谈谈HashMap与HashTable
谈谈HashMap与HashTable
HashMap
我们一直知道HashMap是非线程安全的,HashTable是线程安全的,可这是为什么呢?先聊聊HashMap吧,想要了解它为什么是非线程安全的,我们得从它的原理着手。
jdk7中的HashMap
HashMap底层维护一个数组,数组中的每一项都是Entry
transient Entry<K,V>[] table;
我们向HashMap放置的对象实际上是放置在Entry数组中
而Map中的key、value则以Entry的形式存放在数组中
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
而这个Entry应该放在数组的哪一个位置上(这个位置通常称为位桶或者hash桶,即hash值相同的Entry会放在同一位置,用链表相连),是通过key的hashCode来计算的。
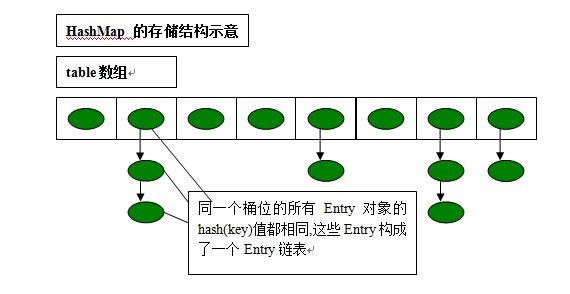
当两个key通过hashcode计算是相同的时候,就会发生hash冲突,HashMap解决hash冲突的办法是使用链表。
简而言之就是,jdk1.7的情况:如果该位置没有对象,则将对象直接放到数组中,如果该位置有对象,顺着存在此对象的链找(Map中不允许存在相同的key和value),如果不存在相同的,第一种情况:如果该链表扩容了,则把对象放入到数组中,原先存放在数组中的数据放置该对象的后面。第二种情况:如果该链表没有扩容,则直接放到链表的最后。如果存在相同的,则进行替换。jdk1.8的情况:如果该位置没有对象,则将对象直接放到数组中,如果该位置有对象,顺着存在此对象的链找(Map中不允许存在相同的key和value),如果不存在相同的,则直接放到链表的最后。如果存在相同的,则进行替换。
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,而在HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
值得注意的是,HashMap中key和value都允许有null值存在,不过只允许一个null的key,可以有多个null值的value。
jdk8中的HashMap
在JDK1.7的部分就只有链表结构,但是由于链表过长的时候查找元素时间较长,在JDK1.8的时候加入了红黑树,当链表超过一定长度之后,链表就会转换成红黑树,便于查找和插入,在最坏的情况下,链表的时间复杂度是O(n),红黑树是O(logn),这样会提高HashMap的效率。
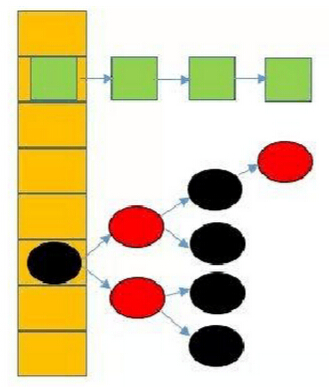
在jdk8中,当同一个hash值得节点数大于8的时候,将不再以链表的形式存储了,而是会调整成一颗红黑树。
static final int TREEIFY_THRESHOLD = 8;
从JDK1.8开始,HashMap的元素是以Node形式存在,主要结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
JDK中Entry的名字变成了Node,原因是和红黑树的实现TreeNode相关联。
可以看一下jdk8中的put方法,跟jdk7相比还是做了很大的改变。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果当前map中无数据,执行resize方法。并且返回n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上就可以了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果当前节点是TreeNode类型的数据,存储的链表已经变为红黑树了,执行putTreeVal方法去存入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//还是链表状态
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断是否要转成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阀值,决定是否扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashMap的多线程不安全
个人觉得HashMap在并发时可能出现的问题主要是两方面,首先如果多个线程同时使用put方法添加元素,而且假设正好存在两个put的key发生了碰撞(hash值一样),那么根据HashMap的实现,这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。第二就是如果多个线程同时检测到元素个数超过数组大小*loadFactor,这样就会发生多个线程同时对Node数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给表,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。
对第二种不安全的情况进行分析:HashMap的死循环
由于插入过程,新插入元素总是插入到头部,源码如下:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
//这里在做插入的过程中,总是将新插入元素放在链表头
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
解析代码:
e=3
Entry<K,V> next = e.next; 保存了3.next也就是7
e.next = newTable[i]; 表示3后面跟着的是null,newTable表示重新建立的一张表
newTable[i] = e; 表示在表的下标的那个位置放的是e(也就是3),也就说下图中的下标为3的地方放了key=3这个对象
e=next;表示e=7了
第二次循环--
Entry<K,V> next = e.next; 保存了7.next也就是5
e.next = newTable[i]; 表示7.next=3了,说明3放到7的尾巴上去了
newTable[i] = e; 表示下图中的下标为3的地方放了key=7这个对象
e=next;表示e=5了
又开启了再一次的循环。
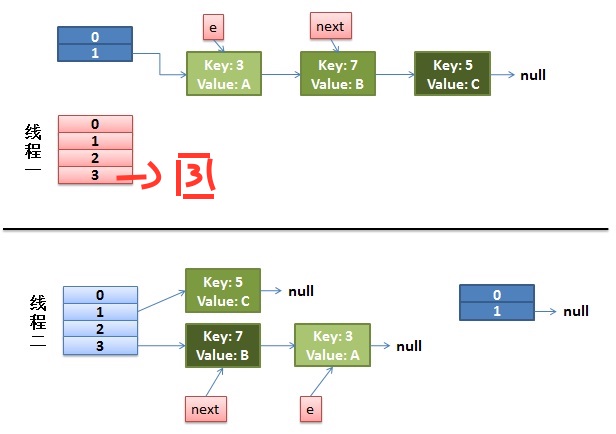
为什么会发生死循环呢?
