一探究竟:善用 MaxCompute Studio 分析 SQL 作业
头疼的问题
MaxCompute 用户一个常见的问题是:同一个周期任务,为什么最近几天比之前慢了很多?或者为什么之前都能按时产出的作业最近经常破线?
通常来说,引起作业执行变慢的原因有:quota 组资源不足、输入数据量变动、数据分布情况变动、平台硬件故障引发重跑等。本文主要针对数据变动引起的作业慢问题,介绍用户如何通过 MaxCompute Studio 的作业执行图及作业详情功能来自助定位问题。
MaxCompute Studio 登场
我们举个例子来说。 下面是同一个任务分别在5月7日,5月9日的执行情况,下面分别称为作业一、作业二:
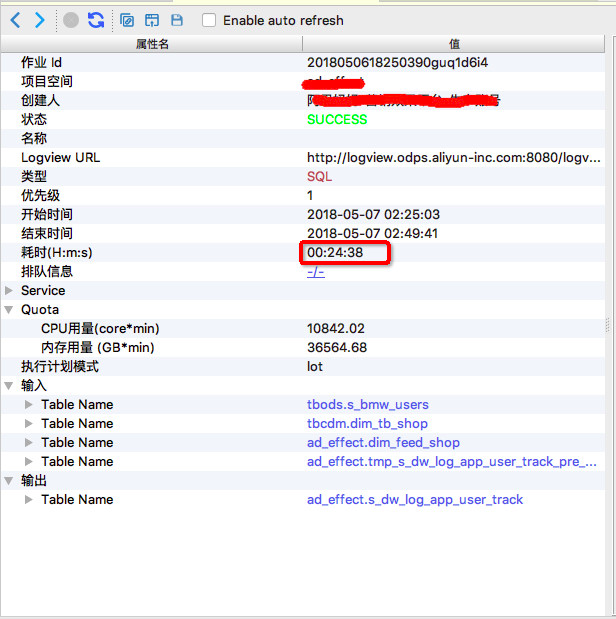
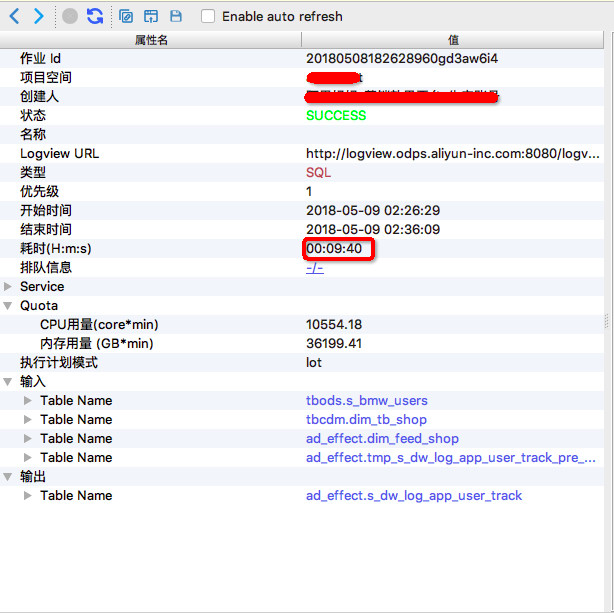
先来,对比下 SQL 和执行计划
通常来说,进行两次执行对比前,要先对比一下两次执行的 SQL 脚本是否相同,如果在这之间用户改动过作业脚本,就需要先分析改动的部分造成的影响。如果脚本内容一致,随后还需要比较执行计划是否一致,可以通过 MaxCompute Studio 的作业执行计划图功能来分析(参看文档),可视化地看看两次执行的计划图长得一样不一样。 (作业对比的功能正在开发中,下个版本的 Studio 中就可以一键对比两个作业,标注出 SQL 脚本及其它部分的不同之处啦,敬请期待)
在上面这个例子中两个作业的 SQL 脚本及执行计划完全一致,出于数据安全考虑,此处不粘贴具体 SQL 的内容。
再来,对比数据量
第二步要看一下作业输入数据量有没有明显变化,有可能是某一天输入表或分区的数据量暴涨导致了作业执行变慢。作业输入数据在 Detail 页面左侧,那里列出了这个作业所有输入的数据表和最终输出的数据表。 展开 输入->Table Name 可以查看详细信息,包括是哪个 Fuxi 任务读取了这个表,读取了多少条记录以及读取的数据量大小。这些信息,也标注在作业执行计划图 graph 上,方便查看。如下图所示,
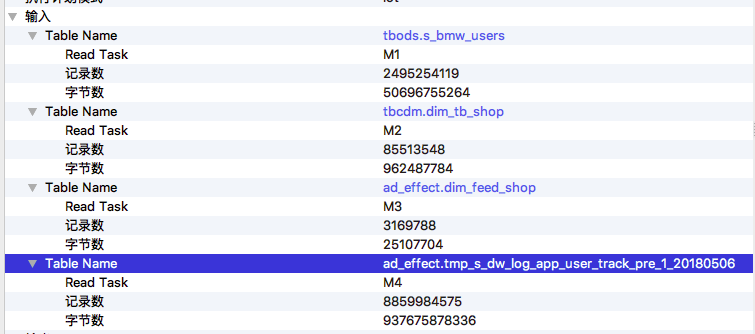
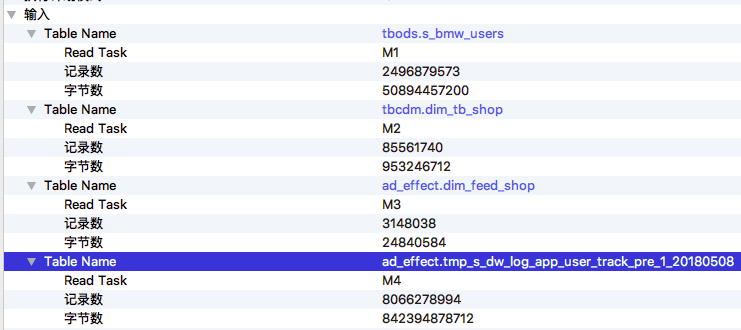
也可以从graph上直接读取输入行数或者字节数(默认展示行数,可在边上右键切换为字节数):
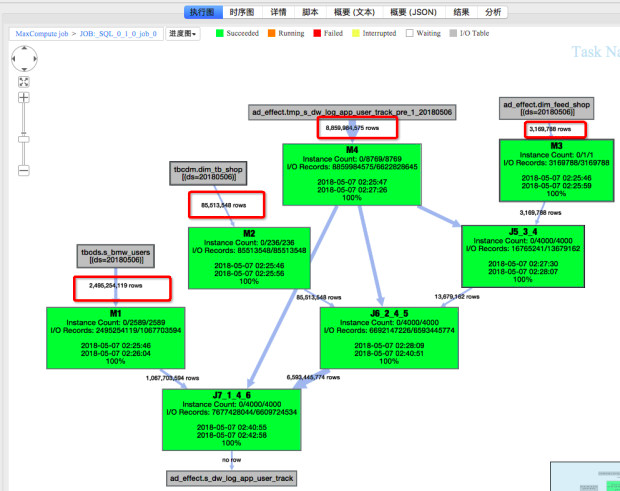

在这个例子中,从输入数据量来看,两次执行的输入数据量差别不大。
作业回放是把利器
第三步,那到底作业运行情况是怎样的呢?运行那么长时间,或花费在哪儿了呢?不急,快快使用作业回放!
