P4: Programming Protocol-Independent Packet Processors
P4: Programming Protocol-Independent Packet Processors
摘要
P4是一门高级语言,用于编程与协议无关的数据包处理器。P4与SDN控制协议相关联,类似与OpenFlow。当前,OpenFlow明确指定了运行的协议头。这个设置在几年内,从12个字段增长到41个字段,并且增加了协议头的复杂性,却没有提供应有的灵活性。本文提出P4作为OpenFlow将来演化发展的目标。我们有三个目标:(1)字段可重配性(2)协议独立性(3)目标无关性。
1 引言
SDN使得操作人员可编程化的控制他们的网络,在SDN中,控制平面与转发平面分离,控制平面控制多个转发设备,同时,转发设备可以通过共有的,开放的,厂商无关的接口(比如OpenFlow),使得控制平面可以对不同的软件、硬件服务商进行控制。
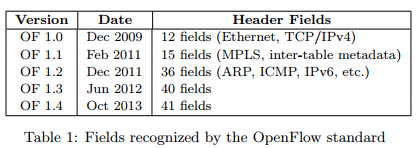
OpenFlow接口开始是很简单的,简单的表匹配规则概念可以在多个头字段进行匹配(比如MAC地址,IP地址,协议,TCP/UDP端口数字等)。在过去五年,随着多个阶段的规则表和更多的头字段,配置变得愈加的复杂(表1所示)。头字段增加的现象并没有停止,为了取代这种不断扩展OpenFlow配置的现象,我们认为将来的交换机应该提供灵活的机制,以支持解析数据包和匹配头字段。控制器通过接口,可以利用这些优势。
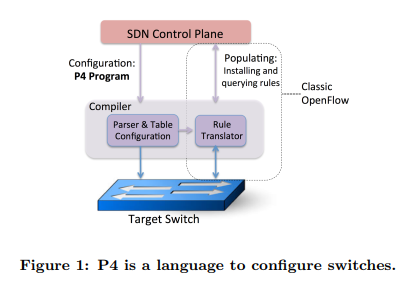
最近,芯片设计证明这样的灵活性可以通过传统的ASICs以Tb/s的速度实现。对这种新一代的交换机芯片实现编程并不容易。图1显示了P4(告知交换机如何配置交换机、处理数据包)和现在的APIs(用于在固定功能交换机上填充转发表)之间的关系。P4为可编程网络的概念提出抽象的级别,P4可以作为控制器和交换机之间的通常的接口。关键的挑战是找到一个“最佳位置”,以平衡表现力的需求与各种硬件和软件交换机的易于实施。
P4四个主要目标如下:
- 1.可重配性,控制器可以定义数据解析和处理的字段。
- 2.协议独立性,交换机不会限定于明确的数据包格式。相反,控制器可以配置,(1)数据包解析器可以以特别的名字和类型提取数据包头字段(ii)有匹配+动作表集合可以对这些数据包头进行处理。
- 3.目标独立性。这就类似C程序的运行不必关心底层的硬件。P4程序写好的配置不必关心底层设备,但是在将P4程序编写的配置,对交换机进行配置时,需要对交换机的能力进行考虑。
本文大纲如下。首先介绍交换机转发模型的概念,接下来,阐明用于描述协议独立数据包处理的新语言需求。然后提出一个简单的示例,示例中支持有新的数据包头字段以及在多个阶段对数据包进行处理。我们用这个示例探索P4程序如何配置头,数据包解析器,多个匹配+动作表,以及对这些表控制的控制流。最后,讨论编译器如何将P4映射到目标交换机。
2 抽象转发模型
图2显示了我们的抽象模型,交换机通过可编程解析器转发数据包,然后是多个匹配+动作阶段,按串行,并行或两者的组合排列。首先,OpenFlow假定的是固定的解析器,而我们的模型支持可编程解析器允许定义新的头字段。第二,OpenFlow假定match+action阶段是串行的,而我们的模型则可以并行的或者串行。第三,我们的模型假定,所有的动作由交换机支持的数据独立协议原语组成。
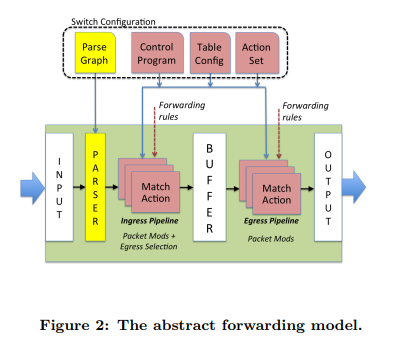
我们的概念模型总结了数据包如何通过不同的技术进行处理。这让我们设计了一个更通用的语言(P4)来体现数据包是如何通过抽象模型处理的。因此,程序员可以创建目标无关的程序,通过编译器映射到不同的转发设备。
转发模型由两种操作控制:配置和填充。配置操作编程解析器,设置匹配+动作阶段的顺序,并且配置每个阶段如何处理头字段。填充操作,在匹配+动作表中添加(删除)流表项,这个表在配置操作进行时,就配置好。填充确定在任何给定时间应用到数据包的策略。
为了本文的目的,我们假定配置和填充是处于两个不同的阶段。交换机在配置阶段不需要处理数据包,但是,我们仍然希望,在重配、升级的时间里,仍然可以进行数据包处理。
首先是解析器对到来的数据包进行处理。数据包数据部分假定为分别缓存,并且不能够进行匹配。解析器从头部识别、解析出字段,并且因此定义交换机支持的协议。模型未对协议头的含义进行假定,仅仅是解析的表示(解析到的东西)定义了匹配+动作的集合。
接下来,解析出来的头字段通过匹配+动作表,匹配+动作表被分在进入和出去两部分之间,两者可能修改数据包头,进入的匹配+动作决定了出去的端口,以及决定了数据包放置的队列。基于进入口处理,数据包可能被转发、复制(组播或者控制平面)、丢弃,或者触发流控制。出口匹配+动作对每一个数据包头实例进行修改。动作表可以与流关联,以追踪帧到帧的数据状态。
数据包在多个阶段之间可以携带额外的信息(数据包处理时产生),我们将这些信息称之为元数据,可以类似数据包头字段那样被识别。元数据例子比如,进入端口、传输目的、和队列,时间戳可以用于数据包调度,有些数据(比如虚拟网标识符)在表与表之间传输是不会改变的。
排队原则的处理与现在的OpenFlow协议一样:一个动作映射一个数据包到一个队列,这个队列配置为接收特殊服务规则。服务规则作为交换机配置的一部分。通过添加动作原语可以允许程序员实现新的或者现存的拥塞控制协议。
3 可编程语言
我们使用抽象的转发模型来表达交换机是如何配置以及处理数据包的。TTL字段必须减小并且测试,隧道头字段可能需要添加,总和可能需要计算,这促使P4使用指令控制流编程来表述头字段的处理(通过声明的头类型和原语动作集合)。
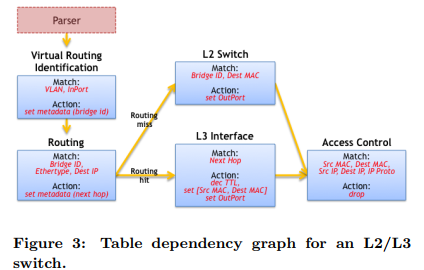
数据包处理语言必须能够让开发者表达在头字段之间的(明确的或隐式的)依赖关系,依赖关系决定了数据包在;哪些表中可以并行运行。比如,由于在IP路由表和ARP表之间的依赖关系,顺序执行要求一个IP路由表和一个ARP表。依赖关系可以通过分析TDGs(依赖关系表)进行识别。这些图表(TDGs)描述了字段的输入,动作,表之间的控制流。图3显示了L2/L3层交换机之间的依赖图例子。TDG节点直接映射动作表和在管道的依赖分析识别。不幸的是,TDGs对大多数程序员来说是不可取的,因为他们趋向于认为使用命令构建而不是图表表达数据包处理算法。
这促使我们提出两步编译处理。在最高级别层,编程人员使用命令语言表达数据包处理程序来代表控制流(P4),这种情况下,编译器将P4语言表示部分翻译到TDG上,进行依赖关系分析,接着匹配TDG到具体的目标交换机。P4的设计是为了更方便的将一个P4程序翻译到TDG上
4 P4语言举例
我们通过深度研究一些例子以探索P4。在核心和边缘的网络部署是有区别的。终端主机直接与边缘设备相连,边缘设备再通过高带宽的核心进行互连。所有的协议都是设计以支持这个结构(比如MPLS,PortLand),目的是简化核心部分的转发。
考虑使用top-of-rack(ToR)交换机通过两层核心连接部署2级网络。我们假设终端主机的数量不断增长,L2核心交换机不断溢出。MPLS是简化核心的一个选项,但是使用多个标签进行实现分发控制协议是艰难的任务。PortLand协议看起来很有趣,但是需要重写MAC地址,可能会破坏现有的网络调试工具,并且需要新的代理来response请求。
P4让我们能够使用传统的解决方法,并且对现在的网络架构只需做微小的改变。我们将用于学习的样例称之为mTag(可以认为是一种机制,用来P4进行描述):它结合了携带简单MPLS类似的标签的PortLand多级路由协议。通过核心的路由由32bit的标签编码而成,一个32bit的标签由四个单字节的字段组成。32bit的标签可以携带源路由或者目的定位信息(比如PortLand的PseudoMac)。每个核心交换机只要检测标签的一个bit并且检验信息。我们的例子中,标签是通过 第一个ToR交换机添加的,尽管,这同样会在终端机NIC上进行添加。mTag的例子是为了将我们的注意放在P4语言上。在实践中,P4程序对于整个交换机来说会更加复杂。
4.1 P4概念
P4程序的定义包含以下组件的定义:
- 1.首部Headers:首部的定义描述了一系列首部区域的顺序和结构。它包含区域长度的规范,约束了区域数据的取值。
- 2.解析器Parsers:解析器的定义描述了如何识别数据包内的首部和有效的首部顺序。
- 3.表Tables:“匹配–动作”表是执行数据包处理的机制。P4程序定义的首部区域可能会用于匹配,或者在其上执行特定的动作。
- 4.动作Actions:P4支持通过更简单的协议无关的原语构造复杂的执行动作。这些复杂的动作可以在“匹配 – 动作”表中使用。
- 5.控制程序Control Programs:控制程序决定了“匹配 – 动作”表处理数据包的顺序。一个简单又必要的程序描述了“匹配 – 动作”表之间的控制流。
接下来,我们将展示,在P4中,这些组件是如何帮助的mTag实现理想的处理器。
4.2 首部格式
从首部格式的规范开始设计。通常,每一个头部的配置是通过声明字段名字和宽度的集合组成。可选的字段声明允许我们对不同大小的字段约束值的范围和最大长度。比如,标准以太网和VLAN的头配置如下所示:
header ethernet {
fields {
dst_addr: 48; // width in bits
src_addr: 48;
ethertype: 16;
}
}
header vlan {
fields {
pcp: 3;
cfi: 1;
vid: 12;
ethertype: 16;
}
}
mTag首部可以不修改现有的声明而进行添加。字段名表名核心层有两层汇聚。每一个核心交换机都被编写了一些规则来检查这些字节中的某一个。具体检查哪一个字节,是由字节在交换机所处层次位置和数据流的方向(上或下)决定的。
header mTag {
fields {
up1: 8;
up2: 8;
down1: 8;
down2: 8;
ethertype: 16;
}
}
4.3 数据包解析器
P4假设底层交换机可以实现一个状态机,这个状态机能够自头至尾横贯数据包的各个首部,随着状态机的行进提取首部区域的值。提取出来的首部区域值被送入“匹配–动作”表进行处理。P4把状态机直接描述成从一个首部到下一个首部的过渡转移的集合。每一个过渡转移可能会被当前首部中的值触发。
parser start {
ethernet;
}
parser ethernet {
switch (ethertype) {
case 0x8100:
vlan;
case 0x9100:
vlan;
case 0x800:
ipv4;
// Other cases
}
}
parser vlan {
switch (ethertype) {
case 0xaaaa:
mTag;
case 0x800:
ipv4;
// Other cases
}
}
parser mTag {
switch (ethertype) {
case 0x800:
ipv4;
// Other cases
}
}
数据包的解析从start状态开始,一直行进直到到达了明确的stop状态或是遭遇到无法处理的情况(这可能被标记成错误)。在到达了对应下一个首部的状态时,状态机根据首部的规范描述提取出首部,然后根据状态机的下一个过渡转移继续向前行进。提取出来的首部被送往交换机流水线后半部分的“匹配+动作”的处理过程。
4.4 表的规范
接下来,开发者需要描述定义首部区域(字段)如何在“匹配– 动作”阶段进行匹配(比如它们应该被精确匹配,范围匹配还是通配符匹配),以及当成功匹配之后将执行什么动作。
在我们简单的mTag例子中,边缘交换机匹配二层目的地和VLAN ID,然后选择一个mTag添加到首部中。开发者定义一张表来匹配这些区域(字段),以及执行一个添加mTag首部的动作(见后文)。其中的reads属性声明了要匹配哪些首部区域(字段),同时限定了匹配类型(精确匹配、三重匹配等)。actions属性列出了“匹配–动作”表可能会对数据包执行的动作。动作将会在本文后续部分讲解。max_size属性指明了“匹配–动作”表需要能够支持多少条表项。
表的规范允许P4编译器决定存储表需要多大的存储空间,以及在什么样的存储器(比如TCAM或SRAM)上实现这个表。
table mTag_table {
reads {
ethernet.dst_addr: exact;
vlan.vid: exact;
}
actions {
// At runtime, entries are programmed with params
// for the mTag action. See below.
add_mTag;
}
max_size: 20000;
}
为了展示的完整性和后续讨论的便利,我们在此展示其他表的简短定义,这些表将在控制程序一节中引用。
