朴素贝叶斯算法——实现新闻分类(Sklearn实现)
1、朴素贝叶斯实现新闻分类的步骤
(1)提供文本文件,即数据集下载
(2)准备数据
将数据集划分为训练集和测试集;使用jieba模块进行分词,词频统计,停用词过滤,文本特征提取,将文本数据向量化
停用词文本stopwords_cn.txt下载
jieba模块学习:https://github.com/fxsjy/jieba ; https://www.oschina.net/p/jieba
(3)分析数据:使用matplotlib模块分析
(4)训练算法:使用sklearn.naive_bayes 的MultinomialNB进行训练
在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。
其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
(5)测试算法:使用测试集对贝叶斯分类器进行测试
2、代码实现
# -*- coding: UTF-8 -*-
import os
import random
import jieba
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt """
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
"""
def TextProcessing(folder_path, test_size=0.2):
folder_list = os.listdir(folder_path) # 查看folder_path下的文件
data_list = [] # 数据集数据
class_list = [] # 数据集类别
# 遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) # 根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) # 存放子文件夹下的txt文件的列表
j = 1
# 遍历每个txt文件
for file in files:
if j > 100: # 每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding='utf-8') as f: # 打开txt文件
raw = f.read() word_cut = jieba.cut(raw, cut_all=False) # 精简模式,返回一个可迭代的generator
word_list = list(word_cut) # generator转换为list data_list.append(word_list) # 添加数据集数据
class_list.append(folder) # 添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) # zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) # 将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 # 训练集和测试集切分的索引值
train_list = data_class_list[index:] # 训练集
test_list = data_class_list[:index] # 测试集
train_data_list, train_class_list = zip(*train_list) # 训练集解压缩
test_data_list, test_class_list = zip(*test_list) # 测试集解压缩 all_words_dict = {} # 统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1 # 根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key=lambda f: f[1], reverse=True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) # 解压缩
all_words_list = list(all_words_list) # 转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list """
函数说明:读取文件里的内容,并去重
Parameters:
words_file - 文件路径
Returns:
words_set - 读取的内容的set集合
"""
def MakeWordsSet(words_file):
words_set = set() # 创建set集合
with open(words_file, 'r', encoding='utf-8') as f: # 打开文件
for line in f.readlines(): # 一行一行读取
word = line.strip() # 去回车
if len(word) > 0: # 有文本,则添加到words_set中
words_set.add(word)
return words_set # 返回处理结果 """
函数说明:文本特征选取
Parameters:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 指定的结束语
Returns:
feature_words - 特征集
"""
def words_dict(all_words_list, deleteN, stopwords_set=set()):
feature_words = [] # 特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: # feature_words的维度为1000
break
# 如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words """
函数说明:根据feature_words将文本向量化
Parameters:
train_data_list - 训练集
test_data_list - 测试集
feature_words - 特征集
Returns:
train_feature_list - 训练集向量化列表
test_feature_list - 测试集向量化列表
"""
def TextFeatures(train_data_list, test_data_list, feature_words):
def text_features(text, feature_words): # 出现在特征集中,则置1
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list, test_feature_list # 返回结果 """
函数说明:新闻分类器
Parameters:
train_feature_list - 训练集向量化的特征文本
test_feature_list - 测试集向量化的特征文本
train_class_list - 训练集分类标签
test_class_list - 测试集分类标签
Returns:
test_accuracy - 分类器精度
"""
def TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list):
classifier = MultinomialNB().fit(train_feature_list, train_class_list)
test_accuracy = classifier.score(test_feature_list, test_class_list)
return test_accuracy if __name__ == '__main__':
# 文本预处理
folder_path = './SogouC/Sample' # 训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path,test_size=0.2)
# 生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file) test_accuracy_list = []
"""
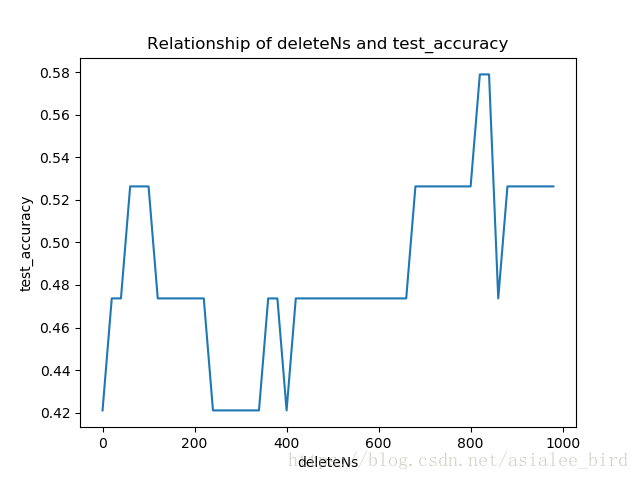
deleteNs = range(0, 1000, 20) # 0 20 40 60 ... 980
for deleteN in deleteNs:
feature_words = words_dict(all_words_list, deleteN, stopwords_set)
train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)
test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)
test_accuracy_list.append(test_accuracy)
plt.figure()
plt.plot(deleteNs, test_accuracy_list)
plt.title('Relationship of deleteNs and test_accuracy')
plt.xlabel('deleteNs')
plt.ylabel('test_accuracy')
plt.show()
"""
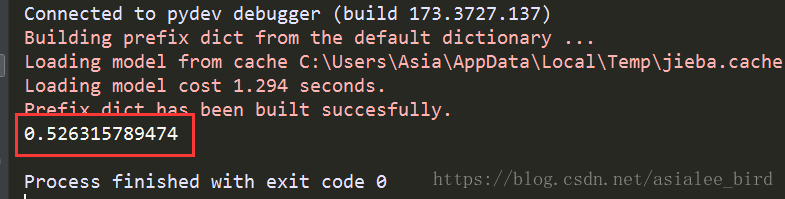
feature_words = words_dict(all_words_list, 450, stopwords_set)
train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)
test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)
test_accuracy_list.append(test_accuracy)
ave = lambda c: sum(c) / len(c)
print(ave(test_accuracy_list))
结果为:
朴素贝叶斯算法——实现新闻分类(Sklearn实现)的更多相关文章
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- 手写朴素贝叶斯(naive_bayes)分类算法
朴素贝叶斯假设各属性间相互独立,直接从已有样本中计算各种概率,以贝叶斯方程推导出预测样本的分类. 为了处理预测时样本的(类别,属性值)对未在训练样本出现,从而导致概率为0的情况,使用拉普拉斯修正(假设 ...
