的数据。 Split分片:mapreduce会根据输入的文件计算分片,每个分片对应与一个map任务。而分片的过程和HDFS密切相关,比如HDFS的一个block大小为64M,我们输入的三个文件分比为10M,65M,128M,这样的话第一个文件生成一个10M的分片,第二个文件生成一个64M的分片和一个1M的分片,第三个文件生生成两个64M的分片,这样的话就会一共生成5个分片。 Map:map阶段是由编程人员通过代码来控制的,图中所示的大概内容就是将字符串分割开来,作为键存储在map中,值的位置存储1,表示数量。 shuffle洗牌:洗牌阶段,由于之前生成map中存在很多键相同的map,在洗牌阶段将键相同的进行合并。 Reduce:reduce阶段也是有开发人员通过代码控制,本例中是将键相同的map的value值进行求和,得出最终的map 这样最后输出的数据就是每个字符串出现的次数。
总结
写到这里,这篇文章就基本上告一段落了,这篇文章主要包含两个内容: 1.在Ubuntu环境搭建伪分布式Hadoop环境。 2.关于Hadoop的一些简单的必要的理论知识,主要是HDFS和MapReduce
本文转自:https://blog.csdn.net/u012116457/article/details/53859594
Hadoop初探的更多相关文章
- hadoop 初探之第二篇(杂谈)
NameNode:名称节点,主要功能在于实现保存文件元数据,这些元数据直接保存在内存中,为了保证元数据的持久性,而也会周期性的同步到磁盘上去.磁盘上的数据通常被称为元数据的映像数据 image fil ...
- Hadoop之mapreduce
doc Hadoop初探之Stream Hadoop Stream 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + ...
- Scalding初探之三:Hadoop实战
Java版本 如果在Scala工程中混入Java类导致java版本不match,可能会抛错 java.lang.UnsupportedClassVersionError: XXX Unsupporte ...
- Scalding初探之一:基于Scala的Hadoop利器
把你从写繁琐的Map-reduce Job中解放出来,写分布式跟写本地程序没两样,Scala真真代表着先进生产力的方向啊. 好的,今天开始直播基于Scala的Scalding啦,循序渐进地看以下页面: ...
- Hadoop集群(第8期)_HDFS初探之旅
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- Hadoop 2 初探
Hadoop 2.6.0的安装略复杂,在一台既有Hadoop 1又有Hadoop 2的server上,要设置好环境变量,必要时候echo $HADOOP_HOME一下看运行的是哪个版本. Master ...
- Hadoop 架构初探
对流行Hadoop做了一些最基本的了解,暂时没太大感觉,恩先记点笔记吧. = = Hadoop 基本命令及环境安装 一.下载虚拟机镜像 目前比较流行的有以下三个: (CHD) http://www.c ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- hive hadoop 大数据初探
一.环境搭建: 1.安装虚拟机,mac 系统推荐parallels:直接转化讲师发的xmdl后缀名的文件:里面自带了环境: 注意事项:mac 本机和虚拟机中centos 的通讯,需要修改centos中 ...
随机推荐
- JavaScript总结(三)
如何执行代码语句? 使用函数,函数是一组可以随时随地运行的语句,它们是JavaScript的核心.函数是由关键字function.函数名加一组参数以及置于括号中要执行的代码声明的.语法如下: Func ...
- 4539: [Hnoi2016]树
4539: [Hnoi2016]树 链接 分析: 主席树+倍增. 代码: #include<cstdio> #include<algorithm> #include<cs ...
- P4284 [SHOI2014]概率充电器
P4284 [SHOI2014]概率充电器 今天上课讲到的题orz,第一次做这种上下搞两次dp的题. g[i]表示i的子树(包括i)不给i充电的概率. f[i]表示i的父亲不给i充电的概率. g[]可 ...
- 解决 spring-test 出现 Failed to load ApplicationContext 的异常
在使用spring-test的时候,在启动@Test的方法时,spring-test会去加载spring的配置文件,这个时候如果配置文件没有在 @ContextConfiguration 中写全,就会 ...
- vi/vim 常用命令 之 一图定天下!
直接上干活,一张图解决~
- matplotlib简单示例
一.简介 以下引用自百度百科 Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形 . 通过 Matplotlib,开发者可以仅需要 ...
- Bailian 2808 校门外的树(入门线段树)
题目链接:http://bailian.openjudge.cn/practice/2808?lang=en_US 总时间限制: 1000ms 内存限制: 65536kB 描述 某校大门外长度为L的马 ...
- AssetBundle加载API
AssetBundle加载API 在Unity 5当中,可以通过4个不同的API来加载AssetBundle,4个API可以用两个条件来区分: AssetBundle是 LZMA压缩. LZ4压缩还是 ...
- java IO流 对文件操作的代码集合
Io流 按照分类 有两种分类 流向方向: 有输入流和输出流 按照操作类型有:字节流和字符流 按照流向方向 字节流的一些操作 //读文件 FileInputStream fis = new FileIn ...
- maven项目的标准目录结构
maven项目的标准目录结构如下: