机器学习 —— 基础整理(八)循环神经网络的BPTT算法步骤整理;梯度消失与梯度爆炸
网上有很多Simple RNN的BPTT(Backpropagation through time,随时间反向传播)算法推导。下面用自己的记号整理一下。
我之前有个习惯是用下标表示样本序号,这里不能再这样表示了,因为下标需要用做表示时刻。
典型的Simple RNN结构如下:
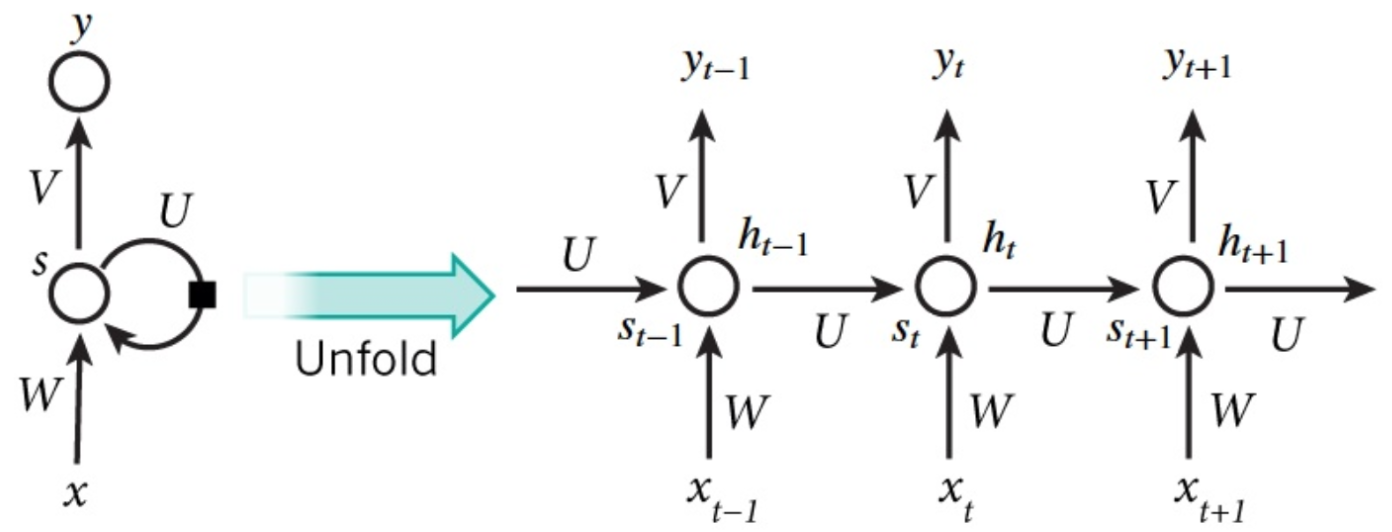
图片来源:[3]
约定一下记号:
输入序列 $\textbf x_{(1:T)} =(\textbf x_1,\textbf x_2,...,\textbf x_T)$ ;
标记序列 $\textbf y_{(1:T)} =(\textbf y_1,\textbf y_2,...,\textbf y_T)$ ;
输出序列 $\hat{\textbf y}_{(1:T)} =(\hat{\textbf y}_1,\hat{\textbf y}_2,...,\hat{\textbf y}_T)$ ;
隐层输出 $\textbf h_t\in\mathbb R^H$ ;
隐层输入 $\textbf s_t\in\mathbb R^H$ ;
过softmax之前输出层的输出 $\textbf z_t$ 。
(一)Simple RNN的BPTT
那么对于Simple RNN来说,前向传播过程如下(省略了偏置):
$$\textbf s_t=U\textbf h_{t-1}+W\textbf x_t$$
$$\textbf h_t=f (\textbf s_t)$$
$$\textbf z_t=V\textbf h_t$$
$$\hat{\textbf y}_t=\text{softmax}(\textbf z_t)$$
其中 $f$ 是激活函数。注意,三个权重矩阵在时间维度上是共享的。这可以理解为:每个时刻都在执行相同的任务,所以是共享的。
既然每个时刻都有输出 $\hat{\textbf y}_t$ ,那么相应地,每个时刻都会有损失。记 $t$ 时刻的损失为 $\mathcal L_t$ ,那么对于样本 $\textbf x_{(1:T)}$ 来说,损失 $\mathcal L$ 为
$$\mathcal L=\sum_{t=1}^T\mathcal L_t$$
使用交叉熵损失函数,那么
$$\mathcal L_t=-\textbf y_t^{\top}\log\hat{\textbf y}_t$$
一、 $\mathcal L$ 对 $V$ 的梯度
下面首先求取 $\mathcal L$ 对 $V$ 的梯度。根据chain rule:$\dfrac{\partial \textbf z}{\partial \textbf x}=\dfrac{\partial \textbf y}{\partial \textbf x}\dfrac{\partial \textbf z}{\partial \textbf y}$ 、$\dfrac{\partial z}{\partial X_{ij}}=(\dfrac{\partial z}{\partial\textbf y})^{\top}\dfrac{\partial\textbf y}{\partial X_{ij}}$ ,有
$$\frac{\partial \mathcal L_t}{\partial V_{ij}}=(\frac{\partial \mathcal L_t}{\partial\textbf z_t})^{\top}\frac{\partial\textbf z_t}{\partial V_{ij}}$$
这里其实和BP是一样的,前一项相当于是误差项 $\delta$ ,后一项等于
$$\frac{\partial \textbf z_t}{\partial V_{ij}}=\frac{\partial V\textbf h_t}{\partial V_{ij}}=(0,...,[\textbf h_t]_j,...,0)^{\top}$$
只有第 $i$ 行非零,$[\textbf h_t]_j$ 是指 $\textbf h_t$ 的第 $j$ 个元素。参考上一篇博客的结尾部分,可知前一项等于