在 Studio 中作业执行计划图底部提供的作业回放工具条,允许用户在 30 秒内快速回放作业执行进度的全过程!这样我们就可以迅速地了解到底是哪个 Task 耗时最多,或者处理得数据最多,或者输出的数据最多等等。
通过回放重现作业执行过程,Studio 提供进度图以及热度图方便从不同维度进行作业分析。
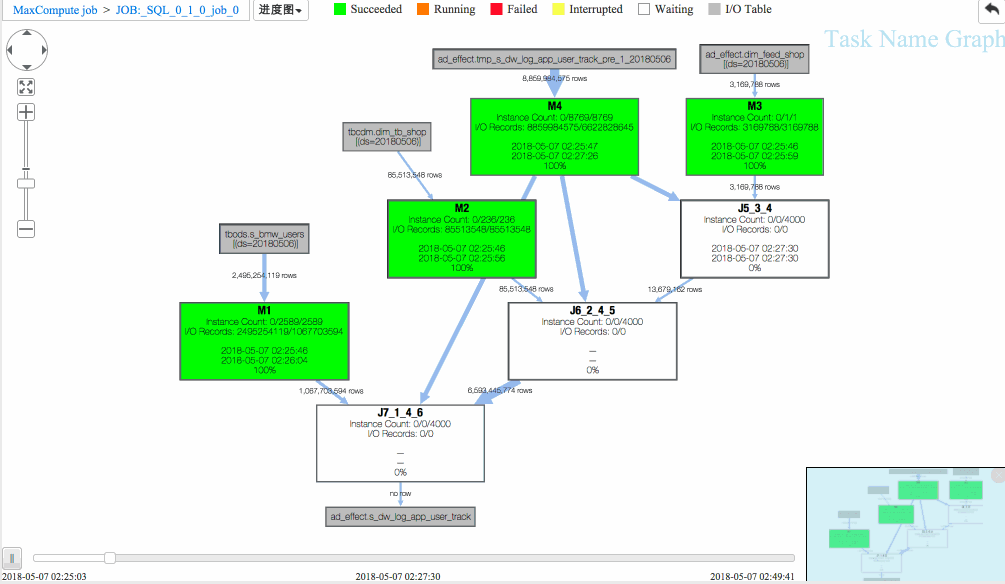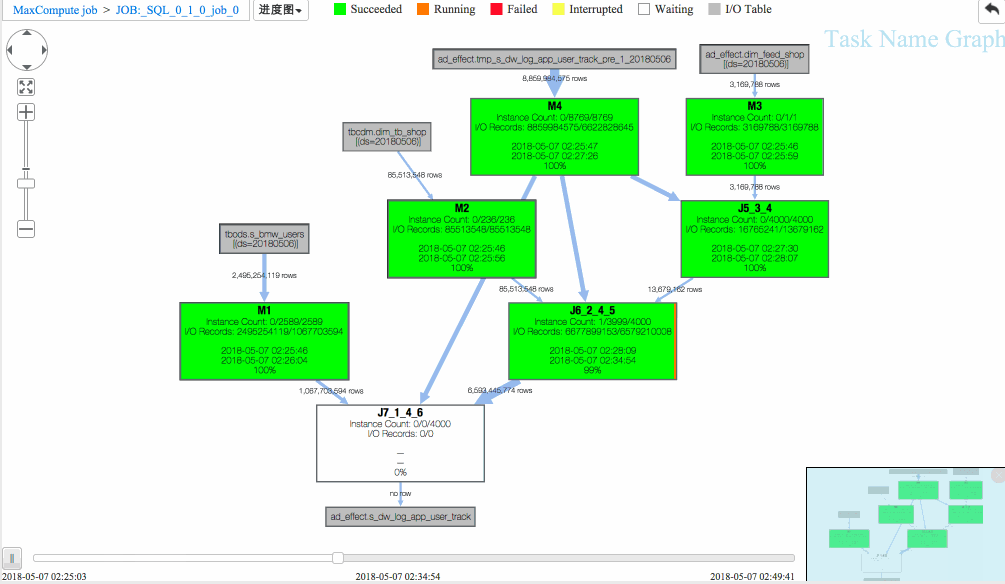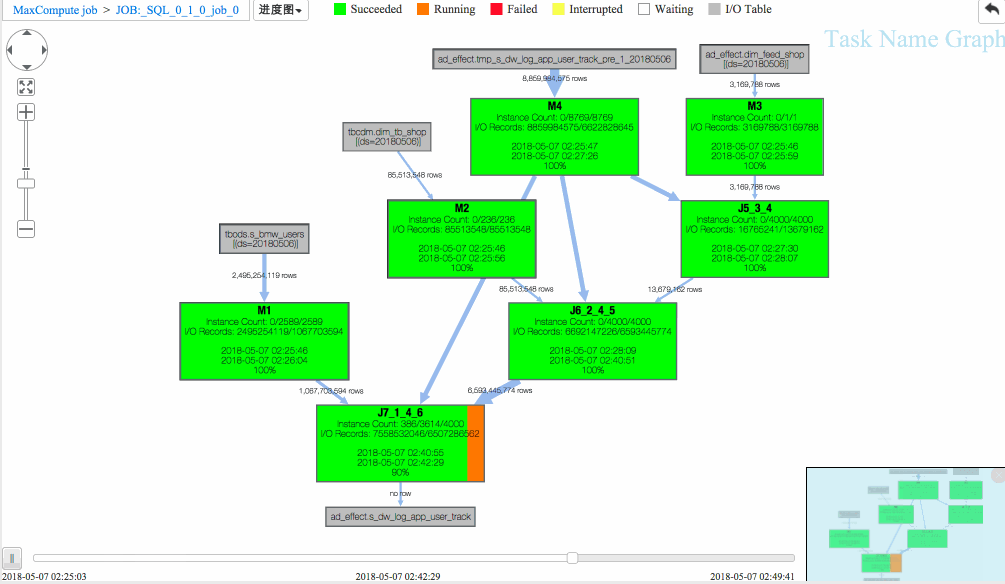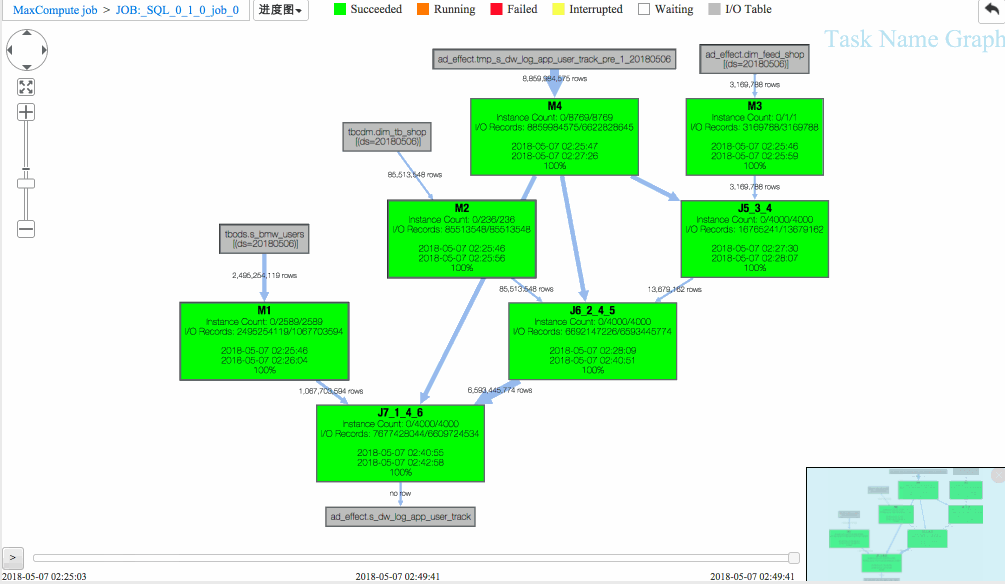
