Hadoop伪分布式部署
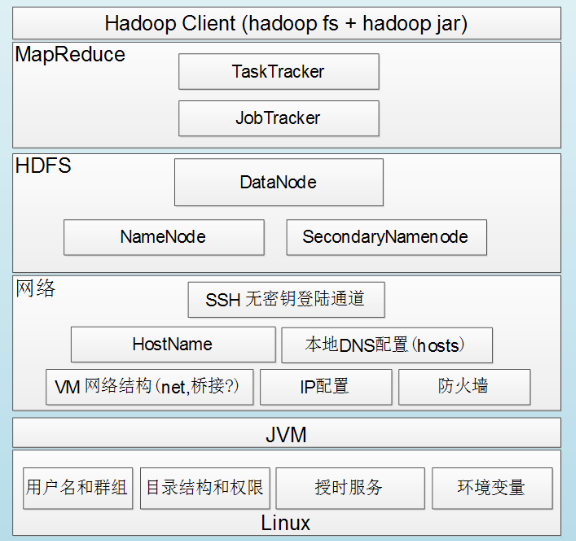
一、Hadoop组件依赖关系:
步骤
1)关闭防火墙和禁用SELinux
切换到root用户
关闭防火墙:service iptables stop
Linux下开启/关闭防火墙的两种方法
1.永久性生效,重启后不会恢复:
开启:chkconfig iptables on
关闭:chkconfig iptables off
2.即时生效,重启后恢复
开启:service iptables start
关闭:service iptables stop
禁用SELinux
vim /etc/sysconfig/selinux 设置SELinux=disabled
2)设置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
3)修改主机名(hostname)
vim /etc/sysconfig/network
4)IP与hostname绑定
作用:可以在window浏览器主页上输入IP地址加端口号访问linux下Hadoop的运行进程
vim /etc/hosts
内容显示如下
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.217.150 linux.chaofn.org linux
然后在window下的C:\Windows\System32\drivers\etc目录下有一个hosts文件,打开写入
192.168.217.150 linux.chaofn.org linux
5)设置SSH自动登录(所有守护进程通过SSH协议进行通信)
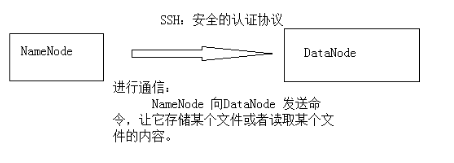
免秘钥设置,方便namenode向datanode的访问
切换到普通用户
输入命令 ssh-keygen -t rsa
默认是在~/.ssh/目录下
drwx------ 2 chaofn chaofn 4096 May 20 20:00 .ssh 权限为700,要改为644
进入.ssh目录,有两个文件id_rsa id_rsa.pub,一个是私钥,一个是公钥
然后复制一份id_rsa.pub,命令:cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys(这个操作实现了权限的更改)
测试.命令 ssh localhost
ssh linux.chaofn.org
6)Hadoop环境变量配置:
vim /etc/profile 添加如下内容:
#HADOOP
export HADOOP_HOME=/home/chaofn/opt/setup/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
7)修改conf目录下的配置文件
配置core-site.xml

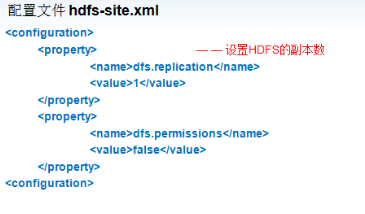
配置hdfs-site.xml
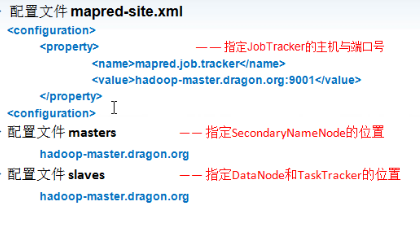
配置mapred-site.xml、masters、slaves
8)格式化namenode
命令:hadoop namenode -format
注意格式化过程中出现的错误提示,仔细检查
9)启动Hadoop
命令:start-all.sh(启动方式有很多种)
通过jps命令查看五个进程是否全部启动
通过window的网页界面查看
输入hadoop-master.dragon.org:50030(我的域名是linux.chaofn.org)查看是否启动
注意一定要关闭linux下的防火墙,不然window无法访问
Hadoop伪分布式部署的更多相关文章
- ubuntu hadoop伪分布式部署
环境 ubuntu hadoop2.8.1 java1.8 1.配置java1.8 2.配置ssh免密登录 3.hadoop配置 环境变量 配置hadoop环境文件hadoop-env.sh core ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- CentOS7 下 Hadoop 单节点(伪分布式)部署
Hadoop 下载 (2.9.2) https://hadoop.apache.org/releases.html 准备工作 关闭防火墙 (也可放行) # 停止防火墙 systemctl stop f ...