$$\frac{\partial \mathcal L_t}{\partial\textbf z_t}=\hat{\textbf y}_t-\textbf y_t$$
所以有
$$\frac{\partial \mathcal L_t}{\partial V_{ij}}=[\hat{\textbf y}_t-\textbf y_t]_i[\textbf h_t]_j$$
从而有
$$\frac{\partial \mathcal L_t}{\partial V}=(\hat{\textbf y}_t-\textbf y_t)\textbf h_t^{\top}=(\hat{\textbf y}_t-\textbf y_t)\otimes \textbf h_t$$
向量外积是矩阵的Kronecker积在向量下的特殊情况。因此,
$$\frac{\partial \mathcal L}{\partial V}=\sum_{t=1}^T(\hat{\textbf y}_t-\textbf y_t)\otimes \textbf h_t$$
二、 $\mathcal L$ 对 $U$ 的梯度
继续求取 $\mathcal L$ 对 $U$ 的梯度。在求 $\frac{\partial \mathcal L_t}{\partial U}$ 时,需要注意到一个事实,那就是不光 $t$ 时刻的隐状态与 $U$ 有关,之前所有时刻的隐状态都与 $U$ 有关。
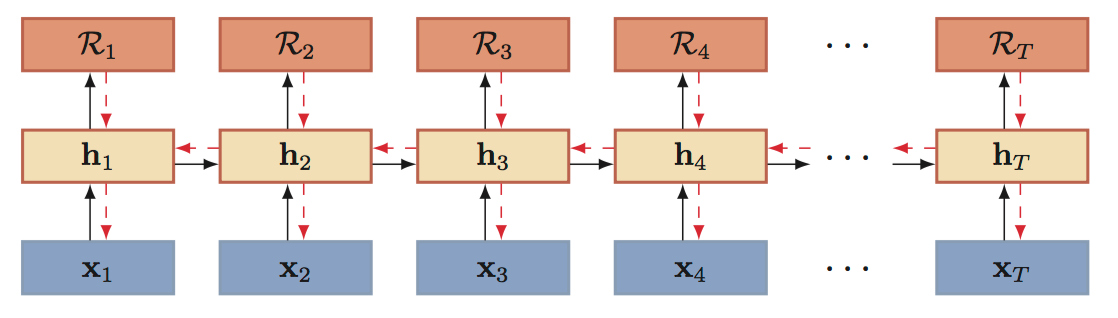
图片来源:[1]
所以,根据chain rule:
$$\frac{\partial \mathcal L_t}{\partial U}=\sum_{k=1}^t\frac{\partial\textbf s_k}{\partial U}\frac{\partial \mathcal L_t}{\partial\textbf s_k}$$
下面使用和之前类似的套路求解:先求对一个矩阵一个元素的梯度。
$$\frac{\partial \mathcal L_t}{\partial U_{ij}}=\sum_{k=1}^t(\frac{\partial \mathcal L_t}{\partial\textbf s_k})^{\top}\frac{\partial\textbf s_k}{\partial U_{ij}}$$
前一项先定义为 $\delta_{t,k}=\dfrac{\partial \mathcal L_t}{\partial\textbf s_k}$ ,对于后一项:
$$\frac{\partial\textbf s_k}{\partial U_{ij}}=\frac{\partial(U\textbf h_{k-1}+W\textbf x_k)}{\partial U_{ij}}=(0,...,[\textbf h_{k-1}]_j,...,0)^{\top}$$
只有第 $i$ 行非零,$[\textbf h_{k-1}]_j$ 是指 $\textbf h_{k-1}$ 的第 $j$ 个元素。现在来求解 $\delta_{t,k}=\dfrac{\partial \mathcal L_t}{\partial\textbf s_k}$ ,使用上篇文章求 $\delta^{(l)}$ 的套路:
$$\begin{aligned}\delta_{t,k}&=\frac{\partial \mathcal L_t}{\partial\textbf s_k}\\&=\frac{\partial \textbf h_k}{\partial\textbf s_{k}}\frac{\partial \textbf s_{k+1}}{\partial\textbf h_{k}}\frac{\partial \mathcal L_t}{\partial\textbf s_{k+1}}\\&=\text{diag}(f'(\textbf s_k))U^{\top}\delta_{t,k+1}\\&=f'(\textbf s_{k})\odot (U^{\top}\delta_{t,k+1})\end{aligned}$$