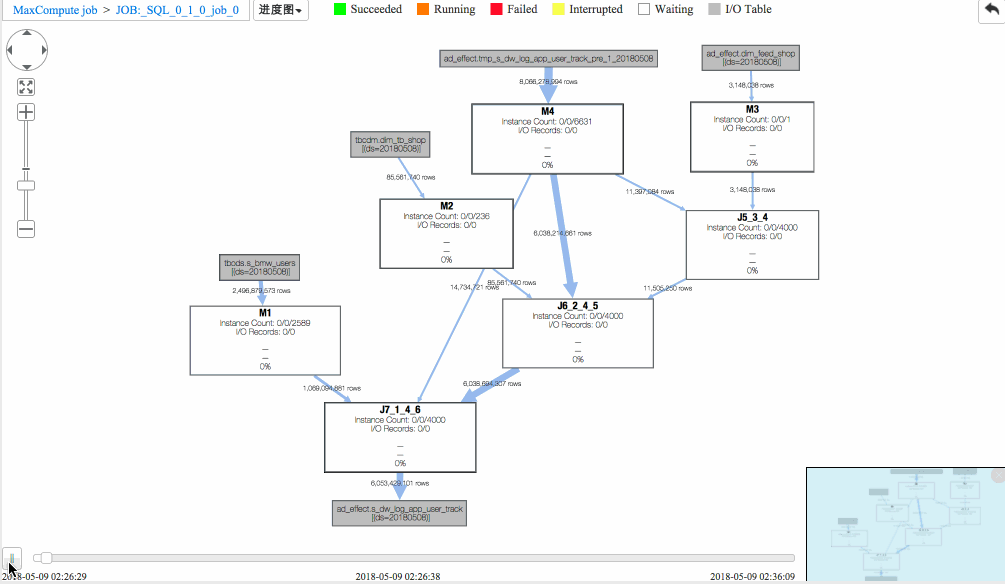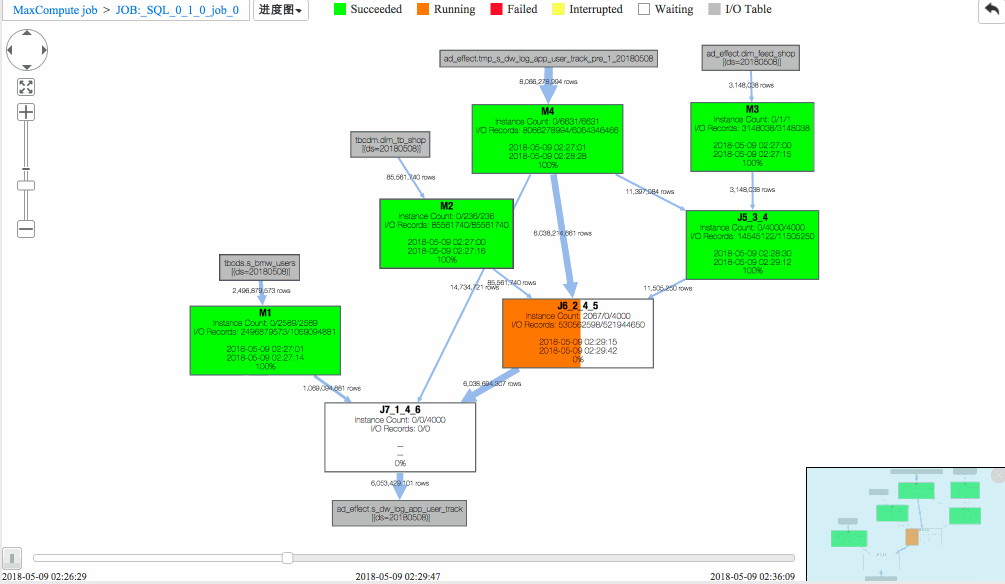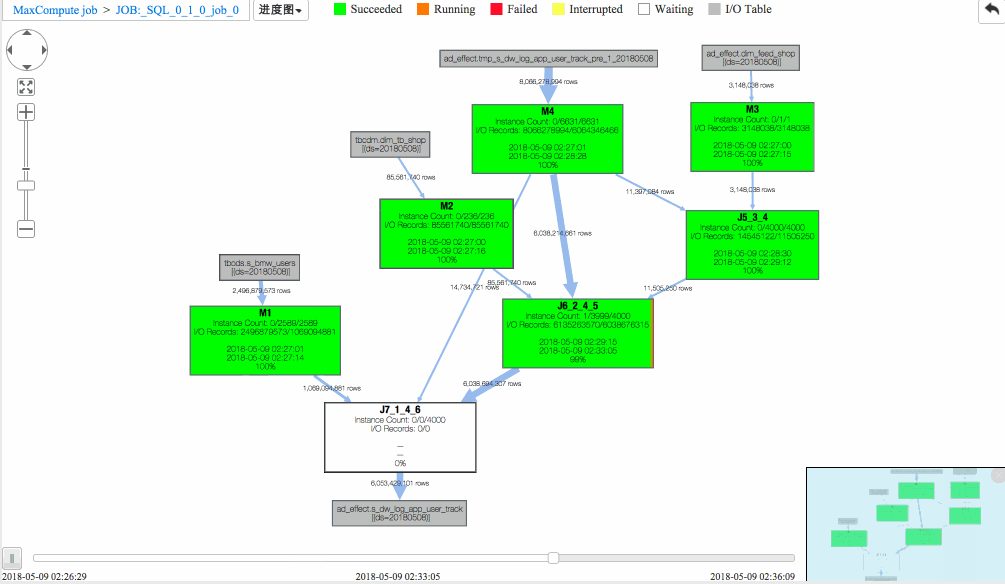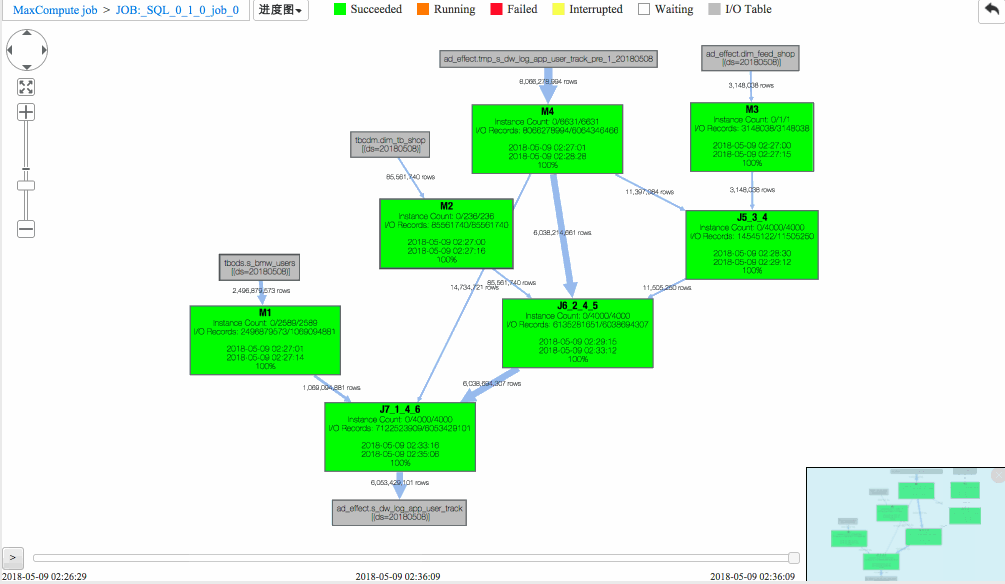
从回放中可以看出
(1)J6_2_4_5 task是整个作业瓶颈,时间消耗最多,从task热度图中也能发现该节点明显热于其它节点。(时间热度图上越红代表运行时间越长,数据热度图上越红代表处理数据越多)
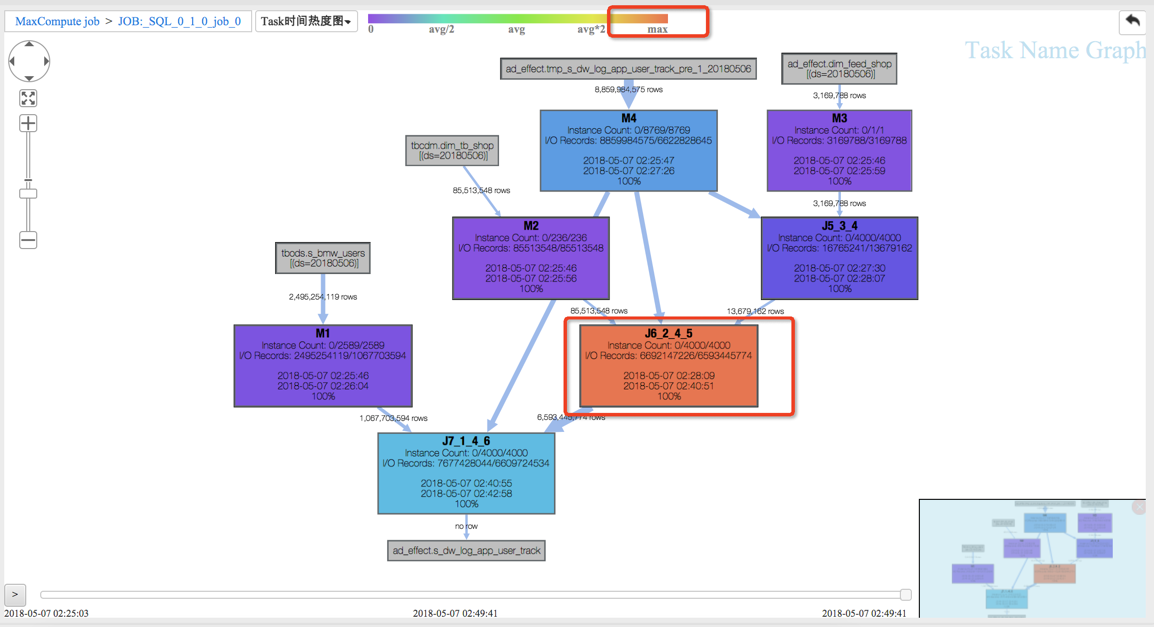
