Jsoup代码示例、解析网页+提取文本
使用Jsoup解析HTML
那么我们就必须用到HttpClient先获取到html
同样我们引入HttpClient相关jar包
以及commonIO的jar包
我们把httpClient的基本代码写上,然后解析网页 得到文档对象
我们获取title和制定id的文档对象
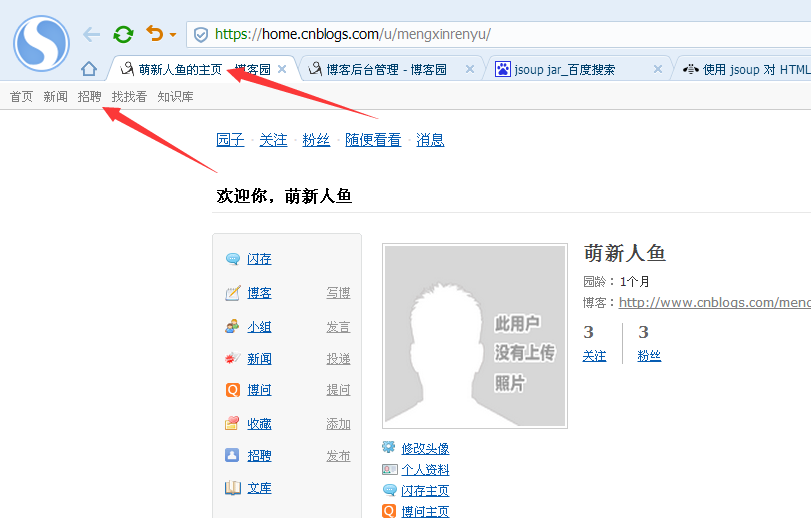
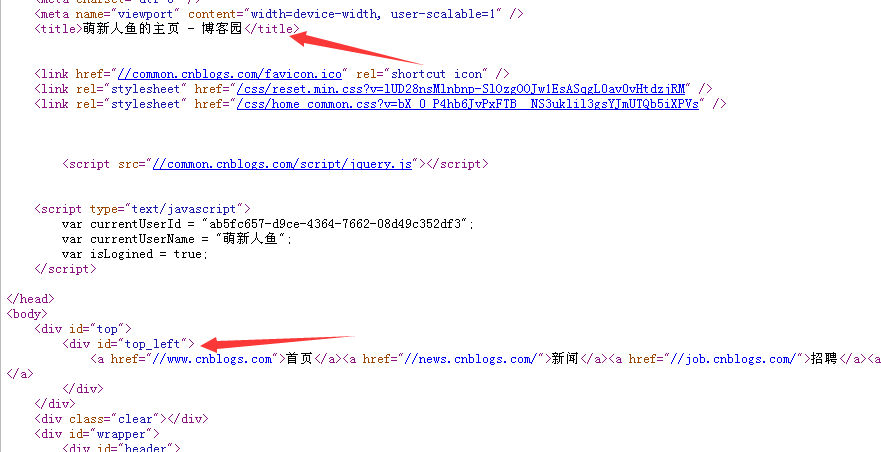
代码实例:
package com.zhi.jsoup1; import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://home.cnblogs.com/u/mengxinrenyu/"); //2、创建实例 httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0"); CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close(); Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title); element=doc.getElementById("top_left"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
由于网页我是登陆以后的,所以会出现以下错误
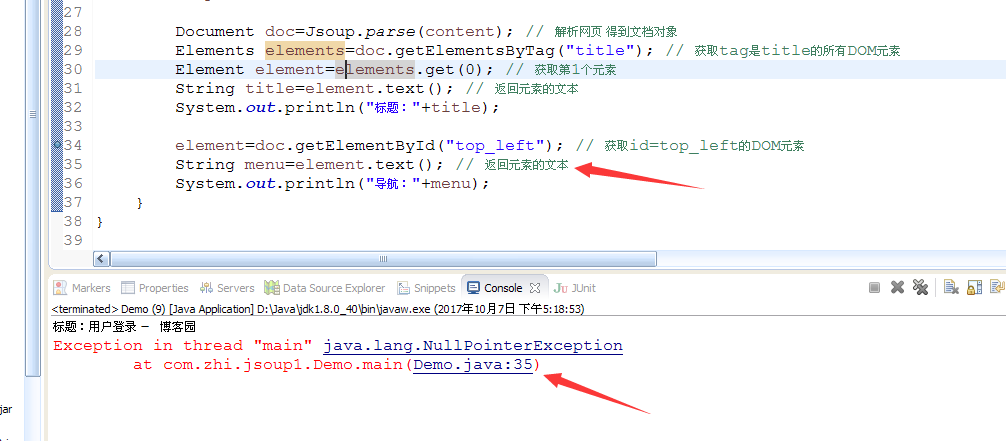