table source_check {
// Verify mtag only on ports to the core
reads {
mtag: valid; // Was mtag parsed? metadata.ingress_port: exact;
}
actions { // Each table entry specifies *one* action
// If inappropriate mTag, send to CPU
fault_to_cpu;
// If mtag found, strip and record in metadata
//剥离和记录元数据
strip_mtag;
// Otherwise, allow the packet to continue
pass;
}
max_size: 64; // One rule per port
}
table local_switching {
// Reads destination and checks if local
// If miss occurs, goto mtag table.
}
table egress_check {
// Verify egress is resolved
// Do not retag packets received with tag
// Reads egress and whether packet was mTagged
}
4.5 动作规范
P4定义了一个基本动作的集合,可以利用它们构造复杂的动作。每个P4程序都声明了一个动作功能的集合,动作功能由动作原语编写而成;这些动作功能简化了表的规范和下发。P4假设一个动作功能中的原语是并行执行的。(没有并行执行能力的交换设备可能会模拟并行的过程。)
适用于上述的add_mTag动作的实现如下:
action add_mTag(up1, up2, down1, down2, egr_spec) {
add_header(mTag);
// Copy VLAN ethertype to mTag
copy_field(mTag.ethertype, vlan.ethertype);
// Set VLAN’s ethertype to signal mTag
set_field(vlan.ethertype, 0xaaaa);
set_field(mTag.up1, up1);
set_field(mTag.up2, up2);
set_field(mTag.down1, down1);
set_field(mTag.down2, down2);
// Set the destination egress port as well
set_field(metadata.egress_spec, egr_spec);
}
如果某个动作需要有输入参数(例如mTag中的up1值),参数将会在运行时由匹配表提供。
在这个例子中,交换机将mTag标签插入在VLAN标签之后,复制VLAN标签的Ethertype字段到mTag中,以指明后续类型为mTag,然后设置VLAN标签的Ethertype字段为0xaaaa,表明其后跟随的是mTag标签。在边缘交换机上执行的相反动作没有展示出来,这些动作将会从数据包中剥去mTag标签。
P4的基本动作包括:
1.Set_field:将首部中的某一特定区域设置为特定的值,支持带掩码的设置;
2.Copy_field:将一个首部区域的值拷贝到另一首部区域中;
3.Add_header:添加一个有效的特定的首部(以及它所有的首部区域);
4.Remove_header:从数据包中删除(pop取出)一个首部(以及它所有的首部区域);
5.Increment:递增或递减一个首部区域的值;
6.Checksum:计算首部区域的一些集合的校验和(比如IPv4校验和)。
我们期望大多数交换设备上的实现将会约束动作的处理,只允许与特定的数据包格式相一致的首部进行修改操作。
4.6 控制程序
一旦表和动作被定义好,接下来仅剩的任务就是指定从一个表转移到下一个表的控制流。控制流作为一个程序通过一个函数、条件和表的引用组成的集合进行指定。
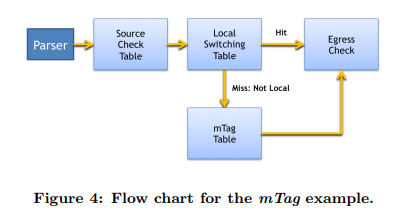
