[Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題
- 大数据性能调优的本质
- Spark 性能调优要点分析
- Spark 资源使用原理流程
- Spark 资源调优最佳实战
- Spark 更高性能的算子
引言
我们谈大数据性能调优,到底在谈什么,它的本质是什么,以及 Spark 在性能调优部份的要点,这两点让在进入性能调优之前都是一个至关重要的问题,它的本质限制了我们调优到底要达到一个什么样的目标或者说我们是从什么本源上进行调优。希望这篇文章能为读者带出以下的启发:
- 了解大数据性能调优的本质
- 了解 Spark 性能调优要点分析
- 了解 Spark 在资源优化上的一些参数调优
- 了解 Spark 的一些比较高效的 RDD 操作算子
大数据性能调优的本质
编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论做什么类型的编程,最终思考的都是硬件方面的问题!最终思考都是在一秒、一毫秒、甚至一纳秒到底是如何运行的,并且基于此进行算法实现和性能调优,最后都是回到了硬件!
在大数据性能的调优,它的本质是硬件的调优!即基于 CPU(计算)、Memory(存储)、IO-Disk/ Network(数据交互) 基础上构建算法和性能调优!我们在计算的时候,数据肯定是存储在内存中的。磁盘IO怎么去处理和网络IO怎么去优化。
Spark 性能调优要点分析
在大数据性能本质的思路上,我们应该需要在那些方面进行调优呢?比如:
- 并行度
- 压缩
- 序例化
- 数据倾斜
- JVM调优 (例如 JVM 数据结构化优化)
- 内存调优
- Task性能调优 (例如包含 Mapper 和 Reducer 两种类型的 Task)
- Shuffle 网络调优 (例如小文件合并)
- RDD 算子调优 (例如 RDD 复用、自定义 RDD)
- 数据本地性
- 容错调优
- 参数调优
大数据最怕的就是数据本地性(内存中)和数据倾斜或者叫数据分布不均衡、数据转输,这个是所有分布式系统的问题!数据倾斜其实是跟你的业务紧密相关的。所以调优 Spark 的重点一定是在数据本地性和数据倾斜入手。
- 资源分配和使用:你能够申请多少资源以及如何最优化的使用计算资源
- 关发调优:如何基于 Spark 框架内核原理和运行机制最优化的实现代码功能
- Shuffle调优:分布式系统必然面临的杀手级别的问题
- 数据倾斜:分布式系统业务本身有数据倾斜
Spark 资源使用原理流程
这是一张来至于官方的经典资源使用流程图,这里有三大组件,第一部份是 Driver 部份,第二就是具体处理数据的部份,第三就是资源管理部份。这一张图中间有一个过程,这表示在程序运行之前向资源管理器申请资源。在实际生产环境中,Cluster Manager 一般都是 Yarn 的 ResourceManager,Driver 会向 ResourceManager 申请计算资源(一般情况下都是在发生计算之前一次性进行申请请求),分配的计算资源就是 CPU Core 和 Memory,我们具体的 Job 里的 Task 就是基于这些分配的内存和 Cores 构建的线程池来运行 Tasks 的。
[下图是 Spark 官方网站上的经典Spark架框图]
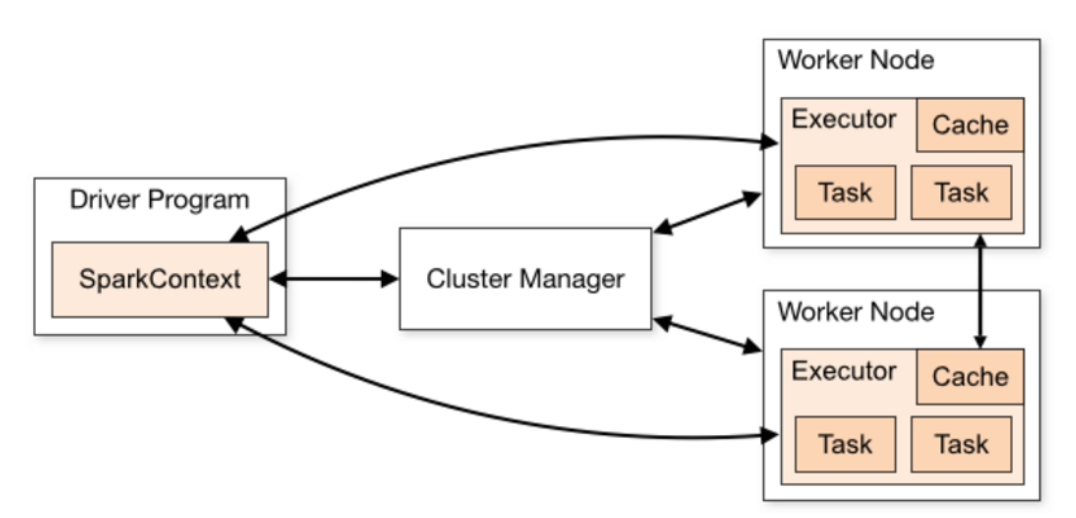
当然在 Task 运行的过程中会大量的消耗内存,而Task又分为 Mapper 和 Reducer 两种不同类型的 Task,也就是 ShuffleMapTask 和 ResultTask 两种类型,这类有一个很关建的调优点就是如何对内存进行使用。在一个 Task 运行的时候,默应会占用 Executor 总内存的 20%,Shuffle 拉取数据和进行聚合操作等占用了 20% 的内存,剩下的大概有 60% 是用于 RDD 持久化 (例如 cache 数据到内存),Task 在运行时候是跑在 Core 上的,比较理想的是有足够的 Core 同时数据分布比较均匀,这个时候往往能够充分利用集群的资源。