一种特殊情况是当 $\delta_{t,t}$ ,有
$$\begin{aligned}\delta_{t,t}&=\frac{\partial \mathcal L_t}{\partial\textbf s_t}\\&=\frac{\partial \textbf h_t}{\partial\textbf s_t}\frac{\partial \textbf z_t}{\partial\textbf h_t}\frac{\partial \mathcal L_t}{\partial\textbf z_t}\\&=\text{diag}(f'(\textbf s_{t}))V^{\top}(\hat{\textbf y}_t-\textbf y_t)\\&=f'(\textbf s_{t})\odot (V^{\top}(\hat{\textbf y}_t-\textbf y_t))\end{aligned}$$
所以,
$$\frac{\partial \mathcal L_t}{\partial U_{ij}}=\sum_{k=1}^t[\delta_{t,k}]_i[\textbf h_{k-1}]_j$$
$$\frac{\partial \mathcal L_t}{\partial U}=\sum_{k=1}^t\delta_{t,k}\textbf h_{k-1}^{\top}=\sum_{k=1}^t\delta_{t,k}\otimes\textbf h_{k-1}$$
因此,
$$\frac{\partial \mathcal L}{\partial U}=\sum_{t=1}^T\sum_{k=1}^t\delta_{t,k}\otimes\textbf h_{k-1}$$
三、$\mathcal L$ 对 $W$ 的梯度
观察 $\textbf s_t=U\textbf h_{t-1}+W\textbf x_t$ 这个式子,不难发现只要把刚刚推导的结果做一下简单的替换就可以直接得到新的结果:
$$\frac{\partial \mathcal L_t}{\partial W}=\sum_{k=1}^t\delta_{t,k}\otimes\textbf x_{k}$$
$$\frac{\partial \mathcal L}{\partial W}=\sum_{t=1}^T\sum_{k=1}^t\delta_{t,k}\otimes\textbf x_{k}$$
总的来说,没有写什么insightful的东西,就是记录一下而已。使用的套路都是BP中使用的(其实就是很基本的chain rule)。但是需要注意的是,这里实际上是在时间维度上的展开。如果是跟普通的神经网络那样构造多个隐层,则需要在“纵向”上继续扩展,形成所谓的深度RNN。因为Theano等自动求导工具的存在,所以如果只是为了编程的话,很多情况下其实也不太需要手推了。

深度双向RNN。图片来源:[2]
(二)梯度消失(gradient vanishing)
我们考察一下下面这个梯度:
$$\frac{\partial \mathcal L_t}{\partial U}=\frac{\partial \textbf h_t}{\partial U}\frac{\partial \hat{\textbf y}_t}{\partial \textbf h_t}\frac{\partial \mathcal L_t}{\partial \hat{\textbf y}_t}$$
这里的 $\dfrac{\partial \textbf h_t}{\partial U}$ 比较麻烦,是因为各个时刻共享了参数:$\textbf h_t$ 这个参数是和 $\textbf h_{t-1}$ 、$U$ 有关的,而 $\textbf h_{t-1}$ 又和 $\textbf h_{t-2}$ 、$U$ 有关。所以参照 [5] ,可以写成以下形式(读 [5] 的时候需要注意其前向传播过程和 [4] 一样,与本文是有区别的,但在这里不妨碍理解):