因为请求的是某个登陆账户下的网页,所以网页会提示登录。从没没有相应id的元素,返回NPE。
我们换一个新闻页面试一下

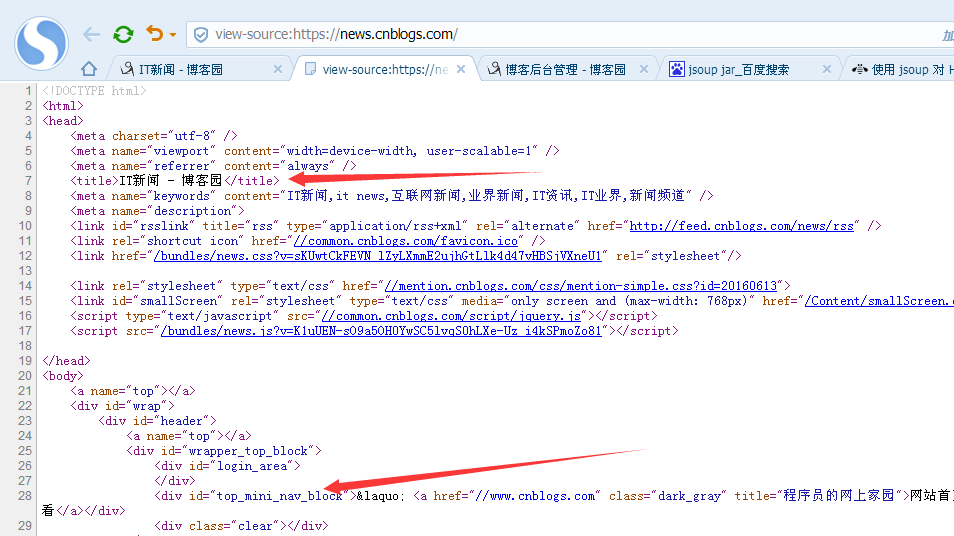
代码示例:
public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://news.cnblogs.com/"); //2、创建实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0");
CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close();
Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title);
element=doc.getElementById("top_mini_nav_block"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
运行如图:
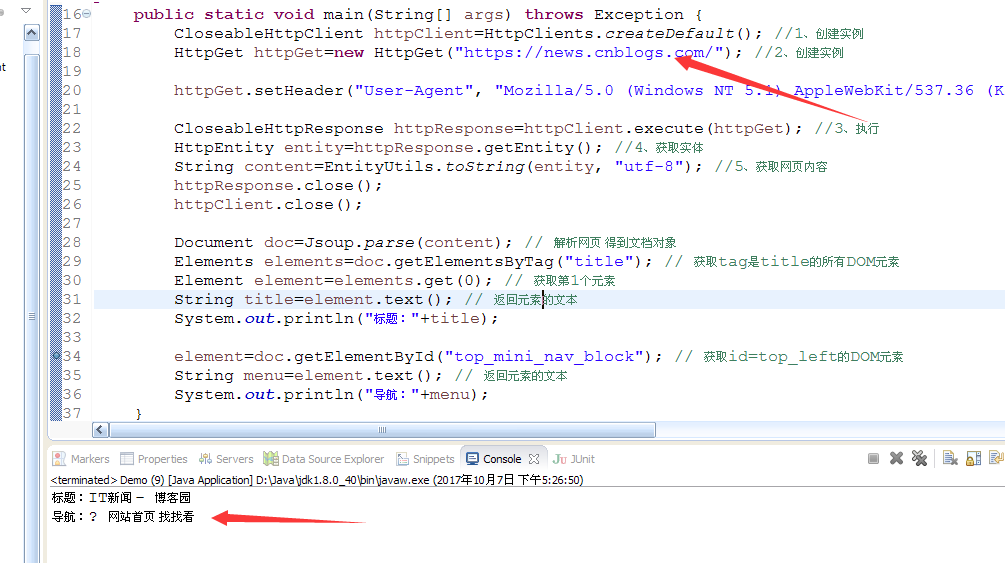
Jsoup代码示例、解析网页+提取文本的更多相关文章
- 使用java开源工具httpClient及jsoup抓取解析网页数据
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下 公历时间:2016年04月11日 星期一 农历时间:猴年三月初五 天干地支:丙申年 壬辰月 癸亥日 宜:求子 祈福 开光 ...
