HDFS-NameNode和SeconddaryNode
一、NN和2N的工作机制
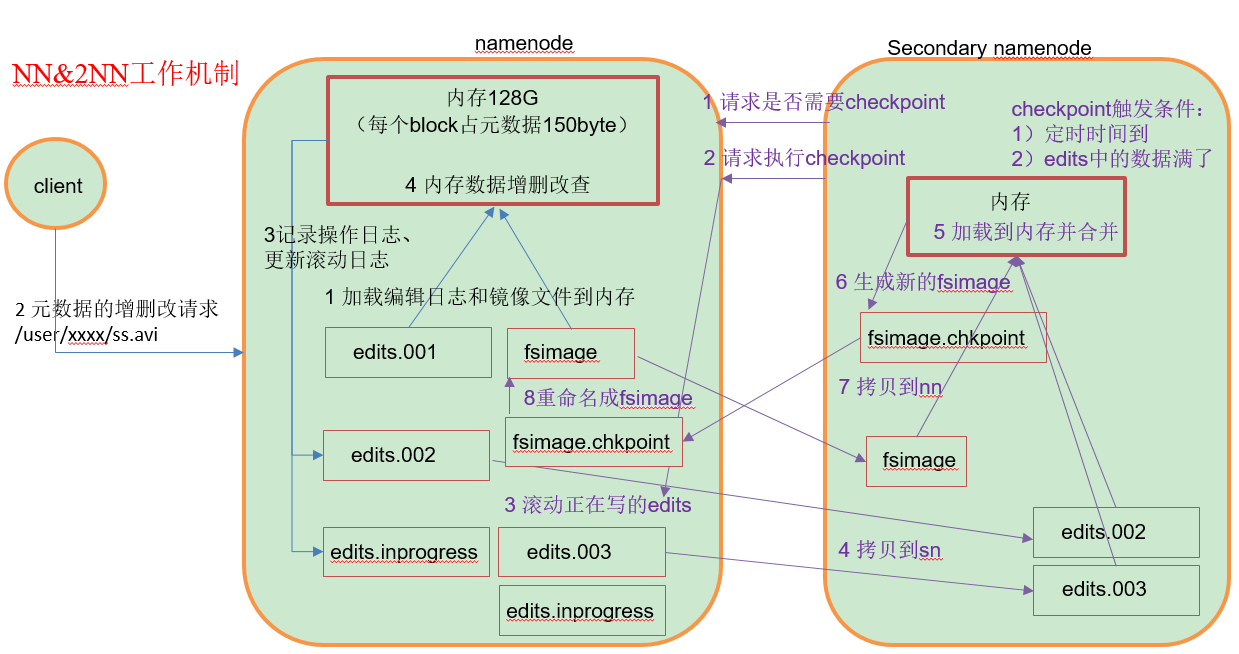
一、概述
一、概述
一、概述
一、概述
一、概述
一、概述
一、概述
HDFS-NameNode和SeconddaryNode的更多相关文章
- HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- hadoop 2.5 hdfs namenode –format 出错Usage: java NameNode [-backup] |
在 cd /home/hadoop/hadoop-2.5.2/bin 下 执行的./hdfs namenode -format 报错[hadoop@node1 bin]$ ./hdfs nameno ...
- hdfs namenode -initializeSharedEdits 和 hdfs namenode -bootstrapStandby
hdfs namenode -initializeSharedEdits 将所有journal node的元文件的VERSION文件的参数修改成与namenode的元数据相同 hdfs namenod ...
- 后端分布式系列:分布式存储-HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- Hadoop:HDFS NameNode内存全景
原文转自:https://tech.meituan.com/namenode.html 感谢原作者 一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方, ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- HDFS NameNode内存详解
前言 <HDFS NameNode内存全景>中,我们从NameNode内部数据结构的视角,对它的内存全景及几个关键数据结构进行了简单解读,并结合实际场景介绍了NameNode可能遇到的问题 ...
- HDFS NameNode内存全景
一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方,而且一旦NameNode出现故障,整个Hadoop集群就将处于不可服务的状态,同时随着数据规模和集群 ...
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- HDFS Namenode&Datanode
HDFS Namenode&Datanode HDFS 机制粗略示意图 客户端写入文件流程: NN && DN Namenode(NN)工作机制 NN是整个文件系统的管理节点. ...
随机推荐
- Version Controlling with Git in Visual Studio Code and Azure DevOps
Overview Azure DevOps supports two types of version control, Git and Team Foundation Version Control ...
- 定制团队自己的 Vue template
一,我们使用vue-cli 可以快速初始化vue.js的项目,官方提供了webpack,pwa,browserify-sipmple,等常用template 二.置知识1,模板结构template:该 ...
- "不能将值 NULL 插入列 'ID',表 列不允许有 Null 值."
问题: "不能将值 NULL 插入列 'ID',表 列不允许有 Null 值." 原因: 在进行表创建的时候没有将主键自增字段添加标识. 在使用navicat进行表创建的时候一定要 ...
- 2019南京网赛 The beautiful values of the palace(思维,树状数组
https://nanti.jisuanke.com/t/41298 题意:给一个n * n的螺旋矩阵,n保证是奇数,取一些点使其.获得价值,价值为数位和,然后再给q次查询,求矩阵中的价值总和 思路: ...
- springboot+UEditor图片上传
springboot+UEDitor百度编辑器整合图片上记录于此 1.下载ueditor插件包,解压到static/ueditor目录下 2.在你所需实现编辑器的页面引用三个JS文件 1) uedi ...
- [python 学习] IO操作之读写文件
一.读取全部文件: # -*- coding: utf-8 -*- f = open('qq_url.txt','r'); print f.read(); f.close(); 二.读取规定长度文件 ...
- bzoj4127 Abs 树链剖分+线段树+均摊分析
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=4127 题解 首先区间绝对值和可以转化为 \(2\) 倍的区间正数和 \(-\) 区间和.于是问 ...
- 记录ViewPager配合Fragment使用中遇到的一个问题
java.lang.IllegalStateException: FragmentManager is already executing transactions 如图所示: 当调用 notifyD ...
- Map.Entry的由来和使用
首先,回忆和练习一下HashMap的遍历 package Exercise.exercise; import java.util.HashMap; import java.util.Iterator; ...
- 如何删除发布服务器distribution
在建立发布服务器后自动生成distribution数据库为系统数据库,drop无法删除,实际删除方法如下:在“对象资源管理器”-“复制”上点击右键,选择“禁用发布和分发”,依次执行即可完成该系统数据库 ...