$$\frac{\partial \mathcal L_t}{\partial U}=\sum_{k=1}^t\frac{\partial \textbf h_k}{\partial U}\frac{\partial \textbf h_t}{\partial \textbf h_k}\frac{\partial \hat{\textbf y}_t}{\partial \textbf h_t}\frac{\partial \mathcal L_t}{\partial \hat{\textbf y}_t}$$
其中,
$$\begin{aligned}\frac{\partial \textbf h_t}{\partial \textbf h_k}&=\prod_{i=k+1}^t\frac{\partial \textbf h_i}{\partial \textbf h_{i-1}}\\&=\prod_{i=k+1}^t\frac{\partial \textbf s_i}{\partial \textbf h_{i-1}}\frac{\partial f(\textbf s_i)}{\partial \textbf s_i}\\&=\prod_{i=k+1}^tU^{\top}\text{diag}{f'(\textbf s_i)}\end{aligned}$$
从这个式子可以看出,当使用tanh或logistic激活函数时,由于导数值分别在0到1之间、0到1/4之间,所以如果权重矩阵 $U$ 的范数也不很大,那么经过 $t-k$ 次传播后,$\dfrac{\partial \textbf h_t}{\partial \textbf h_k}$ 的范数会趋于0,也就导致了梯度消失问题。其实从上面误差项的表达式也可以看出,$\delta_{t,k}$ 与 $\delta_{t,k+1}$ 是乘一个导函数的关系,这个导函数值域在0到1之间(tanh)、0到1/4之间(logistic),那么随着时间的累积,当然会造成梯度消失问题。
为了缓解梯度消失,可以使用ReLU、PReLU来作为激活函数,以及将 $U$ 初始化为单位矩阵(而不是用随机初始化)等方式。
(普通的前馈深层神经网络也会存在梯度消失,只不过那里是“纵向”上的。)
也就是说,虽然Simple RNN从理论上可以保持长时间间隔的状态之间的依赖关系,但是实际上只能学习到短期依赖关系。这就造成了“长期依赖”问题。打个比方,你对着模型说了一大段话,“你好,我叫小明,balabala……,很高兴认识你”。模型听完之后回答你:“很高兴认识你,你叫什么?我叫小红。”——模型已经忘了你叫什么了。
需要通过带LSTM单元的RNN来缓解梯度消失问题,现在一般把使用LSTM单元的RNN就直接叫LSTM了。LSTM单元引入了门机制(Gate),通过遗忘门、输入门和输出门来控制流过单元的信息。我们知道,Simple RNN之所以有梯度消失是因为误差项之间的相乘关系;如果用LSTM推导,会发现这个相乘关系变成了相加关系,所以可以缓解梯度消失。
(三)梯度爆炸(gradient exploding)
而对于梯度爆炸问题,通常就是使用比较简单的策略,也就是gradient clipping梯度裁剪:如果在一次迭代中各个权重的梯度平方和大于某个阈值,那么为避免权重的变化值太大,求一个缩放因子(阈值除以平方和),将所有的梯度乘以这个因子。TensorFlow里提供了很多种梯度裁剪的函数,直接看API吧。
参考:
[1] 《神经网络与深度学习讲义》
[2] Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
[3] BPTT算法推导
[4] On the difficulty of training RNN
[6] 知乎:deep bidirectional RNN +LSTM 用于癫痫检测的疑问?
[7] caffe里的clip gradient是什么意思?
机器学习 —— 基础整理(八)循环神经网络的BPTT算法步骤整理;梯度消失与梯度爆炸的更多相关文章
- 机器学习 —— 基础整理(七)前馈神经网络的BP反向传播算法步骤整理
这里把按 [1] 推导的BP算法(Backpropagation)步骤整理一下.突然想整理这个的原因是知乎上看到了一个帅呆了的求矩阵微分的方法(也就是 [2]),不得不感叹作者的功力.[1] 中直接使 ...