- 【sklearn朴素贝叶斯算法】高斯分布/多项式/伯努利贝叶斯算法以及代码实例
朴素贝叶斯 朴素贝叶斯方法是一组基于贝叶斯定理的监督学习算法,其"朴素"假设是:给定类别变量的每一对特征之间条件独立.贝叶斯定理描述了如下关系: 给定类别变量\(y\)以及属性值向 ...
- Naive Bayes(朴素贝叶斯算法)[分类算法]
Naïve Bayes(朴素贝叶斯)分类算法的实现 (1) 简介: (2) 算法描述: (3) <?php /* *Naive Bayes朴素贝叶斯算法(分类算法的实现) */ /* *把. ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法(Naive Bayes) 阅读目录 一.病人分类的例子 二.朴素贝叶斯分类器的公式 三.账号分类的例子 四.性别分类的例子 生活中很多场合需要用到分类,比如新闻分类.病人分类等等. 本 ...
- 机器学习:python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实 ...
随机推荐
- 实用工具/API
实用工具/API PNG图片无损压缩 在线给图片加水印 随机密码生成 随机头像生成 微博一键清理工具 CSS压缩 在线工具 免费虚拟主机 技术摘要 https://github.com/biezhi/ ...
- 解决异常信息 Caused by: java.lang.IllegalArgumentException: invalid comparison: java.lang.String and java.util.Date
原来的xml文件 <if test="null != endDate and '' != endDate"> AND rr.REG_DATE <= #{endDa ...
- [CF Round603 Div2 F]Economic Difficulties
题目:Economic Difficulties 传送门:https://codeforces.com/contest/1263/problem/F 题意:给了两棵tree:Ta(拥有a个节点,节点编 ...
- Taylor Swift -《Fearless》
最近网上都搜不到Taylor的歌了,分享一张love best的album给大家,支持霉霉的还是去买正版把~ 专辑曲目: 01. “Jump Then Fall” 03:5702. “Untoucha ...
- SQL Server系列之 删除大量数据
一.写在前面 - 想说爱你不容易 为了升级数据库至SQL Server 2008 R2,拿了一台现有的PC做测试,数据库从正式库Restore(3个数据库大小夸张地达到100G+),而机器内存只有可怜 ...
- P1439 【模板】最长公共子序列(LCS)
先来看一看普通的最长公共子序列 给定字符串A和B,求他们的最长公共子序列 DP做法: 设f[i][j]表示A[1~i]和B[1~j]的最长公共子序列的长度 那么f[i][j]=max(f[i-1][j ...
- redux源码浅入浅出
运用redux有一段时间了,包括redux-thunk和redux-saga处理异步action都有一定的涉及,现在技术栈转向阿里的dva+antd,好用得不要不要的,但是需要知己知彼要对react家 ...
- 并发测试JMeter及发送Json请求
1.下载 提前安装好jdk1.8 官网下载地址:http://jmeter.apache.org/download_jmeter.cgi 2.解压,双击bin/jmeter.bat 3.jmeter配 ...
- 内置函数zip,map,even
内置函数的补充:1.zip:l1 = ['a','b','c','e','f','g']l2 = [1,2,3]l3=['A','B','C']L4=['牛','牛','niu']#zip,就是把俩l ...
- jmeter之自动重定向和跟随重定向用法
jmeter工具里面有自动重定向和跟随重定向这2种选择,那么他们到底有啥区别呢? 目录 1.自动重定向和跟随重定向 2.举个例子 1.自动重定向和跟随重定向 01.3XX的请求一般要使用跟随重定向,2 ...