(2)同时对比两个作业的回放过程,能够比较明显地发现作业一在J6_2_4_5运行时长要大于作业二,说明作业一在J6_2_4_5阶段变慢了,初步怀疑有长尾节点产生。
接下来切换到时序图tab,比较两个作业的执行timeline:
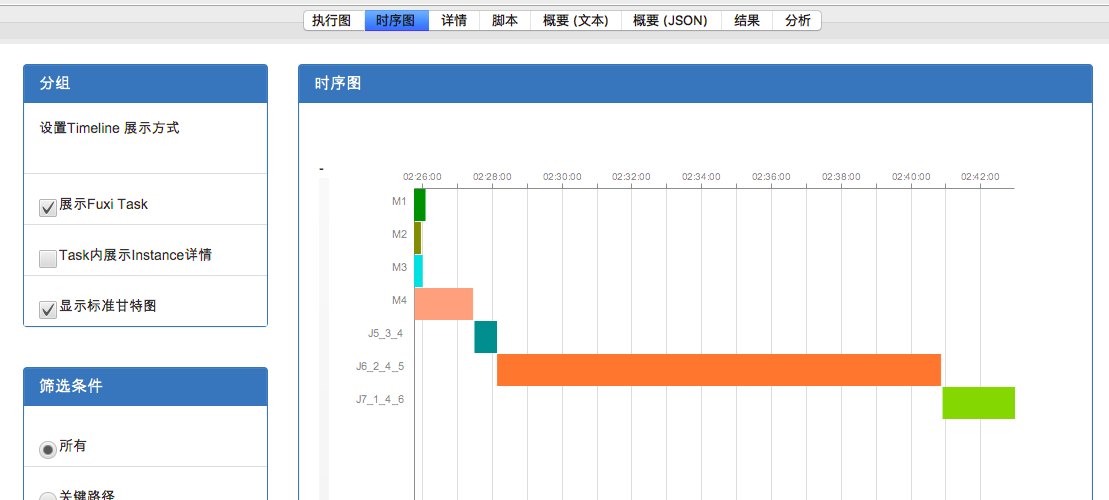
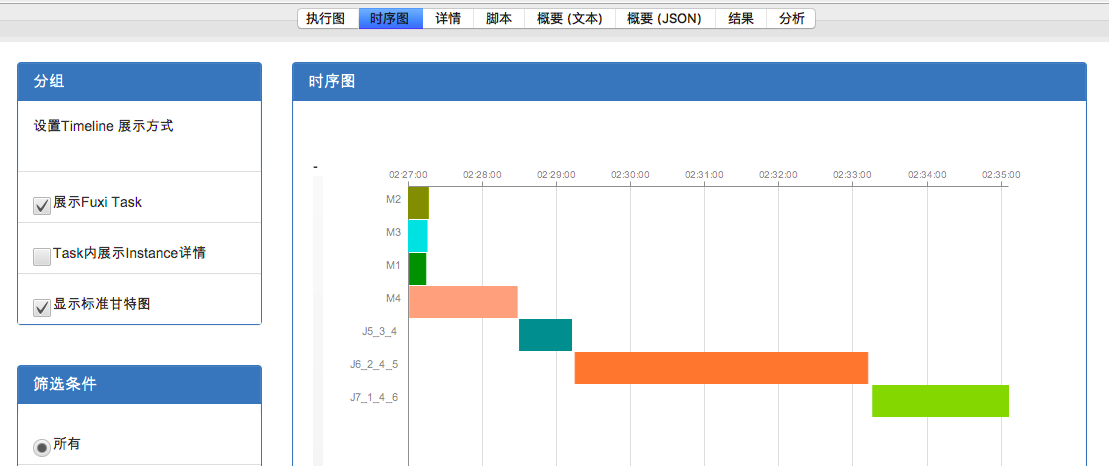
虽然两个作业timeline的时间尺度不同,但是可以明显看出,作业一中J6_2_4_5 占了更长的比例,由此可以断定是J6_2_4_5 在05-07执行(也就是作业一)发生可能长尾,导致整个作业执行变慢。
进入深水区
第四步,通过graph或detail tab 对比J6_2_4_5 的输入数据量
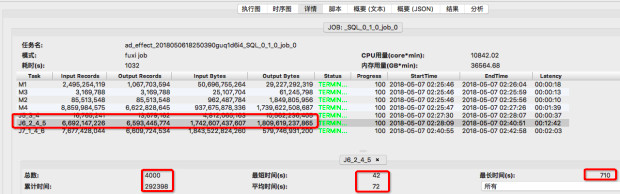
