2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备
集群安装前需要考虑的几点
硬件选型
--CPU、内存、磁盘、网卡等
--什么配置?需要多少?
网络规划
--1 GB? 10 GB?
--网络拓扑?
操作系统选型及基础环境
--Linux?Windows?什么版本?
--哪些基础环境?
Hadoop版本选型
--Apache? CDH?HDP? 哪个版本?
Hadoop集群的角色基本上分为两类:
--Master:NameNode/Secondary NameNode/JobTracker/ResourceManager etc
--Worker: DataNode/TaskTracker/NodeManager
Master:
--对CPU和内存要求高,丌需要大容量存储
--为了数据可靠性,可以做RAID
--节点数要求不多,一般一个角色一台,HA配置需要多台
Worker:
--CPU和内存决定了单机的计算能力,磁盘容量决定了单机的存储能力
--一般性能强硬些,多磁盘用于存储大量数据
--节点数决定了集群规模,节点越多,集群计算和存储能力线性增长
推荐生产集群配置
Master Worker
CPU 24 core + 24 core+
内存 128G +(取决于集群规模) 128G/256G +
磁盘 600G SAS RAID1 4T*12,不必RAID,JBOD
网卡 10Gb,最好双网卡绑定 10Gb,最好双网卡 绑定
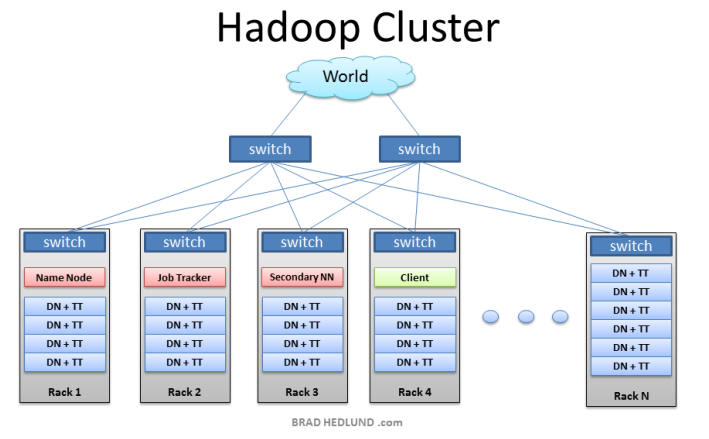
网络规划
HDFS有数据本地性优化,尽量减少节点间数据传输
客户端读写DataNode,MR shuffle等不可避免的数据传输,带宽越高性能越好
网络拓扑规划上要考虑容灾
操作系统选型
OS:
虽然新版本Hadoop支持运行在Windows上,但在生产上不要运行Windows,以Linux为主
选择支持的Linux版本(CentOS、 Redhat、 SUSE、 Ubuntu等),选择稳定的版本
基础环境:
ssh、 rsync、 ntp、 dns与主机名、 jdk等
关闭iptables,关闭selinux、禁用swap
关于分区不文件系统:
由于Hadoop的各个角色依赖本地磁盘,让数据目录独立分区
选择ext4/xfs等高效的文件系统
Hadoop版本选型
Hadoop除了官方社区发行的Apache Hadoop版本外,还有很多第三方的发行版,类似于Linux的发行版
主流的有:Cloudera CDH、 Hortonworks HDP、 MapR,还有IBM、 EMC、华为等
各个发行版基于Apache开源版本进行优化,并提供了自己的特殊功能比如方便部署管理、特殊feature等
如何选择?可参考以下几个因素:
--是否免费?是否开源?
--是否稳定?经过生产验证?
--社区支持如何?文档是否健全?
