node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全。
本项目主要包含一下技术:
发送http抓取页面(http)、分析页面(cheerio)、中文乱码处理(bufferhelper)、异步并发流程控制(thenjs)
1、为什么选择http模块来发送Http请求下载页面
社区有很多封装好的Http请求模块,例如:request、needle、node-rest-client等,http有这些模块比拟不了的优势,可以监听抓取的字节流,我们知道要抓取的页面一般会含有汉字,一个汉字是3个字节(也有说4个字节),笔者在node中测试的是3个字节,一个英文字母是1个字节(见下图),node对中文的支持是不友好的,所以就需要借助bufferhelper来解决字节流问题,再使用 iconv-lite模块把buffer转化成utf8格式。

2、使用cheerio分析Html,让你感觉就像是在使用JQuery
3、虽说如今node上已经有异步控制的标准 async/await,但是thenjs,真的很好用,并且效率也不错,本项目主要用了它的异步并行控制 Then.each,了解更多thenjs介绍
4、本项目主要是抓取菜鸟教程的 HTML/CSS 下的8个页面,本项目先抓取 http://www.runoob.com 分析其Html,找到这8个页面的Url,再分别抓取这些页面的Html,写入到本地文件
代码 chong.js :
var http = require('http');
var Then = require('thenjs');
var BufferHelper = require('bufferhelper');
var fs = require('fs');
var cheerio = require('cheerio'); // Html分析模块
var iconv = require('iconv-lite'); // 字符转码模块
var pageUrl = []; //Url集合
var pagesHtml = []; //所有Url获取的Html的集合
var baseUrl = 'http://www.runoob.com';
main();
function main() {
console.log('Start');
Then(cont => {
grabPageAsync(baseUrl, cont)
}).then((cont, html) => {
var $ = cheerio.load(html);
var $html = $('.codelist.codelist-desktop.cate1');
var $aArr = $html.find('a');
$aArr.each((i, u) => {
pageUrl.push('http:' + $(u).attr('href'));
})
everyPage(cont);
}).fin((cont, error, result) => {
console.log(error ? error : JSON.stringify(result));
console.log('End');
})
}
//爬去每个Url
function everyPage(callback) {
Then.each(pageUrl, (cont, item) => {
grabPageAsync(item, cont);
}).then((cont, args) => {
pagesHtml = args;
createHtml(cont);
}).fin((cont, error, result) => {
callback(error, result);
})
}
//创建Html文件
function createHtml(callback) {
Then.each(pagesHtml, (cont, item, index) => {
var name = pageUrl[index].substr(pageUrl[index].lastIndexOf('/') + 1);
fs.writeFile(__dirname + '/grapHtml/' + name, item, function(err) {
err ? console.error(err) : console.log('写入成功:' + name);
cont(err, index);
});
}).fin((cont, error, result) => {
callback(error, result);
})
}
// 异步爬取页面HTML
function grabPageAsync(url, callback) {
http.get(url, function(res) {
var bufferHelper = new BufferHelper();
res.on('data', function(chunk) {
bufferHelper.concat(chunk);
});
res.on('end', function() {
console.log('爬取 ' + url + ' 成功');
var fullBuffer = bufferHelper.toBuffer();
var utf8Buffer = iconv.decode(fullBuffer, 'UTF-8');
var html = utf8Buffer.toString()
callback(null, html);
});
}).on('error', function(e) {
// 爬取成功
callback(e, null);
console.log('爬取 ' + url + ' 失败');
});
}
运行:
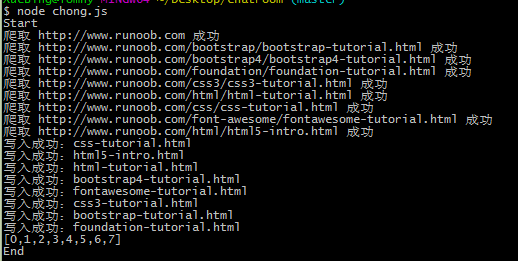
抓取的页面结果:

欢迎拍砖 :)
本文原创转载请注明出处!
node.js爬虫的更多相关文章
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
- Node.js abaike图片批量下载Node.js爬虫1.00版
这个与前作的差别在于地址的不规律性,需要找到下一页的地址再爬过去找. //====================================================== // abaik ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Node.js 爬虫初探
前言 在学习慕课网视频和Cnode新手入门接触到爬虫,说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http.网页分析工具cherrio. 使用http直接获取url路 ...
- Node.js 爬虫,自动化抓取文章标题和正文
持续进行中... 目标: 动态User-Agent模拟浏览器 √ 支持Proxy设置,避免被服务器端拒绝 √ 支持多核模式,发挥多核CPU性能 √ 支持核内并发模式 √ 自动解码非英文站点,避免乱码出 ...
随机推荐
- JavaScript数组去重方法汇总
1.运用数组的特性 1.遍历数组,也遍历辅助数组,找出两个数组中是否有相同的项,若有则break,没有的话就push进去. //第一版本数组去重 function unique(arr){ var r ...
- Eclipse+Spring+SpringMVC+Maven+Mybatis+MySQL+Tomcat项目搭建
---恢复内容开始--- 1. 建表语句及插入数据 CREATE TABLE `book_user` ( user_id INT(11) NOT NULL AUTO_INCREMENT, user_n ...
- Unity3d 2017
Unity3d引擎的新纪元--Unity3d 2017 来源 http://blog.csdn.net/dark00800/article/details/75209544 Unity3d不久之前正式 ...
- Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException):
用windows连接hadoop集群执行mapreduce任务的时候出现以下错误: org.apache.hadoop.security.AccessControlException:Permissi ...
- Python_Python遍历列表的四种方法
方式一: app_list = [1234, 5677, 8899] <!-- lang: python --> for app_id in app_list: <!-- lang: ...
- Spring AOP分析(3) -- CglibAopProxy实现AOP
上文探讨了应用JDK动态代理实现Spring AOP功能的方式,下面将继续探讨Spring AOP功能的另外一种实现方式 -- CGLIB. 首先,来看看类名CglibAopProxy,该类实现了两个 ...
- Socket 的理解及实例
Socket 的理解及实例Socket 的理解TCP/IP要想理解socket首先得熟悉一下TCP/IP协议族, TCP/IP(Transmission Control Protocol/Intern ...
- 前端基于react,后端基于.net core2.0的开发之路(1) 介绍
文章提纲目录 1.前端基于react,后端基于.net core2.0的开发之路(1) 介绍 2.前端基于react,后端基于.net core2.0的开发之路(2) 开发环境的配置,注意事项,后端数 ...
- word建立统一的表格样式
插入一个表格,一般border都是一样粗细,不美观, 这里推荐一种样式如下图(外框和首行都加粗,比较好看) 设置方法: 1.选中表格,上方出现设计选项卡 2.表格样式,点击"新建样式表&qu ...
- C#实现阿拉伯数字(小写金额)到大写中文(大写金额)的转换
/// <summary> /// 本类实现阿拉伯数字到大写中文的转换 /// 该类没有对非法数字进行判别,请事先自己判断数字是否合法 /// </summary& ...