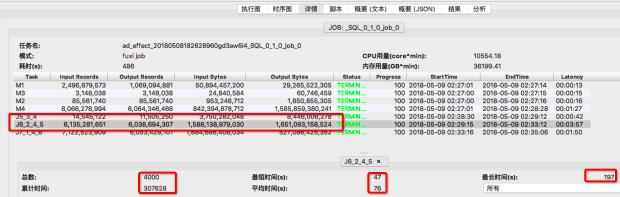
关注上图中J6_2_4_5 输入数据量和统计信息,通过比较可看出,两次执行的J6_2_4_5 输入数据量基本相同,1.58万亿字节 vs 1.7万亿字节,从统计信息来看,累计执行时间及平均时间也基本相同:292398 vs 307628, 72s vs 76s 但作业一 fuxi instances中的最长执行时间为710s, 由此可以认定是某几个fuxi instance长尾导致了J6_2_4_5 这个fuxi task的长尾。
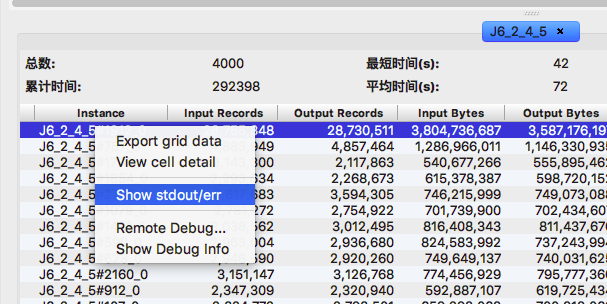
