idea生成实体类
1、点击View->Tool Windows->Database
2、点击Datebase框的加号,DateSource,选择对应的数据源,配置对应信息,点击Test Connection测试连通性
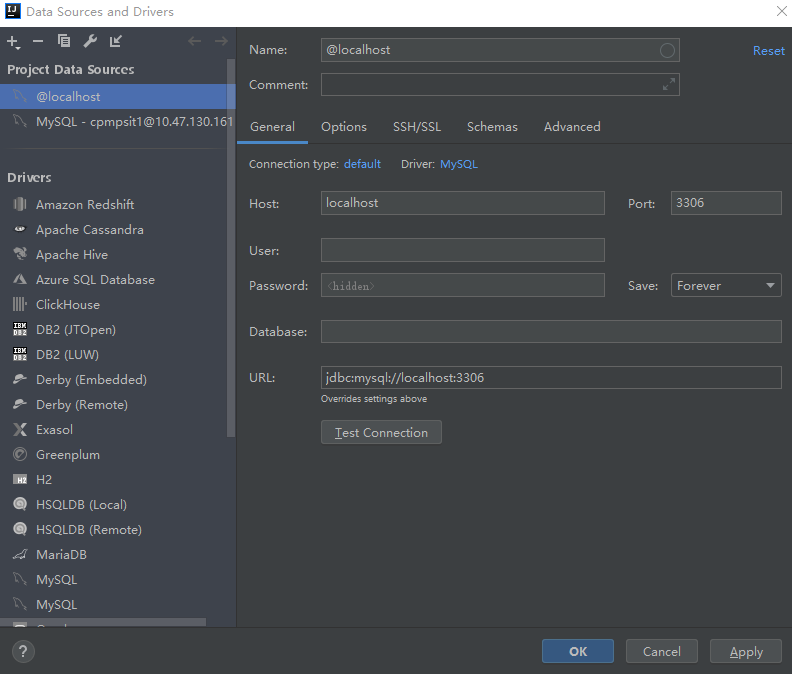
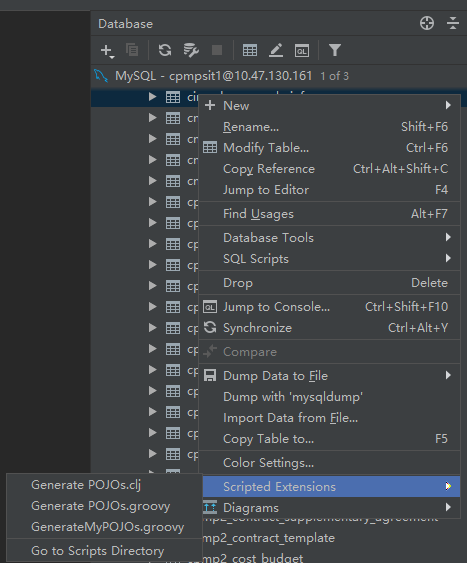
3、配置完成数据源后,选择需要生成实体的表,右键选择Script Extensions,Go To Script Directory,把脚本文件(GenerateMyPOJOs.groovy)放到Script目类
import com.intellij.database.model.DasTable
import com.intellij.database.model.ObjectKind
import com.intellij.database.util.Case
import com.intellij.database.util.DasUtil /*
* Available context bindings:
* SELECTION Iterable<DasObject>
* PROJECT project
* FILES files helper
*/ typeMapping = [
(~/(?i)number\(\d\)/) : "int",
(~/(?i)number/) : "double",
(~/(?i)int/) : "int",
(~/(?i)long/) : "long",
(~/(?i)float|double|decimal|real/): "double",
(~/(?i)timestamp|datetime|date|time/) : "LocalDateTime",
(~/(?i)/) : "String"
] FILES.chooseDirectoryAndSave("Choose directory", "Choose where to store generated files") { dir ->
SELECTION.filter { it instanceof DasTable && it.getKind() == ObjectKind.TABLE }.each { generate(it, dir) }
} def generate(table, dir) {
def className = javaName(table.getName(), true)
def fields = calcFields(table)
def file = new File(dir,className+".java")
def packageName = dir.toString().replaceAll("\\\\", ".").replaceAll("^.*src(\\.main\\.java\\.)?", "") + ";"
def writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file), "utf-8")) writer.withPrintWriter { out -> generate(out, table, fields, packageName) }
} def generate(out, table, fields, packageName) {
def tableName = table.getName()
def className = javaName(tableName, true)
def tableComment = table.getComment()
def hasPK = DasUtil.getPrimaryKey(table)!=null
def hasDatetime = false
fields.each() {hasDatetime=hasDatetime||it.type=="LocalDateTime"} out.println "package $packageName"
out.println ""
out.println "import javax.persistence.*;"
if (hasPK) out.println "import java.time.LocalDateTime;"
out.println "import org.hibernate.annotations.GenericGenerator;"
out.println ""
if (tableComment != "" && tableComment != null){
out.println "/**"
out.println " * ${tableComment}"
out.println " */"
}
if (hasPK) out.println "@Entity"
out.println "@Table(name = \"${tableName}\")"