核心调优参数如下:
num-executors
executor-memory
executor-cores
driver-memory
spark.default.parallelizm
spark.storage.memoryFraction
spark.shuffle.memoryFraction
- num-executors:该参数一定会被设置,Yarn 会按照 Driver 的申请去最终为当前的 Application 生产指定个数的 Executors,实际生产环境下应该分配80个左右 Executors 会比较合适呢。
- executor-memory:这个定义了每个 Executor 的内存,它与 JVM OOM 紧密相关,很多时候甚至决定了 Spark 运行的性能。实际生产环境下建义是 8G 左右,很多时候 Spark 运行在 Yarn 上,内存占用量不要超过 Yarn 的内存资源的 50%。
- executor-cores:决定了在 Executors 中能够并行执行的 Tasks 的个数。实际生产环境下应该分配4个左右,一般情况下不要超过 Yarn 队列中 Cores 总数量的 50%。
- driver-memory:默应是 1G
- spark.default.parallelizm:并行度问题,如果不设置这个参数,Spark 会跟据 HDFS 中 Block 的个数去设置这一个数量,原理是默应每个 Block 会对应一个 Task,默应情况下,如果数据量不是太多就不可以充份利用 executor 设置的资源,就会浪费了资源。建义设置为 100个,最好 700个左右。Spark官方的建义是每一个 Core 负责 2-3 个 Task。
- spark.storage.memoryFraction:默应占用 60%,如果计算比较依赖于历史数据则可以调高该参数,当如果计算比较依赖 Shuffle 的话则需要降低该比例。
- spark.shuffle.memoryFraction:默应占用 20%,如果计算比较依赖 Shuffle 的话则需要调高该比例。
Spark 更高性能的算子
Shuffle 分开两部份,一个是 Mapper 端的Shuffle,另外一个就是 Reducer端的 Shuffle,性能调优有一个很重要的总结就是尽量不使用 Shuffle 类的算子,我们能避免就尽量避免,因为一般进行 Shuffle 的时候,它会把集群中多个节点上的同一个 Key 汇聚在同一个节点上,例如 reduceByKey。然后会优先把结果数据放在内存中,但如果内存不够的话会放到磁盘上。Shuffle 在进行数据抓取之前,为了整个集群的稳定性,它的 Mapper 端会把数据写到本地文件系统。这可能会导致大量磁盘文件的操作。如何避免Shuffle可以考虑以下:
- 采用 Map 端的 Join (RDD1 + RDD2 )先把一个 RDD1的数据收集过来,然后再通过 sc.broadcast( ) 把数据广播到 Executor 上;
- 如果无法避免Shuffle,退而求其次就是需要更多的机器参与 Shuffle 的过程,这个时候就需要充份地利用 Mapper 端和 Reducer 端机制的计算资源,尽量使用 Mapper 端的 Aggregrate 功能,e.g. aggregrateByKey 操作。相对于 groupByKey而言,更倾向于使用 reduceByKey( ) 和 aggregrateByKey( ) 来取代 groupByKey,因为 groupByKey 不会进行 Mapper 端的操作,aggregrateByKey 可以给予更多的控制。
- 如果一批一批地处理数据来说,可以使用 mapPartitions( ),但这个算子有可能会出现 OOM 机会,它会进行 JVM 的 GC 操作!