第五步,对两个 J6_2_4_5 fuxi instance 列表按照latency 排序:


或者转到分析tab下的长尾页面查找长尾节点:注意这个图中的比例尺是以等比而不是等差方式标定的,因此,上面突出的比较长的毛刺就很可能是长尾的实例了。可以通过浮动窗口中的具体信息来判断。 另外 Studio 也提供了诊断的页面,来自动找出超过平均实例执行时间两倍的长尾实例。
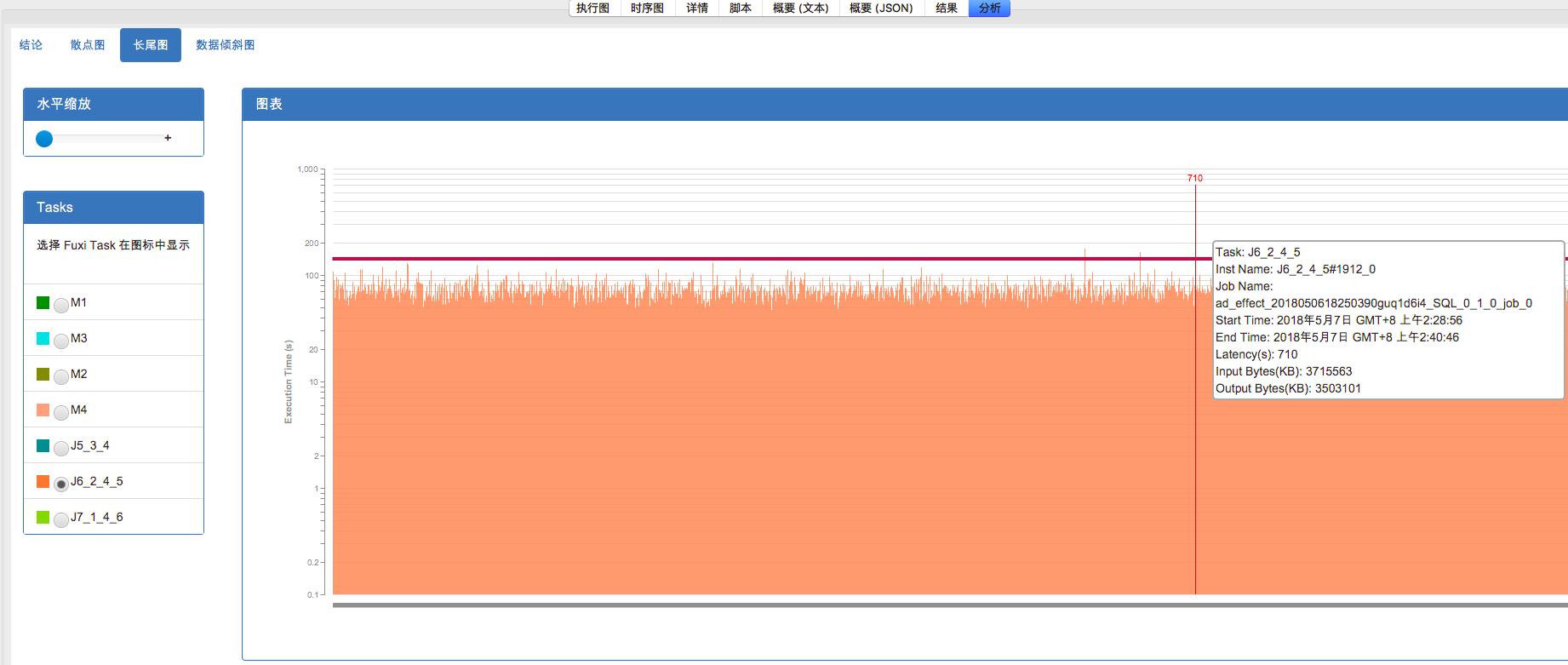
从上面fuxi instance 输入数据对比可以确定,因为J6_2_4_5#1912_0 这个instance 数据倾斜导致整个作业一长尾。即J6_2_4_5#1912_0 是latency排第二的输入数据量的7倍!