- Hadoop1 Centos伪分布式部署
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- Hadoop伪分布式的搭建
主要分为三个步骤:1.安装vmware虚拟机运行软件 2.在vmware虚拟机中安装linux操作系统 3.配置hadoop伪分布式环境 Hadoop环境部署-JDK部分------------ ...
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- hadoop3.1伪分布式部署
1.环境准备 系统版本:CentOS7.5 主机名:node01 hadoop3.1 的下载地址: http://mirror.bit.edu.cn/apache/hadoop/common/hado ...
- Hadoop-01 搭建hadoop伪分布式运行环境
Linux中配置Hadoop运行环境 程序清单 VMware Workstation 11.0.0 build-2305329 centos6.5 64bit jdk-7u80-linux-x64.r ...
随机推荐
- java.net.BindException: Cannot assign requested address: bind
异常信息 时间:2017-03-16 10:21:05,644 - 级别:[ERROR] - 消息: [other] Failed to start end point associated with ...
- (五):C++分布式实时应用框架——支撑复杂的业务通讯关系
C++分布式实时应用框架--支撑复杂的业务通讯关系 技术交流合作QQ群:436466587 欢迎讨论交流 版权声明:本文版权及所用技术归属smartguys团队所有,对于抄袭,非经同意转载等行为保留法 ...
- 37、mysql初识
之前我们写代码需要存取信息时用的是文件可是用文件存取数据非常局限,今天我们将走进一个新的世界mysql 一.数据库由来 之前所学,数据要永久保存,比如用户注册的用户信息,都是保存于文件中,而文件只能存 ...
- 文件系统常用命令df、du、fsck、dumpe2fs
df 查看文件系统 [root@localhost ~]# df 文件系统 1K-块 已用 可用 已用% 挂载点 /dev/sda5 16558080 1337676 15220404 9% / de ...
- Python3 将txt数据转换成列表,进行排序,筛选
Python 程序员需要知道的 30 个技巧 首先是数据: 将上边的四个数据分别写在新建的txt文件中 1.将txt数据转为列表 with open('james.txt') as jaf: data ...
- windows 下共享内存使用方法示例
windows下共享内存使用方法较 linux 而言微微复杂 示例实现的功能 有一个视频文件,一块内存区域 : 程序 A,将该视频写入该内存区域 : 程序 B,从该内存区域读取该视频 : 代码模块实现 ...
- geoserver集成以及部署arcgis server瓦片数据
关注重点: 一般来说,geoserver是不支持arcgis server格式瓦片数据部署的,至少我本机的geoserver版本(2.8.5)以及之前的版本并没有集成进来,不知道目前官网的最新版是否支 ...
- Docker(十一):Docker实战部署HTTPS的Tomcat站点
1.选择基础镜像 docker pull tomcat:7.0-jre8 2.生成HTTPS证书 keytool -genkey -alias tomcat -keyalg RSA -keystor ...
- java 异常处理与返回
try{ // 1. return ++x; }catch(){ }finally{ //2. x++; } 实际返回值还是 ++x后的结果,因为 ++x 后 x 的值会入栈,作为返回结果: 以上代码 ...
- shell 踩坑记
变量赋值时,等号两边不能有空格: 在判断表达式中,不论是 [ -n "$1" ] 还是 [ -f "$1" ] 都要在变量两侧加上双引号: 在使用与或非判断式 ...