scrapy全站爬取拉勾网及CrawSpider介绍
一.指定模板创建爬虫文件

命令
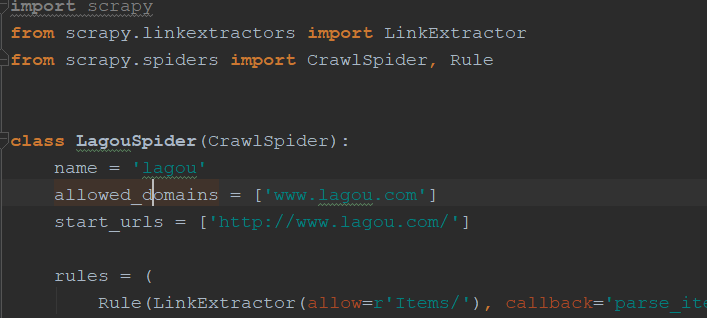
创建成功后的模板,把http改为https
二.CrawSpider源码介绍
1.官网介绍:
-
这是用于抓取常规网站的最常用的蜘蛛,因为它通过定义一组规则为跟踪链接提供了便利的机制。它可能不是最适合您的特定网站或项目,但它在几种情况下足够通用,因此您可以从它开始并根据需要覆盖它以获得更多自定义功能,或者只是实现您自己的蜘蛛。
除了从Spider继承的属性(您必须指定)之外,此类还支持一个新属性:
rules-
这是一个(或多个)
Rule对象的列表。每个Rule定义用于爬网站点的特定行为。规则对象如下所述。如果多个规则匹配相同的链接,则将根据它们在此属性中定义的顺序使用第一个规则。
这个蜘蛛还暴露了一个可重写的方法:
parse_start_url(回应)-
为start_urls响应调用此方法。它允许解析初始响应,并且必须返回
Item对象,Request对象或包含其中任何一个的iterable。
爬行规则
- class
scrapy.spiders.Rule(link_extractor,callback = None,cb_kwargs = None,follow = None,process_links = None,process_request = None ) -
link_extractor是一个Link Extractor对象,它定义如何从每个已爬网页面中提取链接。callback是一个可调用的或一个字符串(在这种情况下,将使用具有该名称的spider对象的方法)为使用指定的link_extractor提取的每个链接调用。此回调接收响应作为其第一个参数,并且必须返回包含Item和/或Request对象(或其任何子类)的列表。警告
编写爬网蜘蛛规则时,请避免使用
parse回调,因为CrawlSpider使用parse方法本身来实现其逻辑。因此,如果您覆盖该parse方法,则爬网蜘蛛将不再起作用。cb_kwargs是一个包含要传递给回调函数的关键字参数的dict。follow是一个布尔值,它指定是否应该从使用此规则提取的每个响应中跟踪链接。如果callback是,则follow默认为True,否则默认为False。process_links是一个可调用的,或一个字符串(在这种情况下,将使用来自具有该名称的蜘蛛对象的方法),将使用指定的每个响应提取的每个链接列表调用该方法link_extractor。这主要用于过滤目的。process_request是一个可调用的,或一个字符串(在这种情况下,将使用来自具有该名称的spider对象的方法),该方法将在此规则提取的每个请求中调用,并且必须返回请求或None(以过滤掉请求) 。
CrawlSpider示例
现在让我们看看一个带有规则的示例CrawlSpider:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor class MySpider(CrawlSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com'] rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))), # Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
) def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return item
这个spider会开始抓取example.com的主页,收集类别链接和项目链接,使用该parse_item方法解析后者。对于每个项目响应,将使用XPath从HTML中提取一些数据,并将Item使用它填充。
2.源码分析:
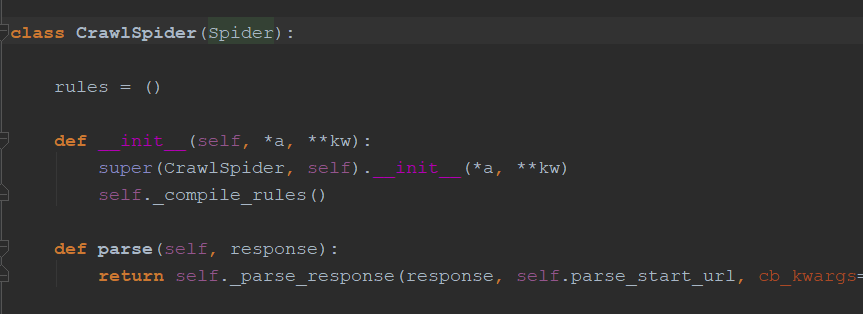
CrawSpider继承Spider:
Spider中的start_request()方法和make_requests_from_url()方法实现遍历start_urls中的url,如下:
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True) def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url, dont_filter=True)
使用Spider(basic)模板时,需要重写parse()函数处理爬虫逻辑,而crawspider已经写好了该函数如下,该函数调用_parse_response(),判断是否有回调函数,把参数传递给parse_start_url(),返回一个空数组,然后调用process_result()函数返回参数(注:如果不重写,没什么用,相当于什么也没干,可以重写加逻辑),然后判断follw是否为True和_follow_links是否为True(默认为True,可以配置),然后循环_requests_to_follow()函数的返回值,该函数判断是否为response,如果不是则什么也不返回,然后通过set方法对response的url去重,然后把rule使用enumerate()方法把它变成可迭代的对象:
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
def _parse_response(self, response, callback, cb_kwargs, follow=True):
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item if follow and self._follow_links:
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def parse_start_url(self, response):
return [] def process_results(self, response, results):
return results
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
if links and rule.process_links:
links = rule.process_links(links)
for link in links:
seen.add(link)
r = self._build_request(n, link)
yield rule.process_request(r)
该类在定义时调用_compile_rules()方法,该函数会调用回调函数,process_links()也是个方法,在rule类中,可以处理url等(如为了负载均衡,每个地方的ip下的域名不同,可以处理),然后_requests_to_follow()抽取link添加到seen中,可以自己重写process_links函数处理url,又调用_build_request()方法,该函数的回调函数为_response_downloaded(),该函数把response返回给_parse_response()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, six.string_types):
return getattr(self, method, None) self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
简单总结:
继承Spider,Spider入口函数为start_requests(),默认返回处理函数为parse(),这时parse()函数会调用_parse_response(),允许我们自己定义重写parse_start_url(),process_results()对parse做处理,处理完成后,会去调用rule,然后把response交给rule中得LinkExtractor,有allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=()【此参数可以进一步限定url】等参数处理url,然后_requests_to_follow()会抽取处理过后的link,然后对每一个link都yeild一个Request,然后有一个_response_downloaded()取rule,然后回调给_parse_response()函数。
三.爬取拉钩代码
