关于django中的rest_framework的使用
rest_framework框架的认识
一 路由
可以通过路由as_view()传参 根据请求方式的不同执行对应不同的方法
在routers模块下 封装了很多关于路由的方法 , 最基础的BaseRouter类,给我提供自定制的接口。
下面这个方法给我们提供了自动生成两条带参数的url

from rest_framework import routers
from django.conf.urls import url, include
from course.models import Course
from course.views import CourseView routers = routers.DefaultRouter()
routers.register('Course', CourseView) urlpatterns = [
url(r'^', include(routers.urls)), ]
二 视图
帮助开发者提供了一些类,并在类中提供了多种方法供我们使用,下图是提供的主要的类以及继承关系。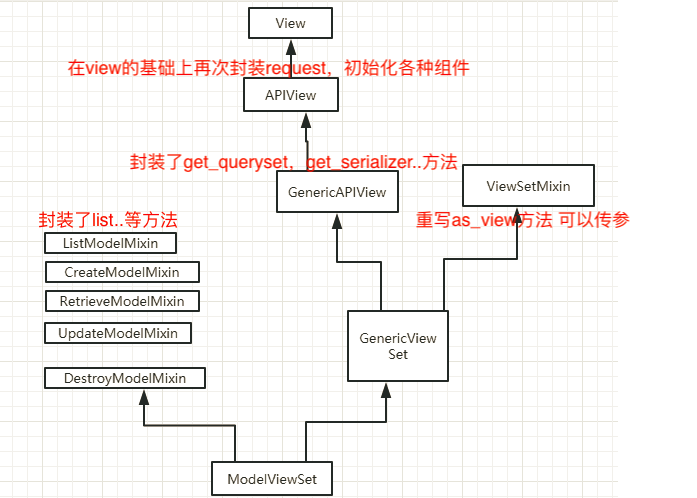
提供其他一些视图函数类,可以去源码里看。
三 版本控制
下面以URL上控制版本为例
1、添加配置
REST_FRAMEWORK = {
# 默认使用的版本控制类
'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',
# 允许的版本
'ALLOWED_VERSIONS': ['v1', 'v2'],
# 版本使用的参数名称
'VERSION_PARAM': 'version',
# 默认使用的版本
'DEFAULT_VERSION': 'v1',
}
2、设置路由
urlpatterns = [
#url(r'^admin/', admin.site.urls),
url(r'^api/(?P<version>\w+)/', include('api.urls')),
]
3、获取版本
request.version
四 认证
rest_framework给我们提供了认证的接口,由BaseAuthentication类提供接口,也有一些封装好的认证类(请走入源码....)
接口函数 authticate 认证成功返回一元组(user,token)分别赋值给request.user 和 request.auth
下面是一个简单的认证示例
class Auth(BaseAuthentication):
def authenticate(self, request):
token = request.query_params.get('token')
obj = models.Token.objects.filter(token=token).first()
if not obj:
raise AuthenticationFailed({'code': 1001, 'error': '认证失败'})
return (obj.user.username, obj)
我们的认证类可以放在局部视图函数,也可以配置为全局认证。
# 局部视图函数认证
class MyView(APIView):
authentication_classes = [Auth]
pass
# 全局配置 在settings.py
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [Auth],
}
五 权限
由BasePermission类给我提供接口 接口函数为 has_permission 以及 has_object_permission
有权限返回True 没有则返回False,默认的权限类为下图。
# 允许任何人访问
class AllowAny(BasePermission):
"""
Allow any access.
This isn't strictly required, since you could use an empty
permission_classes list, but it's useful because it makes the intention
more explicit.
""" def has_permission(self, request, view):
return True
接口类为下图
class BasePermission(object):
"""
A base class from which all permission classes should inherit.
""" def has_permission(self, request, view):
"""
Return `True` if permission is granted, `False` otherwise.
"""
# 这里写我们的权限逻辑
return True def has_object_permission(self, request, view, obj):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return True
还封装了一些权限类,只允许admin用户访问的权限,只给认证的用户权限等等,请走源码........
六 频率
基础的BaseThrottle类提供接口 接口函数为 allow_request,如果返回False则走wait
SimpleRateThrottle类给我们提供了get_cache_key接口,继承这个类要写rate(num_request, duration)多长时间内访问次数
实现原理如下代码:
class SimpleRateThrottle(BaseThrottle):
def allow_request(self, request, view):
if self.rate is None:
return True self.key = self.get_cache_key(request, view)
if self.key is None:
return True self.history = self.cache.get(self.key, [])
self.now = self.timer() # 原理的实现逻辑
while self.history and self.history[-1] <= self.now -self.duration:
self.history.pop()
if len(self.history) >= self.num_requests:
return self.throttle_failure()
return self.throttle_success()
这里就放这些~~具体~请大家走入源码.......