图4-1为边缘交换机上的mTag实现展示了一个期望的控制流的图形化表示。在包解析之后,source_check表确认接收到的数据包和入端口是否一致。例如,mTag只应该存在于连接到核心交换机的端口上。source_check也会从数据包中剥去mTag标签,同时在元数据中记录数据包是否拥有mTag标签。流水线中后续的表可能会匹配这个元数据以避免再次往数据包中添加标签。
local_switching表稍后将会被运行。如果没有匹配上,就意味着这个数据包的目的地不是连接在同一个交换机上的主机。在这种情况下,mTag_table表(上述定义的)将会用来匹配这个数据包。本地和送往核心层的转发控制都可以被egress_check表处理。这个表将会在转发目的地未知的情况下,上送一个通知到SDN控制层。
这一包处理流水线的必要描述如下:
control main() {
// Verify mTag state and port are consistent
//验证mTag 是否合法,端口与连接到核心交换机的端口是否一致。
table(source_check);
// If no error from source_check, continue
if (!defined(metadata.ingress_error)) {
// Attempt to switch to end hosts
table(local_switching);
if (!defined(metadata.egress_spec)) {
// Not a known local host; try mtagging
table(mTag_table);
}
// Check for unknown egress state or
// bad retagging with mTag.
table(egress_check);
}
}
5 编译P4程序
为了让网络能够实现我们的P4程序,我们需要编译器来把目标无关的描述映射到目标交换机的特定硬件或软件平台上。完成这个工作涉及分配目标的资源并且为设备生成合适的配置。
5.1 编译包解析器
对于有可编程包解析器的设备,编译器将解析器描述翻译成解析状态机。对于固定的解析器,编译器仅仅确认解析器描述与目标设备的解析器是一致的。生成一个状态机的细节和有关状态表项的细节,可以在[16]中找到。
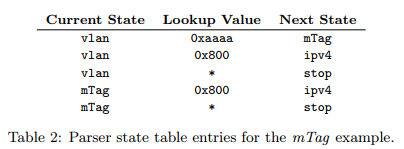
表2展示了上述解析器中vlan和mTag部分的状态表项。每一条表项指明了当前的状态、用于匹配的区域的值以及即将跳转的下一状态。为了展示的简洁性,其他行被忽略。
5.2 编译控制程序
§4.6中必要的控制流描述是一种方便的指定交换机的逻辑转发行为的方法,但它不能明确地表示出表之间的依赖和并发执行的机会。因此我们部署一个编译器来分析控制程序,帮助我们识别依赖以及寻找能够并发处理首部区域的机会。最终,编译器为交换设备生成目标配置。目标设备有很多种可能,例如软件交换机[17]、多核软件交换机[18]、NPU[19]、固定功能的交换机[20],或是可重配置的匹配表(RMT)流水线[2]。
P4: Programming Protocol-Independent Packet Processors的更多相关文章
- DC.p4: programming the forwarding plane of a data-center switch
Name of article:Dc. p4: Programming the forwarding plane of a data-center switch Origin of the artic ...
- Programming Protocol-Independent Packet Processors
引言 OpenFlow协议固定的包头域数目,使得南向协议过于死板. P4可以实现自定义包头,增加灵活性. P4是OpenFlow未来发展的方向. We propose P4 as a strawman ...
- SDN 编程语言 p4(SDN programming language P4)
行业趋势,SND是未来. P4 是未来. SDN is inevitably, and P4 is inevitably. P4 = Programming Protocol-Independent ...
