【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点。当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等。可见,保证HDFS中的数据平衡是非常重要的。
在Hadoop中,包含一个Balancer程序,通过运行这个程序,可以使得HDFS集群达到一个平衡的状态,使用这个程序的命令如下:
sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
Hadoop的开发人员在开发Balancer程序的时候,遵循了以下几点原则:
1. 在执行数据重分布的过程中,必须保证数据不能出现丢失,不能改变数据的备份数,不能改变每一个rack中所具备的block数量。
2. 系统管理员可以通过一条命令启动数据重分布程序或者停止数据重分布程序。
3. Block在移动的过程中,不能暂用过多的资源,如网络带宽。
4. 数据重分布程序在执行的过程中,不能影响name node的正常工作。
基于这些基本点,目前Hadoop数据重分布程序实现的逻辑流程如下图所示:
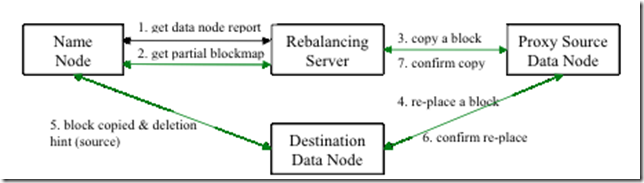
Rebalance程序作为一个独立的进程与name node进行分开执行。
1 Rebalance Server从Name Node中获取所有的Data Node情况:每一个Data Node磁盘使用情况。
2 Rebalance Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据。并且从Name Node中获取需要移动的数据分布情况。
3 Rebalance Server计算出来可以将哪一台机器的block移动到另一台机器中去。
4,5,6 需要移动block的机器将数据移动的目的机器上去,同时删除自己机器上的block数据。
7 Rebalance Server获取到本次数据移动的执行结果,并继续执行这个过程,一直没有数据可以移动或者HDFS集群以及达到了平衡的标准为止。
Hadoop现有的这种Balancer程序工作的方式在绝大多数情况中都是非常适合的。
现在我们设想这样一种情况:
1 数据是3份备份。
2 HDFS由2个rack组成。
3 2个rack中的机器磁盘配置不同,第一个rack中每一台机器的磁盘空间为1TB,第二个rack中每一台机器的磁盘空间为10TB。
4 现在大多数数据的2份备份都存储在第一个rack中。
在这样的一种情况下,HDFS级群中的数据肯定是不平衡的。现在我们运行Balancer程序,但是会发现运行结束以后,整个HDFS集群中的数据依旧不平衡:rack1中的磁盘剩余空间远远小于rack2。
这是因为Balance程序的开发原则1导致的。
简单的说,就是在执行Balancer程序的时候,不会将数据中一个rack移动到另一个rack中,所以就导致了Balancer程序永远无法平衡HDFS集群的情况。
针对于这种情况,可以采取2中方案:
1 继续使用现有的Balancer程序,但是修改rack中的机器分布。将磁盘空间小的机器分叉到不同的rack中去。
2 修改Balancer程序,允许改变每一个rack中所具备的block数量,将磁盘空间告急的rack中存放的block数量减少,或者将其移动到其他磁盘空间富余的rack中去。
更多关于Hadoop的文章,可以参考:http://www.cnblogs.com/gpcuster/tag/Hadoop/
【转载】漫谈HADOOP HDFS BALANCER的更多相关文章
- 【转】HADOOP HDFS BALANCER介绍及经验总结
转自:http://www.aboutyun.com/thread-7354-1-1.html 集群平衡介绍 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加 ...
- HADOOP HDFS BALANCER介绍及经验总结(转)
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决? 2.尽量不在NameNode上执行start-balancer.sh的原因是什么? 集群平衡介绍 Hadoop的HDFS集群非常 ...
- Hadoop记录-HDFS balancer配置
HDFS balancer配置(可通过CM配置)dfs.datanode.balance.max.concurrent.moves 并行移动的block数量,默认5 dfs.datanode.bala ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- Hadoop HDFS 中的一些常用命令
转载自:hadoop HDFS常用文件操作命令 命令基本格式: hadoop fs -cmd < args > 1.ls hadoop fs -ls / 列出hdfs文件系统根目录下的目录 ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- sudo -u hdfs hdfs balancer出现异常 No lease on /system/balancer.id
16/06/02 20:34:05 INFO balancer.Balancer: namenodes = [hdfs://dlhtHadoop101:8022, hdfs://dlhtHadoop1 ...
- hadoop错误FATAL org.apache.hadoop.hdfs.server.namenode.NameNode Exception in namenode join java.io.IOException There appears to be a gap in the edit log
错误: FATAL org.apache.hadoop.hdfs.server.namenode.NameNode Exception in namenode join java.io.IOExcep ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
随机推荐
- [基础规范]JavaBeans规范
本文来自维基百科:http://en.wikipedia.org/wiki/JavaBeans#JavaBean_conventions JavaBeans是Java语言中能够反复使用的软件组件,它们 ...
- 在非controllers中获取httpServletRequest
HttpServletRequest request = ((ServletRequestAttributes)RequestContextHolder.getRequestAttributes()) ...
- oracle 主键自增 设置----杜恩德
<div id="topicList"> <div class="forFlow"> <div class = "pos ...
- C#设计模式之二十二访问者模式(Visitor Pattern)【行为型】
一.引言 今天我们开始讲"行为型"设计模式的第九个模式,该模式是[访问者模式],英文名称是:Visitor Pattern.如果按老规矩,先从名称上来看看这个模式,我根本不能获 ...
- 【二十六】php之文件编程
1.获取文件的相关信息 fopen.fstat.fclose(打开文件.获取文件相关信息.关闭文件) filesize.filectime.filemtime.fileatime(文件大小.上次cha ...
- Vue购物车实例
<div class="buyCarBox" id="buyCarBox" v-cloak> <div class="haveClo ...
- Linux权限分析
我看过网上的一些有关Linux的权限分析,有些说的不够清楚,另外一些说的又太复杂.这里我尽量简单.清楚的把Linux权限问题阐述明白,Linux权限没有那么复杂. Linux权限问题要区分文件权限和目 ...
- Mac shell笔记
用来自动执行一些前端发布的操作. 脚本: # webReleasePath用来发布的目录,webRevisionPath是开发的目录 webReleasePath='/Users/lufeng/Doc ...
- ubuntu14.04 解决屏幕亮度无法调节的问题
sudo gedit /etc/default/grub 在打开文件中找到 GRUB_CMDLINE_LINUX="" 改成 GRUB_CMDLINE_LINUX="ac ...
- [置顶]
xamarin android使用zxing扫描二维码
好久没写了,这片文章篇幅不长,概述一下在xamarin android中用 ZXing.Net.Mobile库扫描二维码读取url的示例.扫码支付,扫码登录,App上各种各样的扫码,好像没个扫码的就有 ...