集群管理
当集群规模越来越大,集群管理和监控维护的成本越来越高,合适的集群管理工具是必要的
可以选择各个发行版自带的管理工具,如Cloudera CDH的Cloudera Manager
也可以用一些开源工具如puppet、 chef来自己维护
安装前的准备
--主机名和DNS
--节点规划
--基础环境准备
#yum安装
yum install pssh -y
#yun安装后pscp改名为pscp.pssh
#源码编译
[root@hadoop1 opt]# wget https://pypi.python.org/packages/60/9a/8035af3a7d3d1617ae2c7c174efa4f154e5bf9c24b36b623413b38be8e4a/pssh-2.3.1.tar.gz
[root@hadoop1 opt]# tar xf pssh-2.3.1.tar.gz
[root@hadoop1 opt]# cd pssh-2.3.1/
[root@hadoop1 pssh-2.3.1]# python setup.py install
[root@hadoop1 opt]# pssh --help
[root@hadoop1 opt]# vim cluster
[root@hadoop1 opt]# cat cluster
root@*
root@*
[root@hadoop1 ~]# ssh-keygen
[root@hadoop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub root@*
[root@hadoop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub root@*
[root@hadoop1 opt]# pssh -t 120 -h cluster -v -o ./ -e ./error/ ls
[root@hadoop1 opt]# pssh -h cluster -P "uptime"
======
pssh -h cluster -P "sed -i 's/=enforcing/=disabled/' /etc/selinux/config"
pssh -h cluster -P "service iptables stop"
pssh -h cluster -P "chkconfig iptables off"
pssh -h cluster -P "cat >> /etc/profile << EOF
export HISTTIMEFORMAT='%F %T '
EOF"
pssh -h cluster -P "sed -i '$a vm.swappiness = 0' /etc/sysctl.conf"
pssh -h cluster -P "sed -i '$a echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag' /etc/rc.local"
pssh -h cluster -P "sed -i '$a echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled' /etc/rc.local" pssh -h cluster -P "service ntpd start"
pssh -h cluster -P "chkconfig ntpd on"
pssh -h cluster -P "cat >> /etc/hosts << EOF
* hadoop1
* hadoop2
* hadoop3
EOF"
======
创建本地yum源
https://www.cloudera.com/documentation/enterprise/5-12-x/topics/cdh_ig_yumrepo_local_create.html
下载对应系统repo文件
[root@hadoop1 opt]# cp cloudera-cdh5.repo /etc/yum.repos.d/.
[root@hadoop1 opt]# yum install yum-utils createrepo
# cd /var/www/html/
[root@hadoop1 html]# reposync -r cloudera-cdh5
Put all the RPMs into a directory served by your web server, such as /var/www/html/cdh/5/RPMS/noarch/
##这里如果下载很慢,有的包下载报错[Errno 256] No more mirrors to try.
可以打开下载http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/RPMS/noarch/
https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/RPMS/x86_64/
--wget http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/RPMS/noarch/avro-libs-1.7.6+cdh5.16.1+143-1.cdh5.16.1.p0.3.el6.noarch.rpm
--wget https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/RPMS/x86_64/hadoop-2.6.0+cdh5.16.1+2848-1.cdh5.16.1.p0.3.el6.x86_64.rpm