- 2017年P4中国峰会北京站 会议小结
2017 P4 中国峰会 北京 本次会议依然侧重介绍P4,并highlight P4的benifit,大致分为以下几类: 1.学术界 - 未来网络的发展,为何提出P4技术? 未来网络和实体经济.其他学 ...
- P4论文粗读笔记(一)
一 文章名称:SNAP: Stateful Network-Wide Abstractions for Packet Processing 数据包处理的带状态网络概念 发表时间:2016 期刊来源:S ...
- Fast Packet Processing - A Survey
笔记是边读边写的旁注,比较乱,没有整理就丢上来了. 可以说不仅要说fast packet process servey,也同时是一篇packet process的综述了.packet processi ...
- The P4 Language Specification v1.0.2 Introduction部分
Introduction P4 is a declarative language for expressing how packets are processed by the pipeline o ...
- 阅读 用P4对数据平面进行编程
引言 关于题目,对数据平面进行编程,在之前读过the road to SDN,软件定义网络的思想在于数控分离,其对网络行为的编程暂时只局限于网络控制平面.其转发平面在很大程度上受制于功能固定的包处理硬 ...
- P4简介:数据平面的编程语言
15-05-29 http://p4.org/join-us/ 由两位SDN大师----来自普林斯顿的Jennifer Rexford和斯坦福的Nick McKeown---- 共同 ...
随机推荐
- OO第一次总结作业
第一次OO博客作业 前言 面向对象课程已经经过了4周的时间.前三次作业全部是关于多项式求导的相关内容,内容由易到难,同时我也开始逐渐深入感受学习面向对象的各项特征,逐渐将自己的编程风格从C向真正的面向 ...
- django中间件-12
目录 自定义中间件 函数定义 类定义 中间件的执行顺序 在django中,中间件其实就是一个类,他是一个可以介入django的 request 和 response 的钩子框架,在请求响应不同的阶段, ...
- 乘积尾零——第九届蓝桥杯C语言B组(省赛)第三题
原创 标题:乘积尾零 如下的10行数据,每行有10个整数,请你求出它们的乘积的末尾有多少个零? 5650 4542 3554 473 946 4114 3871 9073 90 4329 2758 7 ...
- 在Visual Studio 2012中使用ASP.NET MVC5
去年11月,.NET团队发布了用于 Visual Studio 2012 的 ASP.NET 和 Web 工具 2013.1 您可以从下面提供的链接下载该更新: 下载用于 Visual Studio ...
- 「PKUSC2018」最大前缀和
题面 题解 可以想到枚举成为最大前缀和的一部分的数 设\(sum_i=\sum\limits_{j\in i}a[j]\) 设\(f_i\)表示满足\(i\)的最大前缀和等于\(sum_i\)的方案数 ...
- Linux 和 Windows 之间共享文件之 samba
导语 如果对windows有过实际操作技巧的人都会明白,在windows下的文件共享加上网络驱动器映射是多么方便的体验,甚至比ftp更加的简单,就像本地多了一块可与他人交流的硬盘一样. 问题 由于性能 ...
- Python标准库学习之zipfile模块
ZipFile模块里有两个非常重要的class, 分别是 ZipFile和ZipInfo. ZipFile是主要的类,用来创建和读取zip文件,而ZipInfo是存储的zip文件的每个文件的信息的. ...
- 【轮子狂魔】手把手教你自造Redis Client
为什么做Redis Client? Redis Client顾名思义,redis的客户端,主要是封装了一些对于Redis的操作. 而目前用的比较广泛的 ServiceStack.Redis 不学好,居 ...
- Charles 抓包使用教程
将 Charles 设置成系统代理 Charles 主界面介绍 过滤网络请求 截取 iPhone 上的网络封包 截取 Https 通讯信息 模拟慢速网络 修改网络请求内容 给服务器做压力测试 修改服务 ...
- [学习笔记]SiftGPU入门
当有读者看到我这篇SiftGPU入门的学习笔记时,相信你已经读过了高博那篇<SLAM拾萃:SiftGPU>,那篇文章写于16年,已经过去两年的时间.在我尝试配置SiftGPU的环境时,遇到 ...