- RNN神经网络产生梯度消失和梯度爆炸的原因及解决方案
1.RNN模型结构 循环神经网络RNN(Recurrent Neural Network)会记忆之前的信息,并利用之前的信息影响后面结点的输出.也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏 ...
- Backpropagation Through Time (BPTT) 梯度消失与梯度爆炸
Backpropagation Through Time (BPTT) 梯度消失与梯度爆炸 下面的图显示的是RNN的结果以及数据前向流动方向 假设有 \[ \begin{split} h_t & ...
- SQL夯实基础(八):联接运算符算法归类
今天主要介绍三个常用联接运算符算法:合并联接(Merge join),哈希联接(Hash Join)和嵌套循环联接(Nested Loop Join).(mysql至8.0版本,都只支持Nested ...
- DL基础补全计划(五)---数值稳定性及参数初始化(梯度消失、梯度爆炸)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 循环神经网络(RNN)
1. 场景与应用 在循环神经网络可以用于文本生成.机器翻译还有看图描述等,在这些场景中很多都出现了RNN的身影. 2. RNN的作用 传统的神经网络DNN或者CNN网络他们的输入和输出都是 ...
- 深度学习之循环神经网络(RNN)
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络,适合用于处理视频.语音.文本等与时序相关的问题.在循环神经网络中,神经元不但可以接收其他神经元 ...
- Recurrent Neural Networks(RNN) 循环神经网络初探
1. 针对机器学习/深度神经网络“记忆能力”的讨论 0x1:数据规律的本质是能代表此类数据的通用模式 - 数据挖掘的本质是在进行模式提取 数据的本质是存储信息的介质,而模式(pattern)是信息的一 ...
- 【学习笔记】循环神经网络(RNN)
前言 多方寻找视频于博客.学习笔记,依然不能完全熟悉RNN,因此决定还是回到书本(<神经网络与深度学习>第六章),一点点把啃下来,因为这一章对于整个NLP学习十分重要,我想打好基础. 当然 ...
随机推荐
- 推荐xamlspy
xamlspy(http://xamlspy.com/) 如果在win32时代用过spy++的,都应该在silverlight/wpf时代用一下xamlspy,让你重新找到用spy++看别人程序的UI ...
- form表单在前台转json对象
会发生序列化乱码问题,待解决. //根据表单id将其内空间,名称,值转为json var fireTraceEquipment =queryParamByFormId('form1'); functi ...
- JavaScript数组去重方法及测试结果
最近看到一些人的去面试web前端,都说碰到过问JavaScript数组去重的问题,我也学习了一下做下总结. 实际上最有代表性也就三种方法:数组双重循环,对象哈希,排序后去重. 这三种方法我都做了性能测 ...
- Why you should QC your reads AND your assembly?
鲤鱼基因组:http://www.ntv.cn/a/20140923/52953.shtml 关于鲤鱼基因组的测定,数据质量控制遭到质疑. Why you should QC your reads ...
- App测试札记
App测试札记 测试应该收集信息 测试应该问问题 测试应该扮演不同角色 测试应该如实反馈 初学者 有哪些可以利用的信息?需求,技术方案,测试设计,现有功能,相关人员 App会在哪些环境下运行 App会 ...
- react-native —— 在Mac上配置React Native Android开发环境排坑总结
配置React Native Android开发环境总结 1.卸载Android Studio,在终端(terminal)执行以下命令: rm -Rf /Applications/Android\ S ...
- 用JS来实现于截取中英文混合字符串方法(转载)
网站制作过程中,提示层文字超出,需要JS做字符串截取,但是呢,我们常常会烦恼文字中英文混合如何判断,因为我们知道在JS中 string.length这个值是不考虑中英文的,但是计算机对中英文的识别是 ...
- 搭建带热更新功能的本地开发node server
引言 使用webpack有一段时间了,对其中的热更新的大概理解是:对某个模块做了修改,页面只做局部更新而不需要刷新整个页面来进行更新.这样就能节省因为整个页面刷新所产生开销的时间,模块热加载加快了开发 ...
- 将逗号分隔 的字符串转化成List
将逗号分隔 的字符串转化成List List<String> parIdListTmp = new ArrayList<String>(); String parIdArray ...
- Visual Studio Debugger中七个鲜为人知的小功能
Visual Studio debugger是一个很棒的调试工具,可以帮助程序猿们快速地发现和解决问题.这里给大家简单介绍一下VS调试工具中的七个鲜为人知的小功能. 1. 一键跳转到指定语句 调 ...