七 序列化
对queryset序列化以及对请求数据格式验证。
通常继承两个类 Serializer 以及 ModelSerializer
Serializer 序列化的每个字段都要自己写 ModelSerializer 会根据数据库表渲染所有字段
注意sourse 以及 钩子函数的应用 代码如下:
class CourseDetailModelSerializers(serializers.ModelSerializer):
title = serializers.CharField(source='course.name')
img = serializers.ImageField(source='course.course_img')
level = serializers.CharField(source='course.get_level_display')
recommends = serializers.SerializerMethodField()
chapters = serializers.SerializerMethodField() def get_recommends(self, obj):
queryset = obj.recommend_courses.all()
return [{'id': row.id, 'title': row.name} for row in queryset] def get_chapters(self, obj):
queryset = obj.course.course_chapters.all()
return [{'id': row.id, 'name': row.name} for row in queryset] class Meta:
model = CourseDetail
fields = ['course', 'title', 'img', 'level', 'why_study', 'chapters', 'recommends']
八 分页
对从数据库中获取到的数据进行分页处理 SQL --> limit offset
- 根据页码:http://www.myclass.com/api/v1/student/?page=1&size=10
- 根据索引:http://www.myclass.com/api/v1/student/?offset=60&limit=10
- 根据游标:http://www.myclass.com/api/v1/student/?page=erd8
页码越大速度越慢,为什么怎么解决?
- 原因:页码越大向后需要扫描的行数越多,因为每次都是从0开始扫描
- 解决:
- 限制当前显示的页数
- 记录当前页面数据ID的最大值和最小值,再次分页时,根据ID进行筛选,在分页
rest_framework 分页的配置
- 全局分页配置
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
'PAGE_SIZE': 100
}
- 修改分页风格
class MyPagination(PageNumberPagination):
page_size = 100
page_size_query_param = 'page_size'
max_page_size = 1000 # 然后在视图中使用.pagination_class属性调用该自定义类
class MyView(generics.ListAPIView):
queryset = Billing.objects.all()
serializer_class = BillingRecordsSerializer
pagination_class = MyPagination # 或者是在settings.py中修改DEFAULT_PAGINATION_CLASS REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'apps.core.pagination.MyPagination'
}
rest_framework给我提供的API
1、 PageNumberPagination
|
1
|
GET https://api.example.org/accounts/?page=4 |
响应对象
HTTP 200 OK
{
"count": 1023
"next": "https://api.example.org/accounts/?page=5",
"previous": "https://api.example.org/accounts/?page=3",
"results": [
…
]
}
配置属性
- page_size 每页显示对象的数量 如果设置了就重写PAGE_SIZE
- page_query_param 页面查询参数 指示分页空间的查询参数的名字
- page_size_query_param 允许客户端根据每个请求设置页面大小 一般都为None
- max_page_size 设置了page_size_query_param 才有意义 客户端请求页面中显示最大数量
- last_page_strings 储存page_query_param参数请求过的值列表或元组
2、LImitOffsetPagination
路由配置以及返回类型
GET https://api.example.org/accounts/?limit=100&offset=400 HTTP 200 OK
{
"count": 1023
"next": "https://api.example.org/accounts/?limit=100&offset=500",
"previous": "https://api.example.org/accounts/?limit=100&offset=300",
"results": [
…
]
}
配置参数
- page_size 每页显示对象的数量 如果设置了就重写PAGE_SIZE
- default_limit: 如果客户端没有提供,则默认使用与PAGE_SIZE值一样。
- limit_query_param:表示限制查询参数的名字,默认为’limit’
- offset_query_param:表示偏移参数的名字, 默认为’offset’
- max_limit:允许页面中显示的最大数量,默认为None
3、CursorPagination
- 基于游标的分页显示了一个不透明的“cursor”指示器,客户端可以使用它来浏览结果集。
- 这种分页方式只允许用户向前或向后进行查询。并且不允许客户端导航到任意位置。
- 基于游标的分页方式比较复杂,它要求结果集给出一个固定的顺序,并且不允许客户端任意的对结果集进行索引
全局配置如下
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.CursorPagination',
'PAGE_SIZE': 100
}
配置参数:
- page_size:显示的最大条数
- cursor_query_param: 游标查询参数名,默认为’cursor’
- ordering: 排序字段名的列表或者元组,例如ordering = ‘slug’,默认为-created
4、自定义分页
- 继承pagination.BasePagination
- 重写paginate_queryset(self, queryset, request, view=None)方法 ,
初始化queryset对象,设置pagination实例 返回一个包含用户请求内容的可迭代对象 形成分页对象
- 重写get_paginated_response(self, data)方法
序列化请求页中所包含的对象,返回一个Response对象
class CustomPagination(pagination.PageNumberPagination):
def get_paginated_response(self, data):
return Response({
'links': {
'next': self.get_next_link(),
'previous': self.get_previous_link()
},
'count': self.page.paginator.count,
'results': data
}) # 设置自定义分页、
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'my_project.apps.core.pagination.CustomPagination',
'PAGE_SIZE': 100
}
九 解析器
默认的三个解析器
- JsonParser Json数据解析器
- FormParser 和 MultiPartParser 一般同时使用
Both request.data will be populated with a QueryDict. 官方文档的解释
DEFAULTS = {
# rest_framework settings.py
'DEFAULT_PARSER_CLASSES': (
'rest_framework.parsers.JSONParser',
'rest_framework.parsers.FormParser',
'rest_framework.parsers.MultiPartParser'
),
}
十 渲染器
默认的两个渲染器,一个是Json的,一个是用浏览器访问rest_framework自带的模板的
DEFAULTS = {
# rest_framework setting.py
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
),
}
关于django中的rest_framework的使用的更多相关文章
- Django缓存机制--rest_framework中节流源码使用的就是django提供的缓存api
一.配置缓存 https://www.jb51.net/article/124434.htm 二.缓存全站.页面.局部 三.自我控制的简单缓存API API 接口为:django.core.c ...
