【JDK1.8】JDK1.8集合源码阅读——IdentityHashMap
一、前言
今天我们来看一下本次集合源码阅读里的最后一个Map——IdentityHashMap。这个Map之所以放在最后是因为它用到的情况最少,也相较于其他的map来说比较特殊。就笔者来说,到目前为止还没有用到过它 ┐(゚~゚)┌。它的罕见与它的用途有关,当时的Map设计者是这么说的:
This class is designed for use only in the rare cases wherein reference-equality semantics are required.
这个类仅用于需要引用相等的罕见情况。
A typical use of this class is topology-preserving object graph transformations, such as serialization or deep-copying.
该类一个典型的用途是拓扑保存对象图的转换,比如序列化或者深度拷贝
Another typical use of this class is to maintain proxy objects. For example, a debugging facility might wish to maintain a proxy object for each object in the program being debugged.
这个类的另一个典型用途是维护代理对象。 例如,调试工具可能希望为正在调试的程序中的每个对象维护一个代理对象
上面提到,这个Map采用的是引用相等的情况,即内存地址相同。我们来看一下它用法:
public static void main(String[] args) {
IdentityHashMap<String, Integer> map = new IdentityHashMap<>();
map.put("Hello " + "World", 1);
map.put("Hello World", 2);
map.put(new String("Hello World"), 3);
map.put(null, 4);
map.put(null, 5);
System.out.println(map);
}
上面的输出是:
{null=5, Hello World=2, Hello World=3}
因为采用的是引用相等来比较,所以1和2是相等的(常量池),对于key相同,用新的value替换,而3是用new在堆中申请的,所以与前面的不同。至于后面的null,是为了说明IdentityHashMap可以存放null。
二、IdentityHashMap的数据结构
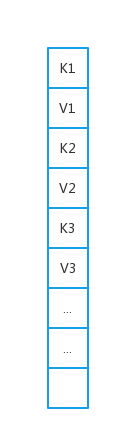
IdentityHashMap的结构与HashMap等不同,其实就是一个Object[]数组,数组的前一位存放Key,后面一个位置就存放它对应的Value。
三、IdentityHashMap源码阅读
3.1 类的继承关系
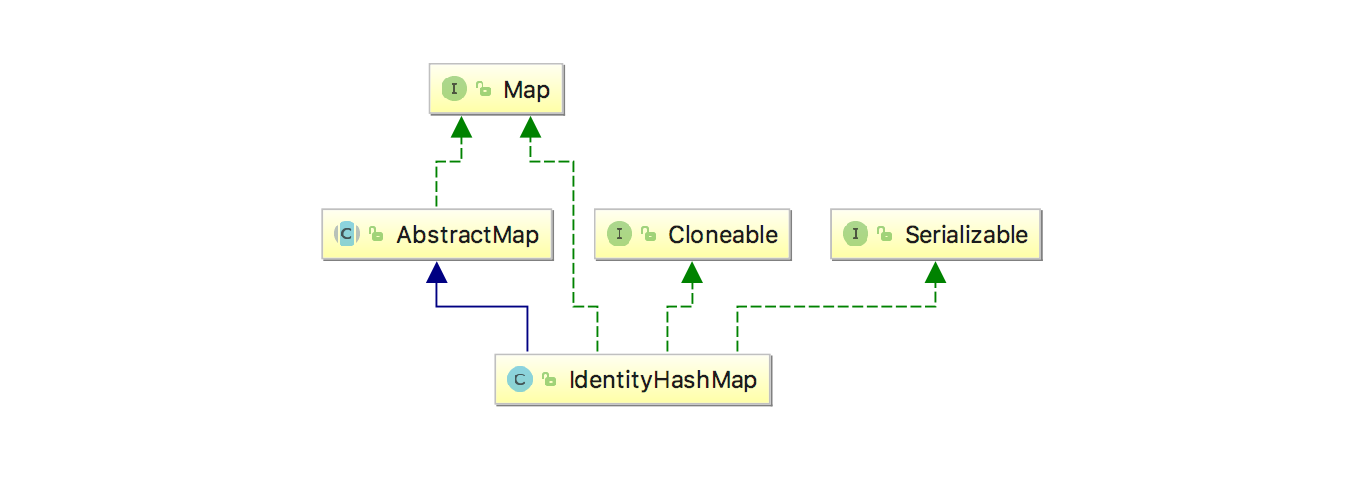
可以看到,继承关系和HashMap一样,没有什么其他特别的地方。
3.2 IdentityHashMap的成员变量
// 初始化容量,存放最大的数量为21,填充因子是2/3(后面代码可以看到)
private static final int DEFAULT_CAPACITY = 32;
//最小容量,实际最大存放容量为2,记住2/3
private static final int MINIMUM_CAPACITY = 4;
//最大容量2^29,然而实际上存放最大的量为MAXIMUM_CAPACITY-1,后面解释
private static final int MAXIMUM_CAPACITY = 1 << 29;
// 存放key-value的表
transient Object[] table;
//map里存放的key-value数量
int size;
//用于统计map修改次数的计数器,用于fail-fast抛出ConcurrentModificationException
transient int modCount;
//对于存放null的情况,
static final Object NULL_KEY = new Object();
//key、value的视图
private transient Set<Map.Entry<K,V>> entrySet;
值得注意的是:虽然成员变量里没有声明填充因子,但是从IdentityHashMap的代码里可以看到它的填充因子是2/3,并且所有的容量都要保证是2的幂次。
3.3 IdentityHashMap的构造函数
3.3.1 IdentityHashMap()
public IdentityHashMap() {
init(DEFAULT_CAPACITY);
}
//申请initCapacity两倍的空间
private void init(int initCapacity) {
table = new Object[2 * initCapacity];
}
说明:申请两倍的空间很好理解,因为key-value是放一个数组里的,所以是空间是存储键值对数量的两倍