- 如果进行批量插入数据到数据库的话,建义采用foreachPartition( ) 。
- 因为我们不希望有太多的数据碎片,所以能批量处理就尽量批量处理,你可以调用 coalesce( ) ,把一个更多的并行度的分片变得更少,假设有一万个数据分片,想把它变得一百个,就可以使用 coalesce( )方法,一般在 filter( ) 算子之后就会用 coalesce( ),这样可以节省资源。
- 官方建义使用 repartitionAndSortWithPartitions( );
- 数据进行复用时一般都会进行持久化 persisit( );
- 建义使用 mapPartitionWithIndex( );
- 也建义使用 tree 开头的算子,比如说 treeReduce( ) 和 treeAggregrate( );
总结
大数据必然要思考的核心性能问题不外乎 CPU 计算、内存管理、磁盘和网络IO操作,这是无可避免的,但是可以基于这个基础上进行优化,思考如何最优化的使用计算资源,思考如何在优化代码,在代码层面上防避坠入性能弱点;思考如何减少网络传输和思考如何最大程度的实现数据分布均衡。
在资源管理调优方面可以设置一些参数,比如num-executors、executor-memory、executor-cores、driver-memory、spark.default.parallelizm、spark.storage.memoryFraction、spark.shuffle.memoryFraction
Shuffle 所导致的问题是所有分布式系统都无法避免的,但是如何把 Shuffle 所带来的性能问题减少最低,是一个很可靠的优化方向。Shuffle 的第一阶段即Mapper端在默应情况下会写到本地,而reducer通过网络抓取的同一个 Key 在不同节点上都把它抓取过来,内存可能不够,不够的话就写到磁盘中,这可能会导致大量磁盘文件的操作。在实际编程的时候,可以用一些比较高效的RDD算子,例如 reduceByKey、aggregrateByKey、coalesce、foreachPartition、repartitionAndSortWithPartitions。
参考资料
资料来源来至
[1] DT大数据梦工厂 大数据商业案例以及性能调优
第20课:大数据性能调优的本质和Spark性能调优要点分析
第21课:Spark性能调优之系统资源使用原理和调优最佳实践
第22课:Spark性能调优之使用更高性能算子及其源码剖析
[Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析的更多相关文章
- linux系统性能调优第一步——性能分析(vmstat)
linux系统性能调优第一步--性能分析(vmstat) 分类: LINUX 性能调优的第一步是性能分析,下面从性能分析着手进行一些介绍,尤其对linux性能分析工具vmstat的用法和实践进行详细介 ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
- 性能调优的本质、Spark资源使用原理和调优要点分析
本课主题 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Linux性能优化 第五章 性能工具:特定进程内存
5.1 Linux内存子系统 在诊断内存性能问题的时候,也许有必要观察应用程序在内存子系统的不同层次上是怎样执行的.在顶层,操作系统决定如何利用交换内存和物理内存.它决定应用程序的哪一块地址空间将被放 ...
- Ionic 入门与实战之第一章:Ionic 介绍与相关学习资源
原文发表于我的技术博客 本文是「Ionic 入门与实战」系列连载的第一章,主要对 Ionic 的概念.发展历程.适配的移动平台等知识进行了介绍,并分享了 Ionic 相关的学习资源. 原文发表于我的技 ...