# cd cloudera-cdh5
# createrepo .
# yum install httpd
# service httpd restart
# yum install w3m
[root@hadoop1 cloudera-cdh5]# w3m http://hadoop1/cloudera-cdh5
# cp /etc/yum.repos.d/cloudera-cdh5.repo /etc/yum.repos.d/cloudera-cdh5.repo.bk
# vim /etc/yum.repos.d/cloudera-cdh5.repo ##base url
Edit the repo file you downloaded in step 1 and replace the line starting with baseurl= or mirrorlist= with baseurl=http://<yourwebserver>/cdh/5/
[cloudera-cdh5]
# Packages for Cloudera's Distribution for Hadoop, Version 5, on RedHat or CentOS 6 x86_64
name=Cloudera's Distribution for Hadoop, Version 5
baseurl=http://hadoop1/cloudera-cdh5
#gpgkey =https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 0
# yum clean all
# yum install hadoop
[root@hadoop1 opt]# prsync -h cluster /etc/yum.repos.d/cloudera-cdh5.repo /tmp/
[root@hadoop1 opt]# pssh -h cluster -i "ls -l /tmp/cloudera-cdh5.repo"
[root@hadoop1 opt]# pssh -h cluster -i "mv /tmp/cloudera-cdh5.repo /etc/yum.repos.d/"
[root@hadoop1 opt]# pssh -h cluster -i "yum clean all"
[root@hadoop1 opt]# pssh -h cluster -i "yum install hadoop -y"
[root@hadoop1 opt]# pssh -h cluster -i "rpm -qa|grep hadoop" [root@hadoop1 opt]# pssh -h cluster -i "rpm -qa | grep java-1"
[root@hadoop1 opt]# prsync -h cluster jdk-8u191-linux-x64.tar.gz /opt/
[root@hadoop1 opt]# pssh -h cluster -i "tar -zxvf /opt/jdk-8u191-linux-x64.tar.gz -C /opt/"
[root@hadoop1 opt]# pssh -h cluster -i "ln -s /opt/jdk1.8.0_191 /opt/jdk"
[root@hadoop1 opt]# pssh -h cluster -i "alternatives --install /usr/bin/java java /opt/jdk/bin/java 100"
[root@hadoop1 opt]# pssh -h cluster -i "alternatives --install /usr/bin/javac javac /opt/jdk/bin/javac 100"
[root@hadoop1 opt]# pssh -h cluster -i "cat >> /etc/profile << EOF
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
EOF"
[root@hadoop1 opt]# pssh -h cluster -i "source /etc/profile"
[root@hadoop1 opt]# pssh -h cluster -i "rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64"
[root@hadoop1 opt]# pssh -h cluster -i "rpm -e --nodeps java-1.7.0-openjdk-1.7.0.181-2.6.14.10.el6.x86_64"
[root@hadoop1 opt]# pssh -h cluster -i "java -version"
2 Hadoop集群安装部署准备的更多相关文章
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...
- K8S集群安装部署
K8S集群安装部署 参考地址:https://www.cnblogs.com/xkops/p/6169034.html 1. 确保系统已经安装epel-release源 # yum -y inst ...
随机推荐
- Timer的利用
package 第十一章; import java.util.*; import java.util.TimerTask; public class TimerTest { /** * @param ...
- axios 文件流下载
this.axios .post(this.baseUrl+"/exportUser", { admin: "",keys: "",keyw ...
- freemarker如何在url中传递中文参数
例如:http://www.map512.cn/findPOI.do?key=南门如果不转码,request.getParameter("key")返回的是乱码,在jsp中,我们一 ...
- intel RDT技术管理cache和memory_bandwidth
主页:https://www.intel.com/content/www/us/en/architecture-and-technology/resource-director-technology. ...
- HTML/CSS实现文字环绕图片布局
原文: https://blog.csdn.net/yiyelanxin/article/details/75006925 在一个图文并茂的网页上,文字环绕图片可以使布局美观紧凑,如何实现呢?有两种办 ...
- MySQL简版(二)
第一章 表的约束 1.1 概念 对表中的数据进行限定,保证数据的正确性.有效性和完整性. 1.2 分类 主键约束:primary key. 非空约束:not null. 唯一约束:unique. 外键 ...
- BAT面试必问题系列:深入详解JVM 内存区域及内存溢出分析
前言 在JVM的管控下,Java程序员不再需要管理内存的分配与释放,这和在C和C++的世界是完全不一样的.所以,在JVM的帮助下,Java程序员很少会关注内存泄露和内存溢出的问题.但是,一旦JVM发生 ...
- LOJ6358 前夕
上来4的倍数又要交集恰好 单位根反演+二项式反演定了( 具体推柿子放下面了qwq $g(n) = \sum_{i=n}^N f(i) \binom{i}{n} \\g(n) = \binom{N}{n ...
- java Collections.binarySearch 用法
package testCollections; import java.util.ArrayList;import java.util.Collections;import java.util.Co ...
- sql server,mysql 和navicat for mysql的区别
一.定义 sql server 应该指的是sqlserver数据库,包含数据库管理系统等. navicat for sql server只是一个sqlserver的第三方的开发工具,管理工具. 二.开 ...