3.3.2 IdentityHashMap(int expectedMaxSize)
public IdentityHashMap(int expectedMaxSize) {
// 最大数量小于0,抛出异常
if (expectedMaxSize < 0)
throw new IllegalArgumentException("expectedMaxSize is negative: "
+ expectedMaxSize);
init(capacity(expectedMaxSize));
}
// 根据给定的expectedMaxSize计算合适的容量,必为2的幂次
private static int capacity(int expectedMaxSize) {
return
(expectedMaxSize > MAXIMUM_CAPACITY / 3) ? MAXIMUM_CAPACITY :
(expectedMaxSize <= 2 * MINIMUM_CAPACITY / 3) ? MINIMUM_CAPACITY :
Integer.highestOneBit(expectedMaxSize + (expectedMaxSize << 1));
}
//获取i最高位的int值
public static int highestOneBit(int i) {
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
这里的重点在于capacity和highestOneBit的计算,对于highestOneBit的逻辑其实与笔者之前在HashMap源码解析tableSizeFor方法类似,这里可以再说一遍:
|是或运算符,比如说0100 | 0011 = 0111。>>则是右移运算符,左边的用原有标志位补充(负数为1,正数为0),比如说-3:1111 1101 >> 2 = 1111 1111(int 其实有32位,这里偷懒,大家懂就行),而>>>是无符号右移,左边用0补全
75的补码是0100 1011,0100 1011 >> 1 = 0010 0101, 然后0100 1011 | 0010 0101 = 0110 1111,然后再把 0110 1111无符号右移两位,0110 1111 >> 2 = 0001 1011,再进行或运算:0001 1011 | 0110 1111 = 0111 1111。至此,我们可以发现操作就是把最高位及其以下的位数都变为1 ,后面进行到16是因为int为32位,所以到16的时候,所有的位数都遍历完了,最后的i - (i >>> 1)是返回i对应的二进制最高位数的整数,比如说12返回8,8返回8。
那么capacity(int expectedMaxSize)方法的逻辑是:
- expectedMaxSize > MAXIMUM_CAPACITY / 3,则直接用最大的容量
- expectedMaxSize < = 2 * MINIMUM_CAPACITY / 3,则直接用最小容量
- 2 * MINIMUM_CAPACITY / 3 ~ MAXIMUM_CAPACITY / 3之间,则大于且最接近3/2的expectedMaxSize的2的幂次的容量
3.3.3 IdentityHashMap(Map<? extends K, ? extends V> m)
public IdentityHashMap(Map<? extends K, ? extends V> m) {
// 对原有的size进行一点扩容
this((int) ((1 + m.size()) * 1.1));
putAll(m);
}
// 循环map将值放进去
public void putAll(Map<? extends K, ? extends V> m) {
int n = m.size();
if (n == 0)
return;
if (n > size)
resize(capacity(n));
for (Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
3.4 IdentityHashMap的重要方法
3.4.1 maskNull(Object key) & unmaskNull(Object key)
// 如果key为null,则返回NULL_KEY回去,否则返回key
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}
// 对上面的逆转化,用于返回key的时候
static final Object unmaskNull(Object key) {
return (key == NULL_KEY ? null : key);
}
说明:NULL_KEY的存在是为了解决key为null的情况,因为如果为null,key还是要存一个值,否则会破坏数组的存储规则。
3.4.2 get(Object key)
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
//计算key对应的下标位置。
int i = hash(k, len);
while (true) {
Object item = tab[i];
// 引用相等,返回其value