解析:多线程情况下,多个线程同时检测到对数组进行扩容
当线程1正好插入了3(e=3),并且保存了e.next(也就7)
CPU正好切到了线程2,并且完成了扩容,如上图所示。
之后我们对线程1继续进行操作,把7也插进线程1中,可以看到如下所示:

但是由于受到线程2的影响,e=7,e.next=3,我们后面又得插入3了,然后插入3之后,因为3.next=7,所以我们又插入7,这样就形成了死循环。
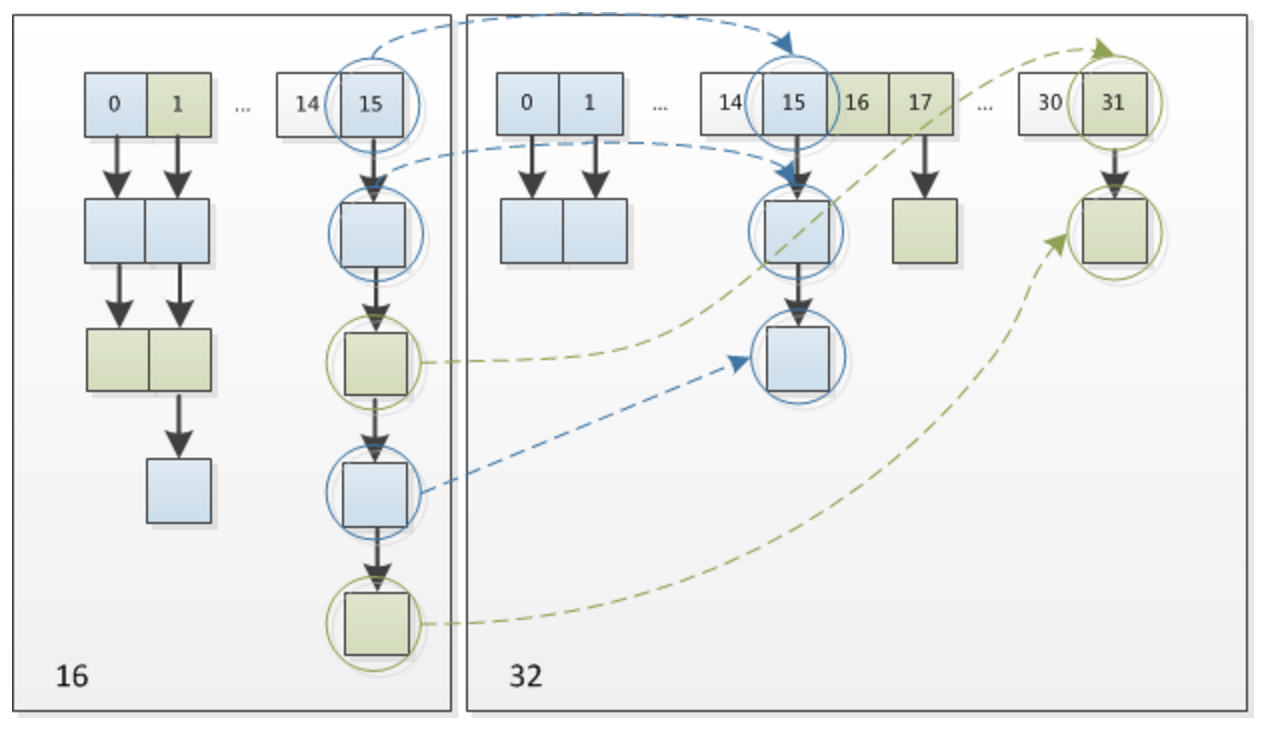
这个问题在JDK1.8中得到了解决,它用了新的索引插入方式
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//还是原索引位置
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//原索引+ oldCap位置
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
由于扩容是在原容量基础上乘以2,那么hash码校验的时候会比原来的多一位,那么只需要比较这个位置是0还是1即可,是1那么就在原索引位置向后位移原容量大小即可,是0就不动。
HashTable
Hashtable是线程安全的,我们可以看看它的源码
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
在主要的函数上都加了synchronize同步关键字,所有线程竞争同一把锁,所以线程安全。
谈谈HashMap与HashTable的更多相关文章
- 谈谈我所理解的HashMap和HashTable
HashMap和HashTable之间的联系和区别如下: 1.HashMap几乎可以等价于Hashtable,但是它们之间继承不同:HashMap extends AbstractMap implem ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- java面试题——HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Clonea ...