渐入佳境,刨根问底
第六步,查看单个instance的执行日志,并通过job graph分析J6_2_4_5的具体执行计划,找到导致长尾的数据来源。
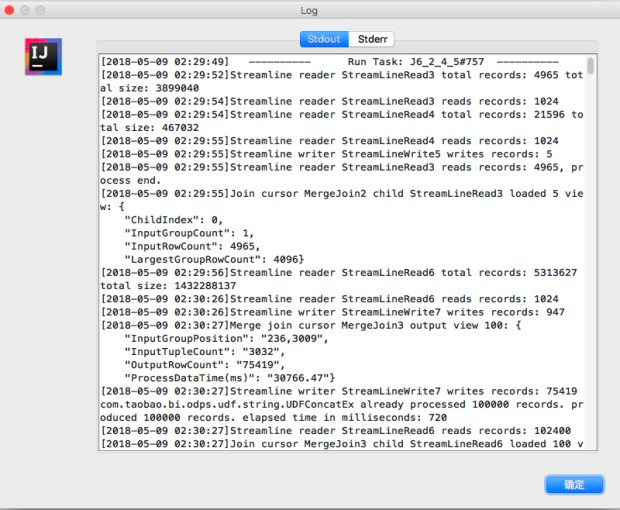
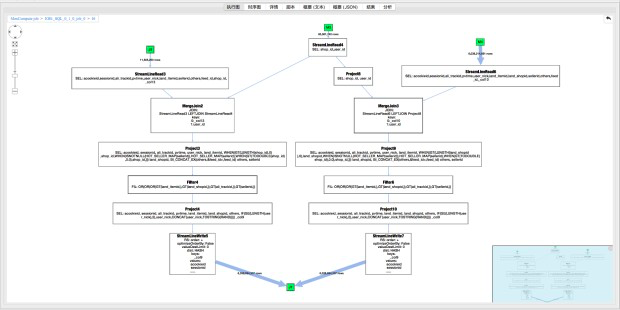
打开J6_2_4_5的operator graph, 可以看到有两个join:Merge Join2和Merge Join3,这里以Merge Join2为例展示如何查找数据来源。
从Merge Join2中可看到join key:_col13, user_id。 其中_col13 来自于J5, 点开J5后发现_col13来自IF(ISNULL(HOT_SELLER_MAP(sellerid)),sellerid,CONCAT(seller,TOSTRING(RAND()))) 说明_col13由seller决定,该seller来自于M4和M3。
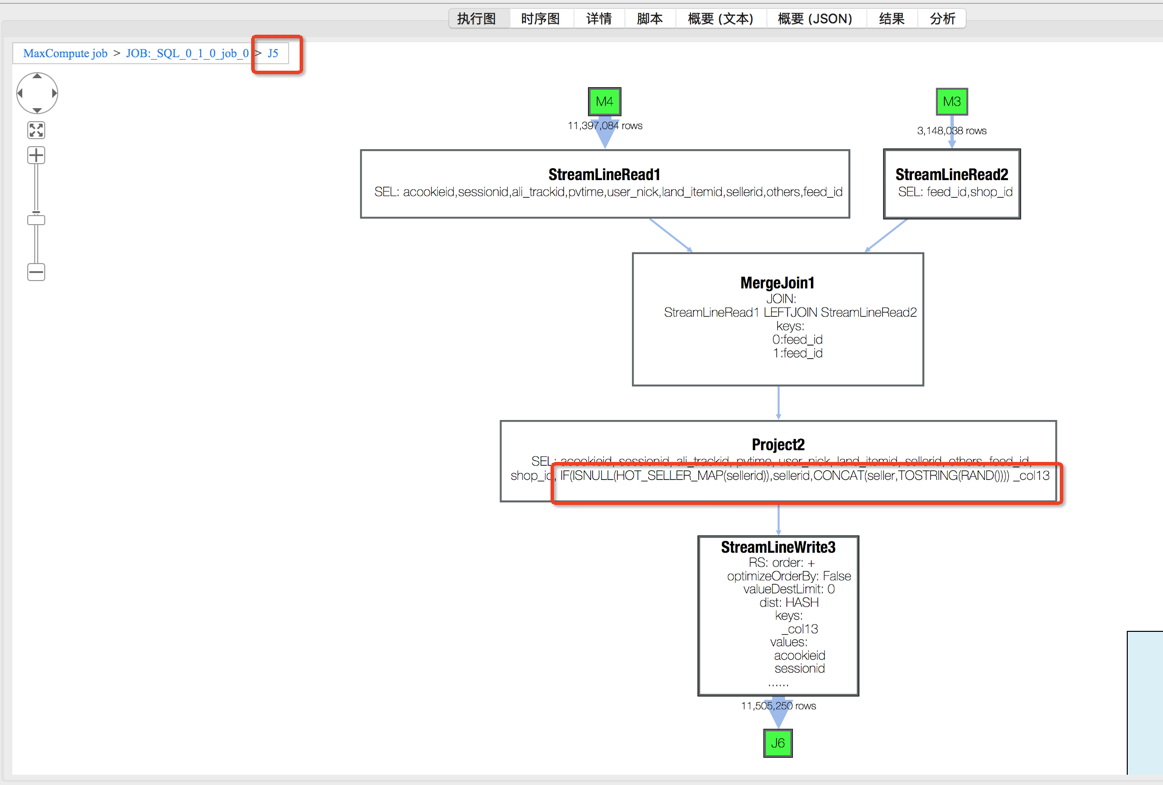
分别打开M4和M3的Operator详细信息,可以看到seller 分别来自tmp_s_dw_log_app_user_track_pre_1_20180508 和dim_feed_shop。
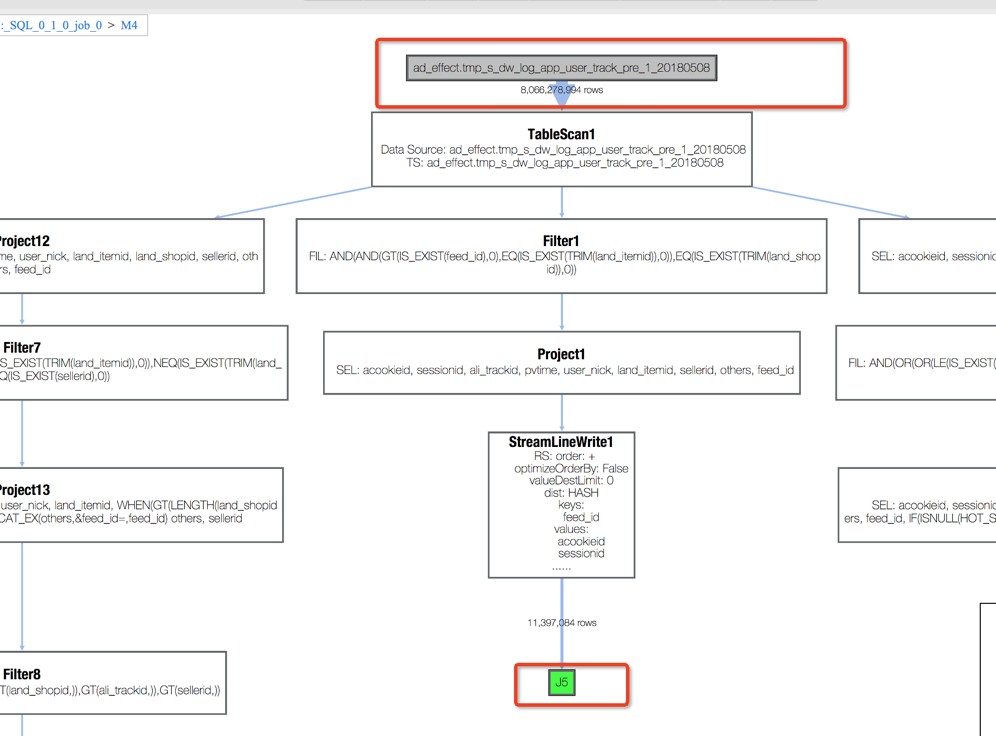

同理可以分析出Merge Join2 的user_id 来自于dim_tb_shop。
最后,通过写sql模拟产生对应的userid及_col13,比较这两个字段的数据量大小,在针对sql脚本进行优化即可。sql脚本优化不在本文介绍范围,因此不在此赘述。
回顾一下
有了 MaxCompute Studio 作业分析这样趁手的工具,遇到各种 MaxCompute 作业的问题就不再束手无策了,甚至,咱们都没有打开那 “让人悲喜交加”的 Logview 不是?