if (item == k)
return (V) tab[i + 1];
// 为null,说明未插入,则value肯定也为null(插入null,实际是NULL_KEY)
if (item == null)
return null;
//不相等且不为null,寻找下一个index,循环查找
i = nextKeyIndex(i, len);
}
}
值得注意的是: 在没有key存在的情况下,退出while循环的关键是必须有一个null,所以前面提到MAXIMUM_CAPACITY实际存放的容量是MAXIMUM_CAPACITY - 1
get的逻辑还是很简单,里面有两个方法要更进一步的研究,首先需要思考的是,如何保证获得的总是key的位置,而不是value的下标:
private static int hash(Object x, int length) {
//返回原来自带的哈希值,不论是否重写了hashCode()
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
对于((h << 1) - (h << 8)) = h * -254,不知道为什么源码注释上写着乘以-127,有清楚的园友可以跟我说一下。总之, -254 * h得到的肯定为偶数。最后的& (length - 1)就是在数组 0 - (length-1) 之中取模,获取它的下标位置,由于length肯定为2的幂次,所以length -1的二进制补码肯定是011111111这种,在与偶数进行&运算后得到的结果肯定也是偶数,从而保证了得到的都是key的位置,但是为什么要乘以-254笔者还不是很清楚。
// 每次加2,寻找下一个位置,如果 >= len,则从头开始找
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}
可以把数组想象成一个闭环,头尾相接的逻辑结构。
3.4.3 put(K key, V value)
public V put(K key, V value) {
// null的key转成Object(NULL_KEY)
final Object k = maskNull(key);
retryAfterResize: for (;;) {
final Object[] tab = table;
final int len = tab.length;
// 同样先计算数组下标位置
int i = hash(k, len);
// 先在数组里找是否有相同的key,找到则替换
for (Object item; (item = tab[i]) != null;
i = nextKeyIndex(i, len)) {
if (item == k) {
@SuppressWarnings("unchecked")
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
}
}
// 没有找到则执行插入,先存放的键值对数量+1
final int s = size + 1;
//如果3*s > len,则进行扩容,扩容后的大小为 2 * len
if (s + (s << 1) > len && resize(len))
continue retryAfterResize;
modCount++;
tab[i] = k;
tab[i + 1] = value;
size = s;
return null;
}
}
还记得之前说的填充因子是2/3吗?因为len在调用init()的时候,是2倍的量,实际能存储的键值对我们可以用maxSize表示 2 * maxSize = len,所以可以得出填充因子是2/3。
我们再来看一下resize()
private boolean resize(int newCapacity) {
// 新的length是原来的两倍
int newLength = newCapacity * 2;
Object[] oldTable = table;
int oldLength = oldTable.length;
// 如果已经到了最大的容量,则扩容失败
if (oldLength == 2 * MAXIMUM_CAPACITY) {
// 如果已经到了最大的容量,(留一个给null,不然不能退出循环)
if (size == MAXIMUM_CAPACITY - 1)
throw new IllegalStateException("Capacity exhausted.");
return false;
}
if (oldLength >= newLength)
return false;
//下面就是循环旧的table,然后插入值到新的里面
Object[] newTable = new Object[newLength];
for (int j = 0; j < oldLength; j += 2) {
Object key = oldTable[j];
if (key != null) {
Object value = oldTable[j+1];
oldTable[j] = null;
oldTable[j+1] = null;
int i = hash(key, newLength);
while (newTable[i] != null)