out.println "public class $className {"
out.println ""
fields.each() {
out.println " //${it.commoent} ${it.spec}"
out.println " private ${it.type} ${it.name};"
out.println ""
}
fields.each() {
out.println ""
if (it.isId) out.println " @Id"
if (it.isId) out.println " @GeneratedValue()"
if (it.annos != "") out.println " ${it.annos}"
out.println " public ${it.type} get${it.name.capitalize()}() {"
out.println " return ${it.name};"
out.println " }"
out.println ""
out.println " public void set${it.name.capitalize()}(${it.type} ${it.name}) {"
out.println " this.${it.name} = ${it.name};"
out.println " }"
out.println ""
}
out.println "}"
} def calcFields(table) {
def primaryKey = DasUtil.getPrimaryKey(table)
DasUtil.getColumns(table).reduce([]) { fields, col ->
def spec = Case.LOWER.apply(col.getDataType().getSpecification())
def typeStr = typeMapping.find { p, t -> p.matcher(spec).find() }.value
def colName = col.getName()
fields += [[
name : javaName(col.getName(), false),
type : typeStr,
commoent: col.getComment(),
spec:spec,
isId : primaryKey != null && DasUtil.containsName(colName, primaryKey.getColumnsRef()),
annos : "@Column(name = \"${colName}\")",
]]
}
} def javaName(str, capitalize) {
def s = str.split(/(?<=[^\p{IsLetter}])/).collect { Case.LOWER.apply(it).capitalize() }
.join("").replaceAll(/[^\p{javaJavaIdentifierPart}]/, "")
.replaceAll("_", "")
capitalize || s.length() == 1 ? s : Case.LOWER.apply(s[0]) + s[1..-1]
}
再次右键需要转换的表,Script Extensions,选择GenerateMyPOJOs.groovy,选择对应目录,即可生成实体类
可以根据自己的需要修改groovy脚本,生成合适的实体类
idea生成实体类的更多相关文章
- NHibernate生成实体类、xml映射文件
最近工作电脑装完win10后,之前使用的codeSmith安装不了,索性自己写一个. 界面比较简单,如下图: 第一行为Oracle数据库的连接字符串.连接成功后,填充表到第4行的下拉列表中. 第二行为 ...
- (转)使用myeclipse生成实体类和hibernate映射文件
转至:http://blog.sina.com.cn/s/blog_9658bdb40100uiod.html 1.下载并安装myeclipse,如果已经安装,则忽略该步骤; 2.打开myeclips ...
- MyEclipse从数据库反向生成实体类之Hibernate方式 反向工程
前文: hibernate带给我们的O/RMapping思想是很正确的,即从面相对象的角度来设计工程中的实体对象,建立pojo,然后在编写hbm.xml映射文件来生成数据表.但是在实际开发中,往往我们 ...
- .net 根据匿名类生成实体类,根据datatable生成实体类,根据sql生成实体类
在开发中可能会遇到这几种情况 1.EF或LINQ查询出来的匿名对象在其它地方调用不方便,又懒的手动建实体类 2.通过datatable反射实体需要先建一个类 ,头痛 3.通过SQL语句返回的实体也需要 ...