- 使用Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)(转)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- Python中的HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies(二)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过 Python语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- 【python】使用HTMLParser、cookielib抓取和解析网页、从HTML文档中提取链接、图像、文本、Cookies
一.从HTML文档中提取链接 模块HTMLParser,该模块使我们能够根据HTML文档中的标签来简洁.高效地解析HTML文档. 处理HTML文档的时候,我们常常需要从其中提取出所有的链接.使用HTM ...
- Jsoup解析网页源码时常用的Element(s)类
Jsoup解析网页源码时常用的Element(s)类 一.简介 该类是Node的直接子类,同样实现了可克隆接口.类声明:public class Element extends Node 它表示由一个 ...
- Jsoup解析网页html
Jsoup解析网页html 解析网页demo: 利用Jsoup获取截图中的数据信息: html代码片段: <!-- 当前基金档案\计算\定投\开户 start --> <div cl ...
- [译]使用BeautifulSoup和Python从网页中提取文本
如果您要花时间浏览网页,您可能遇到的一项任务就是从HTML中删除可见的文本内容. 如果您使用的是Python,我们可以使用BeautifulSoup来完成此任务. 设置提取 首先,我们需要获取一些HT ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- Jsoup提取文本时保留标签
使用Jsoup来对html进行处理比较方便,你可能会用它来提取文本或清理html标签.如果你想提取文本时保留标签,可以使用Jsoup.clean方法,参数为html及标签白名单: Jsoup.clea ...
随机推荐
- 安全运维 - Windows系统攻击回溯
Windows应急事件 病毒.木马.蠕虫 Web服务器入侵事件或第三方服务入侵事件 系统入侵事件 网络攻击事件(DDOS.ARP.DNS劫持等) 通用排查思路 获知异常事件基本情况 发现主机异常现象的 ...
- c# 对象相等性和同一性
一:对象相等性和同一性 System.Object提供了名为Equals的虚方法,作用是在两个对象包含相同值的前提下返回true,内部实现 public class Object { public v ...
- PTA第二题
#include<string.h> #include<stdio.h> #include<malloc.h> ]; ][]={"ling",& ...
- [Codeforces 1208D]Restore Permutation (树状数组)
[Codeforces 1208D]Restore Permutation (树状数组) 题面 有一个长度为n的排列a.对于每个元素i,\(s_i\)表示\(\sum_{j=1,a_j<a_i} ...
- 如何在CentOS 7上安装newman
前提:先安装nodejs,详见:如何在CentOS 7上安装Node.js和npm #sudo npm install -g newman 结果: /usr/local/bin/newman -> ...
- SQL 中的正则函数
ORACLE中支持正则表达式的函数主要有下面四个: 1,REGEXP_LIKE :与LIKE的功能相似,比LIKE强大得多. 2,REGEXP_INSTR :与INSTR的功能相似. 3,REGEXP ...
- Nhbernate
一.ORM1.对象关系映射(Object Relational Mapping,简称ORM)是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术.2.ORM是通过使用描述对象和数据库之间映射的 ...
- VISTA Enhancer Browser
微信公众号:生物信息学起步如果觉得对你有帮助,欢迎关注/转发/分享[1] 内容目录 1.目的2.实验数据2.1 候选增强子识别2.2 转基因小鼠分析2.3 注释3.搜索数据库3.1 概括3.2 高级搜 ...
- 二gradle创建SSM项目——Hello word
一创建gradle web项目 1.以下是我的项目结构web工程+工具module,mapper用来存放mybatis-plus自动生成类,通过 MpGenerator.class 生成. 项目结 ...
- IO流详解及测试代码
IO流 (1)IO用于在设备间进行数据传输的操作 (2)分类: A:流向 输入流 读取数据 输出流 写出数据 B:数据类型 字节流 字节输入流 ...