i = nextKeyIndex(i, newLength);
newTable[i] = key;
newTable[i + 1] = value;
}
}
table = newTable;
return true;
}
可以看到和其他的Map一样,扩容的效率很差,所以可以的话,我们在每次初始化的时候最好都指定合适的容量,来提高性能。
3.4.4 remove(Object key)
最后再来看看remove方法:
public V remove(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
// 计算下标
int i = hash(k, len);
while (true) {
Object item = tab[i];
// 如果下标所在的值与key相同,则进入删除
if (item == k) {
modCount++;
// 所存的键值对数量-1
size--;
@SuppressWarnings("unchecked")
V oldValue = (V) tab[i + 1];
//引用设置为null,以便GC
tab[i + 1] = null;
tab[i] = null;
// 删除后的后续处理,把后挪的元素移到前面来
closeDeletion(i);
return oldValue;
}
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}
remove的逻辑很简单,找到之后,设置null,然后用closeDeletion(i)调整元素位置。
private void closeDeletion(int d) {
Object[] tab = table;
int len = tab.length;
Object item;
// 从删除的d开始向下找key,知道找到null停止,然后把后一个移到前面
for (int i = nextKeyIndex(d, len); (item = tab[i]) != null;
i = nextKeyIndex(i, len) ) {
int r = hash(item, len);
if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i)) {
tab[d] = item;
tab[d + 1] = tab[i + 1];
tab[i] = null;
tab[i + 1] = null;
d = i;
}
}
}
其中if的判断重点分析一下,实际存放的位置i 和 理想情况下存放的位置 r,理论上存在三种情况:
- i < r,即 r 在i 的后面。
- i > r,即 r 在 i 的前面。
- i = r,r恰好放在了自己合适的位置。
那么
- 针对情况一:我们可以想一想为什么r本该放置的位置却移到了前面去呢。根据
put()的源码来看,应该是原本放r的位置已经有的值,所以nextKeyIndex又从table的0开始循环,导致实际存放的位置i < 理想情况下存放的位置 r。那么此时的 d应该处于什么位置?- d恰好占据了r的位置,且d在数组末尾,即 r = d,于是被d占位置的老r,被挤到了数组前头放在了i的位置。
- r < d,即r在d的前面,且d在数组末尾,于是r、d位置都被占的老r被挤到了数组前头i的位置
- d在数组开头,但是r很不凑巧,在理想的位置r及其后面一直都被人占着,直到绕一圈跑到了d后面,即 d < i
- 针对情况二:相对简单一些,原本应该放在前面的r却移到了后面i的位置,此时的数组的长度足够,不用考虑到重新回到前面的情况如下:
- r = d,d占据了r的位置,后移到了i
- r < d,此时r的位置被其他占了,紧接着d也被占了,所以到了i。
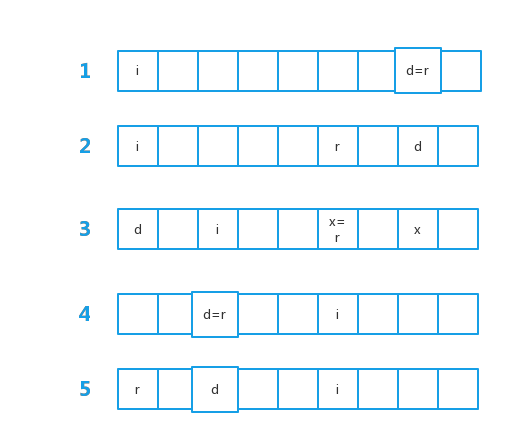
综上的话就是if上的情况,至于d = i = r 的情况,笔者认为至于数组长度为2的时候才会出现,但是规定最小的长度是8,所以应该不会出现这种情况。
四、总结
和其他的Map一样,扩容的代价比较高,所以最好创建一个合适大小的map。另一方面,对集合视图的迭代需要的时间与散列表中桶的数量成正比,所以如果你关注迭代器的性能和内存使用,容量值不能设置的太大。另外有解读不对的地方可以留言指正,最后谢谢各位园友观看,与大家共同进步!
【JDK1.8】JDK1.8集合源码阅读——IdentityHashMap的更多相关文章
- 【JDK1.8】Java 8源码阅读汇总
一.前言 万丈高楼平地起,相信要想学好java,仅仅掌握基础的语法是远远不够的,从今天起,笔者将和园友们一起阅读jdk1.8的源码,并将阅读重点放在常见的诸如collection集合以及concu ...
- java1.7集合源码阅读: Stack
Stack类也是List接口的一种实现,也是一个有着非常长历史的实现,从jdk1.0开始就有了这个实现. Stack是一种基于后进先出队列的实现(last-in-first-out (LIFO)),实 ...
- java1.7集合源码阅读: Vector
Vector是List接口的另一实现,有非常长的历史了,从jdk1.0开始就有Vector了,先于ArrayList出现,与ArrayList的最大区别是:Vector 是线程安全的,简单浏览一下Ve ...