- T4模板根据DB生成实体类
1.前言 为什么会有这篇文章了,最近看到了一些框架,里面要写的代码太多了,故此就想偷懒,要是能写出一个T4模板,在数据库添加表后,根据模板就可以自动生成了类文件了,这样多好,心动不如行动.记得使用T4 ...
- 使用T4为数据库自动生成实体类
T4 (Text Template Transformation Toolkit) 是一个基于模板的代码生成器.使用T4你可以通过写一些ASP.NET-like模板,来生成C#, T-SQL, XML ...
- T4模板_根据DB生成实体类
为了减少重复劳动,可以通过T4读取数据库表结构,生成实体类,用下面的实例测试了一下 1.首先创建一个项目,并添加文本模板: 2.添加 文本模板: 3.向T4文本模板文件添加代码: <#@ tem ...
- MyEclipse数据库反向生成实体类
MyEclipse数据库反向生成实体类 “计应134(实验班) 凌豪” 当我们在开发项目涉及到的表太多时,一个一个的写JAVA实体类很是费事.然而强大的MyEclipse为我们提供简便的方法:数据库反 ...
- 如何通过java反射将数据库表生成实体类?
首先有几点声明: 1.代码是在别人的基础进行改写的: 2.大家有什么改进的意见可以告诉我,也可以自己改好共享给其他人: 3.刚刚毕业,水平有限,肯定有许多不足之处: 4.希望刚刚学习java的同学能有 ...
- 在eclipse中生成实体类
1.在eclipse的windows中选中preferences在查询框中输入driver definition 2.点击add在Name/type中选中mysql jdbc driver 5.1然后 ...
随机推荐
- 小菜鸟之Cisco
Switch>enable// Switch#configure// Switch#show vlan//展示vlan接口 Switch(config)#enable password 1234 ...
- Zabbix 系统概述与部署
Zabbix是一个非常强大的监控系统,是企业级的软件,来监控IT基础设施的可用性和性能.它是一个能够快速搭建起来的开源的监控系统,Zabbix能监视各种网络参数,保证服务器系统的安全运营,并提供灵活的 ...
- 错误:SyntaxError: identifier starts immediately after numeric literal
转载:http://blog.csdn.net/shalousun/article/details/39995443在用JavaScript时,当你使用一个字符传作为函数的参数常常会看到语法错误,在f ...
- Charles学习(三)之使用Map local代理本地静态资源以及配置网页代理在Mac模拟器调试iOS客户端
前言 问题一:我们在App内嵌H5开发的过程中,肯定会遇到一个问题就是我不想在chrome的控制台中调试,我想要在手机上调试,那么如何解决这个问题呢? 问题二:我们期待调试时达到的效果就是和Charl ...
- oppo 手机不能连接appium,提示does not have permission android.permission.CLEAR_APP_USER_DATA to clear data
1)增加配置项noReset=true 2)除了常见开发者选项中打开usb调试,同时还需要开启以下2项,然后重启手机即可
- python视频学习笔记5(高级变量的类型)
知识点回顾: Python 中数据类型可以分为 **数字型** 和 **非数字型*** 数字型 * 整型 (`int`) * 浮点型(`float`) * 布尔型(`bool`) * 真 `True` ...
- Springmvc后台接前台数组,集合,复杂对象
本人转载自: http://blog.csdn.net/feicongcong/article/details/54705933 return "redirect:/icProject/in ...
- P1:天文数据获取
Step1:在sloan的casjob里http://casjobs.sdss.org/CasJobs/,密码用户 jiangbin 123456 查询满足条件的光谱对象,得到光谱对象的plate, ...
- 记一次生产环境presto删表失败的问题
场景,开发用java程序连接presto创建一个表,这个表在hdfs的权限为: 然后用presto去删除这个表 报错,没有权限删除,查看上一级目录权限,发现权限正常 直连hive删表 发现正常. 然后 ...
- centso 7 Keepalived 配置脚本
#!/bin/bash #This is keepalived bashshell. #MASTER/BACKUP yum install -y openssl openssl-devel keepa ...