本文作者:皓平
一探究竟:善用 MaxCompute Studio 分析 SQL 作业的更多相关文章
- 玩转MaxCompute studio SQL编辑器
SQL因其简单易学的特点,是用户与MaxCompute服务交互的主要手段.如何帮助用户高效愉快的编写SQL是MaxCompute studio的核心使命,下面就让我们来一探究竟: 忘记语法 相信大家都 ...
- MaxCompute Studio 使用入门
MaxCompute Studio 是MaxCompute 平台提供的安装在开发者客户端的大数据集成开发环境工具,是一套基于流行的集成开发平台 IntelliJ IDEA 的开发插件,可以帮助您方便地 ...
- MaxCompute Studio使用心得系列7——作业对比
在数据开发过程中,我们通常需要将两个作业进行对比从而定位作业运行性能或者结果有差异的问题,但是对比作业时需要同时打开两个studio 的tab页,或者两个Logview页,不停切换进行对比,使用起来非 ...
- Log Parser Studio 分析 IIS 日志
Log Parser Studio 分析 IIS 日志 来源 https://www.cnblogs.com/lonelyxmas/p/8671336.html 软件下载地址: Log Parser ...
- windows管理员利器之用Log Parser Studio分析IIS日志(附逐浪CMS官方命令集)
原文:windows管理员利器之用Log Parser Studio分析IIS日志(附逐浪CMS官方命令集) Log Parser Studio是一个强大的IIS图形分析工具,值得推荐. 1. 安装L ...
- MaxCompute如何对SQL查询结果实现分页获取
由于MaxCompute SQL本身不提供类似数据库的select * from table limit x offset y的分页查询逻辑.但是有很多用户希望在一定场景下能够使用获取类似数据库分页的 ...
- MaxCompute Studio提升UDF和MapReduce开发体验
原文链接:http://click.aliyun.com/m/13990/ UDF全称User Defined Function,即用户自定义函数.MaxCompute提供了很多内建函数来满足用户的计 ...
- 如何使用SQLPLUS分析SQL语句(查询执行计划跟踪)
方法一:autotrace 1, connect sys/密码 as sysdba,在sys用户下运行$ORACLE_HOME/sqlplus/admin/plustrce.sql这段sql的实际内 ...
- 云计算之路-阿里云上:借助IIS Log Parser Studio分析“黑色30秒”问题
今天下午15:11-15:13间出现了类似“黑色30秒”的状况,我们用强大的IIS日志分析工具——Log Parser Studio进行了进一步的分析. 分析情况如下—— 先看一下Windows性能监 ...
随机推荐
- Flask框架【七】—session组件详解
一.flask session简介 flask中session组件可分为内置的session组件还有第三方flask-session组件,内置的session组件缺点: 功能单一 session是保存 ...
- VMware 虚拟化编程(10) — VMware 数据块修改跟踪技术 CBT
目录 目录 前文列表 数据块修改跟踪技术 CBT 为虚拟机开启 CBT CBT 修改数据块偏移量获取函数 QueryChangedDiskAreas changeId 一个 QueryChangedD ...
- 测开之路一百一十:bootstrap图片
bootstrap图片 引入bootstrap 原版的图片 bootstrap处理后的: 圆角.圆形.缩略图 自适应窗口
- Arduino入门之前
胡乱乱的,就买了,这个 arduino的板子. 哎...本来明明是 学动漫的,然后 不小心就开始 做软件了,然后 越跑越偏...现在 开始 做 硬件开发了... 其实 还有 树莓派 可供选择,算了,不 ...
- 实验报告2&&第四周课程总结
实验报告: 写一个名为Rectangle的类表示矩形.其属性包括宽width.高height和颜色color,width和height都是double型的,而color则是String类型的.要求该类 ...
- SpringBoot(三) -- SpringBoot与日志
一.日志的起源 现在假设一个开发人员在开发一个大型系统,由于这个系统过于庞大没在很多的地方将关键的数据使用System.out.println()打印,但是当我们在项目正式上线时又需要去除,在项目bu ...
- PTA第二题
#include<string.h> #include<stdio.h> #include<malloc.h> ]; ][]={"ling",& ...
- HDU 6649 Data Structure Problem(凸包+平衡树)
首先可以证明,点积最值的点对都是都是在凸包上,套用题解的证明:假设里两个点都不在凸包上, 考虑把一个点换成凸包上的点(不动的那个点), 不管你是要点积最大还是最小, 你都可以把那个不动的点跟原点拉一条 ...
- Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析 (转)
阅读前提:本文分析的是源码,所以至少读者要熟悉它们的接口使用,同时,对于并发,读者至少要知道 CAS.ReentrantLock.UNSAFE 操作这几个基本的知识,文中不会对这些知识进行介绍.Jav ...
- java 注解 Annontation
什么是注解? 对于很多初次接触的开发者来说应该都有这个疑问?Annontation是Java5开始引入的新特征,中文名称叫注解.它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metada ...