- 【JDK1.8】JDK1.8集合源码阅读——总章
一.前言 今天开始阅读jdk1.8的集合部分,平时在写项目的时候,用到的最多的部分可能就是Java的集合框架,通过阅读集合框架源码,了解其内部的数据结构实现,能够深入理解各个集合的性能特性,并且能够帮 ...
- 【JDK1.8】JDK1.8集合源码阅读——HashMap
一.前言 笔者之前看过一篇关于jdk1.8的HashMap源码分析,作者对里面的解读很到位,将代码里关键的地方都说了一遍,值得推荐.笔者也会顺着他的顺序来阅读一遍,除了基础的方法外,添加了其他补充内容 ...
- 【JDK1.8】JDK1.8集合源码阅读——ArrayList
一.前言 在前面几篇,我们已经学习了常见了Map,下面开始阅读实现Collection接口的常见的实现类.在有了之前源码的铺垫之后,我们后面的阅读之路将会变得简单很多,因为很多Collection的结 ...
- 【JDK1.8】JDK1.8集合源码阅读——LinkedList
一.前言 这次我们来看一下常见的List中的第二个--LinkedList,在前面分析ArrayList的时候,我们提到,LinkedList是链表的结构,其实它跟我们在分析map的时候讲到的Link ...
- Java集合源码阅读之HashMap
基于jdk1.8的HashMap源码分析. 引用于:http://blog.stormma.me/2017/05/31/Java%E9%9B%86%E5%90%88%E6%BA%90%E7%A0%81 ...
- 【JDK1.8】JDK1.8集合源码阅读——TreeMap(一)
一.前言 在前面两篇随笔中,我们提到过,当HashMap的桶过大的时候,会自动将链表转化成红黑树结构,当时一笔带过,因为我们将留在本章中,针对TreeMap进行详细的了解. 二.TreeMap的继承关 ...
随机推荐
- 对Numpy广播操作的理解
1.首先检查两个矩阵维数是否相同,若不同,对维数少的补一.注意这里的维数不是指n行d列中的n和d的值,对于这种情况维数就是2.若一个两维的矩阵(n,d)和一个一维的数组(m,)相乘,补一操作就是将那个 ...
- 暑假练习赛 007 B - Weird Cryptography
Weird Cryptography Description standard input/outputStatements Khaled was sitting in the garden unde ...
- 第三章 CUDA设备相关
这章介绍了与CUDA设备相关的参数,并给出了了若干用于查询参数的函数. 章节代码(已合并): #include <stdio.h> #include "cuda_runtime. ...
- D3.js使用过程中的常见问题(D3版本D3V4)
目录 一.学习D3我必须要学习好SVG矢量图码? 二.如何理解D3给Dom节点绑定数据时的Update.Enter和Exit模式 三.D3绑定数据时用datum与data有什么不一样? 四.SVG图中 ...
- 玩玩Qt(一)
最近在看一些关于游戏引擎的东西,本来是有几个游戏的小点子,其实实现起来还挺麻烦的,想找个游戏引擎看看能不能码起来.辗转之后发现了很多2D引擎,其中国产的要数cocos2dx用的好像是比较广泛,但是好多 ...
- c++学习笔记---06--- 函数的重载
函数的重载 函数的重载 C++ 里的函数重载(overloading)机制比我们此前见到的东西都高深,这种语言的灵活性和强大功能在它身上体现得淋漓尽致. 所谓函数重载的实质就是用同样的名字再定义一个有 ...
- ldap数据库--ODSEE--安装
在安装之前最好查看一下服务器硬件是否满足要求,是否需要更改一些系统配置来达到使用ldap数据库的最有性能.实际使用的ldap数据库是oracle的产品,DS70即ODSEE. 安装环境:solaris ...
- Python 面向对象基础知识
面向对象基础知识 1.什么是面向对象编程? - 以前使用函数 - 类 + 对象 2.什么是类什么是对象,又有什么关系? class 类: def 函数1(): pass def 函数2(): pass ...
- [小程序开发] 微信小程序内嵌网页web-view开发教程
为了便于开发者灵活配置小程序,微信小程序开放了内嵌网页能力.这意味着小程序的内容不再局限于pages和large,我们可以借助内嵌网页丰富小程序的内容.下面附上详细的开发教程(含视频操作以及注意事项) ...
- 免费好用的阿里云云盾证书服务(https证书)申请步骤
推荐一个免费的阿里云产品:云盾证书(https证书) 为了能让非专业人士看懂,同样尽量用直白的话,一般来说:当你个人需要建立网站,或者公司要建立官网.商城,通常需要先购买服务器或云主机,虚拟空间,然后 ...