- Map集合及与Collection的区别、HashMap和HashTable的区别、Collections、
特点:将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值. Map集合和Collection集合的区别 Map集合:成对出现 (情侣) ...
- HashMap和 Hashtable的比较
Hashtable 和 HashMap的比较 1. HashMap可以接受null(HashMap可以接受为null的键值(key)和值(value), HashTable不可以接受为null的键( ...
- hashMap和hashTable的区别
每日总结,每天进步一点点 hashMap和hashTable的区别 1.父类:hashMap=>AbstractMap hashTable=>Dictionary 2.性能:hashMap ...
- HashMap和HashTable到底哪不同?
HashMap和HashTable有什么不同?在面试和被面试的过程中,我问过也被问过这个问题,也见过了不少回答,今天决定写一写自己心目中的理想答案. 代码版本 JDK每一版本都在改进.本文讨论的Has ...
- java分享第七天-01(Hashmap和Hashtable的区别&Property)
一.Hashmap和Hashtable的区别 1 主要:Hashtable线程安全,同步,效率相对低下 HashMap线程不安全,非同步,效率相对高 2 父类:Hashtable是Dictionary ...
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别
①HashMap的工作原理 HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象.当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算h ...
随机推荐
- python 集合相关操作
集合相关操作 集合是一个无序的,不重复的数据组合,它有着两个主要作用:去重以及关系测试. 去重指的是当把一个列表变成了集合,其中重复的内容就自动的被去掉了 关系测试指的是,测试两组数据之间的交集.差集 ...
- Spring框架之IOC(控制反转)
[TOC] 第一章Spring框架简介 IOC(控制反转)和AOP(面向方面编程)作为Spring框架的两个核心,很好地实现了解耦合.所以,简单来说,Spring是一个轻量级的控制反转(IoC)和面向 ...
- xssless - 自动化的XSS payload攻击器
XSSLESS 一个用Python编写的自动化XSS 负载(payload)攻击器 用法: 记录请求 并结合Burp proxy 选择你想生成的请求,然后右键选择“保存项目” 使用xssless生成你 ...
- 【Windows 10 应用开发】自定义快捷键
上一篇鸟文中,老周通过史无前例的代码向各位 demo 了访问键的用法(即 Alt + 某某).不过,大伙伴们一定会发现,访问键毕竟限制较大,不太灵活,也不好发挥,于是就需要自定义快捷键了. 其实,自定 ...
- docker 内部组件结构 -- docker daemon, container,runC
Docker, Containerd, RunC : 从 Docker 1.11 开始, docker 容器运行已经不是简单地通过 Docker Daemon 来启动, 而是集成了Container, ...
- 常用DOM API
Node Node是一个接口,中文叫节点,很多类型的DOM元素都是继承于它,都共享着相同的基本属性和方法.常见的Node有 element,text,attribute,comment,documen ...
- centos7下创建数据库和用户
首先需要在centos系统下安装好mysql,这个我已经安装好了,这里就不把过程贴出来了. 第一步:使用root用户登录到mysql数据库: 第二步:创建一个mysql数据库.当第一步登录成功后,便会 ...
- SSH连接不上CentOS 主机配置文件导致的原因的解决方法
一.CentOS之SSH的安装与配置 SSH 为 Secure Shell 的缩写,由 IETF 的网络工作小组(Network Working Group)所制定SSH 为建立在应用层和传输层基础上 ...
- Linux编程之select
select系统调用的的用途是:在一段指定的时间内,监听用户感兴趣的文件描述符上可读.可写和异常等事件. select 机制的优势 为什么会出现select模型? 先看一下下面的这句代码: int i ...
- iOS 转场动画探究(一)
什么是转场动画: 转场动画说的直接点就是你常见的界面跳转的时候看到的动画效果,我们比较常见的就是控制器之间的Push和Pop,还有Present和Dismiss的时候设置一下系统给我们的modalTr ...