- Linux性能优化 第一章 性能追踪建议
1.1常用建议1.1.1记大量的笔记(记录所有的事情)在做性能调优问题的时候很重要的一个操作就是记录下所有的事情,包括每一个输出.执行的结果.可以新建一个文件夹,然后把结果的文件都塞到该文件夹内.包括 ...
- SqlServer2008查询性能优化_第一章
- Linux性能优化 第七章 性能工具:网络
7.1 网络I/O介绍 Linux和其他主流操作系统中的网络流量被抽象为一系列的硬件和软件层次. 链路层,也就是最低的一层,包含网络硬件,如以太网设备.在传送网络流量时,这一层并不区分流量类型,而仅仅 ...
- Linux性能优化 第六章 性能工具:磁盘I/O
6.1 磁盘I/O介绍 一般来说,Linux磁盘的每个分区要么包含一个文件系统,要么包含一个交换分区.这些分区被挂载到Linux根文件系统,该系统由/etc/fstab指定.这些被挂载的文件系统包含了 ...
随机推荐
- Tomcat (安装及web实现 基础)
Tomcat服务器配置 安装:解压对应的版本就行 注意;不要把Tomcat放到有中文的和有空格的目录中 验证是否安装成功:进入安装盘的安装文件的bin目录下 执行startup bat 成功 80 ...
- JAVA IO分析二:字节数组流、基本数据&对象类型的数据流、打印流
上一节,我们分析了常见的节点流(FileInputStream/FileOutputStream FileReader/FileWrite)和常见的处理流(BufferedInputStream/B ...
- 【Win 10 应用开发】MIDI 音乐合成——乐理篇
针对 MIDI 音乐的 API ,其实在 Win 8.1 的时候就出现.在UWP中采用了新的驱动模式,MIDI 消息传递更加高效. 首先得说明的是,UWP 的 MIDI 相关 API 不是针对 MID ...
- TRITON恶意软件简单分析与防护方案
一.攻击简介 2017年12月,安全研究人员发现了一款针对工控系统安全仪表系统(SIS)的恶意软件"TRITON",该软件以施耐德电气Triconex安全仪表控制系统为目标展开攻击 ...
- MySQL-Select语句高级应用
1.1 SELECT高级应用 1.1.1 前期准备工作 本次测试使用的是world数据库,由mysql官方提供下载地址: https://dev.mysql.com/doc/index-other.h ...
- 局域网使用的IP地址范围
局域网可用的IP地址范围为: A类地址:10.0.0.0 - 10.255.255.255 B类地址:172.16.0.0 - 172.31.255.255 C类地址:192.168.0.0 -19 ...
- B. Simple Game( Codeforces Round #316 (Div. 2) 简单题)
B. Simple Game time limit per test 1 second memory limit per test 256 megabytes input standard input ...
- Android使用XUtils框架上传照片(一张或多张)和文本,server接收照片和文字(无乱码)
Android上传图片,这里我使用了如今比較流行的XUtils框架.该框架能够实现文件上传.文件下载.图片缓存等等,有待研究. 以下是Android端上传的代码: xUtils.jar下载 Strin ...
- mock.js的真实数据模拟
哈哈,怎么说,这应该是我的第一个随笔了,毕竟前端之路上一直在学习并且各位大神们的经验,虽然也有不少的坑,但是总是收获比较多,所以我也想把一些收获记录下来,有需要的可以参考参考. 网上看了不少大神很多例 ...
- SpringBoot Test集成测试
1.pom,文件添加相关依赖 如何测试SpringBoot的请求?使用spring-boot-starter-test这个包即可完成测试,SpringBoot项目为什么需要测试本章不作过多说明,重点放 ...