- python3-开发进阶Django中序列化以及rest_framework的序列化
一.django框架的序列化 直接上代码 1.这是app下的models.py from django.db import models # Create your models here. clas ...
- django中使用Profile扩展User模块(基于django 1.10版本下)
版本:Django 1.10.1(其他版本可能有不同的实现好解决办法) 参考官方文档:https://docs.djangoproject.com/en/1.10/topics/auth/custom ...
- 在django中使用Redis存取session
一.Redis的配置 1.django的缓存配置 # redis在django中的配置 CACHES = { "default": { "BACKEND": & ...
- Django中使用Celery
一.前言 Celery是一个基于python开发的分布式任务队列,如果不了解请阅读笔者上一篇博文Celery入门与进阶,而做python WEB开发最为流行的框架莫属Django,但是Django的请 ...
- django 中 Oauth2 实现第三方登陆
django 中 Oauth2 实现第三方登陆 python网站第三方登录,social-auth-app-django模块, social-auth-app-django模块是专门用于Django的 ...
- Django中的Cookie、Session、Token
Cookie : 指望着为了辨别用户身份.进行会话跟踪而存储在用户本地的数据(通常经过加密),是由服务端生成,发送给客户端浏览器,浏览器会将Cookie以key/value保存,下一请求同一网站是就发 ...
- 关于Django中,实现序列化的几种不同方法
前言 关于序列化操作,就是将一个可迭代的数据结构,通过便利的方式进行我们所需要的操作. 今天历来归纳一下,Django中的几种不同得分方法,已经Django-restframework提供的方法 创建 ...
- Django框架深入了解_05 (Django中的缓存、Django解决跨域流程(非简单请求,简单请求)、自动生成接口文档)
一.Django中的缓存: 前戏: 在动态网站中,用户所有的请求,服务器都会去数据库中进行相应的增,删,查,改,渲染模板,执行业务逻辑,最后生成用户看到的页面. 当一个网站的用户访问量很大的时候,每一 ...
随机推荐
- Django学习笔记--数据库中的单表操作----增删改查
1.Django数据库中的增删改查 1.添加表和字段 # 创建的表的名字为app的名称拼接类名 class User(models.Model): # id字段 自增 是主键 id = models. ...
- 查看linux服务器的版本信息
查看linux系统信息 uname -a Linux localhost.localdomain 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UT ...
- java ArrayList存储基本类型
package java06; /* 如果希望像集合ArrayList中存储基本数据类型数据,必须使用基本数据类型对应的“包装类” 基本数据类型 包装类(引用类型,包装类都位于java.lang包下 ...
- openstack--all-in-one部署
安装过程 本次宿主机(即安装OpenStack的机器)的操作系统是CentOS 7.5.安装的OpenStack是目前最新的rocky版本,官方文档建议机器至少有16 GB的内存,处理器硬件虚拟化扩展 ...
- ARC096E Everything on It 容斥原理
题目传送门 https://atcoder.jp/contests/arc096/tasks/arc096_c 题解 考虑容斥,问题转化为求至少有 \(i\) 个数出现不高于 \(1\) 次. 那么我 ...
- SDOI前的小计划
upd:19.4.5 放出来了.如果明天考了我没复习到的认了.考到了复习了的还没拿到理想分的就回来谢罪(bushi www SDOI一轮倒计时4天啦w 所以得有个小计划吧QwQ 4.2 目标:BZOJ ...
- 各类IP地址
IPv4地址分类 折叠 A类IPv4地址 B类IPv4地址 C类IPv4地址 D类IPv4地址 E类IPv4地址 网络标志位 0 10 110 1110 11110 IP地址范围 1.0.0.0~ ...
- Spring Transaction Propagation
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11530611.html REQUIRED behavior Spring REQUIRED behav ...
- [原创] Delphi InputBox、InputQuery函数
Delphi InputBox.InputQuery函数 两个函数都是弹框提示输入信息 function InputQuery(const ACaption, APrompt: string; var ...
- ConcurrentHashMap1.7源码分析
参考:https://www.cnblogs.com/liuyun1995/p/8631264.html HashMap不是线程安全的,其所有的方法都未同步,虽然可以使用Collections的syn ...