1.rule(allow是一个正则匹配,可以传递元组和字符串):
rules = (
Rule(LinkExtractor(allow=('zhaopin/.*',)), follow=True),
Rule(LinkExtractor(allow=r'gongsi/j\d+.html'), follow=True),
Rule(LinkExtractor(allow=r'jobs/\d+.html'), callback='parse_item', follow=True),
)
2.scrapy shell调试获取内容(注:这里要指定user-agent,不然状态码虽然是200但是没有数据,-s指定,如sceapy shell -s "..." url)
如:scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/60.0" https://www.lagou.com/jobs/4923444.html
3.item设计及实例化设计(需要设置请求头,填写Spider类中的custom_setting设置或重写start_request()方法):
3.1item设计及处理相应字段函数
def replace_splash(value):
return value.replace("/", "") def handle_strip(value):
return value.strip() def handle_jobaddr(value):
addr_list = value.split("\n")
addr_list = [item.strip() for item in addr_list if item.strip() != "查看地图"]
return "".join(addr_list)
def leave_time(value):
#处理发布时间
return value.split()[0] class LagouJobItemLoader(ItemLoader):
# 自定义itemloader
default_output_processor = TakeFirst() class LagouJobItem(scrapy.Item):
# 拉勾网职位
title = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
salary = scrapy.Field()
tags=scrapy.Field(
output_processor=Join(',')
)
job_city = scrapy.Field(
input_processor=MapCompose(replace_splash),
)
work_years = scrapy.Field(
input_processor=MapCompose(replace_splash),
)
degree_need = scrapy.Field(
input_processor=MapCompose(replace_splash),
)
job_type = scrapy.Field()
publish_time = scrapy.Field(
input_processor=MapCompose(leave_time)
)
job_advantage = scrapy.Field()
job_desc = scrapy.Field(
input_processor=MapCompose(remove_tags,handle_strip),
output_processor=Join(',')
)
job_addr = scrapy.Field(
input_processor=MapCompose(remove_tags, handle_jobaddr),
)
company_name = scrapy.Field(
input_processor=MapCompose(handle_strip),
)
company_url = scrapy.Field()
crawl_time = scrapy.Field()
crawl_update_time = scrapy.Field()
3.2实列化item(使用item_loader方法)
custom_settings = {
"COOKIES_ENABLED": False,
"DOWNLOAD_DELAY": 1,
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': 'user_trace_token=20171015132411-12af3b52-3a51-466f-bfae-a98fc96b4f90; LGUID=20171015132412-13eaf40f-b169-11e7-960b-525400f775ce; SEARCH_ID=070e82cdbbc04cc8b97710c2c0159ce1; ab_test_random_num=0; X_HTTP_TOKEN=d1cf855aacf760c3965ee017e0d3eb96; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DsXIrWUxpNGLE2g_bKzlUCXPTRJMHxfCs6L20RqgCpUq%26wd%3D%26eqid%3Dee53adaf00026e940000000559e354cc; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_hotjob; login=false; unick=""; _putrc=""; JSESSIONID=ABAAABAAAFCAAEG50060B788C4EED616EB9D1BF30380575; _gat=1; _ga=GA1.2.471681568.1508045060; LGSID=20171015203008-94e1afa5-b1a4-11e7-9788-525400f775ce; LGRID=20171015204552-c792b887-b1a6-11e7-9788-525400f775ce',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
}
def parse_job(self, response):
item_loader = LagouJobItemLoader(item=LagouJobItem(), response=response)
# i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
# i['name'] = response.xpath('//div[@id="name"]').extract()
# i['description'] = response.xpath('//div[@id="description"]').extract()
item_loader.add_css("title", ".job-name::attr(title)")
item_loader.add_value("url", response.url)
item_loader.add_value("url_object_id",get_md5(response.url))
item_loader.add_css("salary", ".job_request p span.salary::text")
item_loader.add_xpath("job_city", "//dd[@class='job_request']/p/span[2]/text()")
item_loader.add_xpath("work_years", "//dd[@class='job_request']/p/span[3]/text()")
item_loader.add_xpath("degree_need", "//dd[@class='job_request']/p/span[4]/text()")
item_loader.add_xpath("job_type", "//dd[@class='job_request']/p/span[5]/text()")
item_loader.add_css("publish_time", ".job_request p.publish_time::text")
item_loader.add_css("job_advantage", ".job-advantage p::text")
item_loader.add_css("job_desc", ".job_bt div p")
item_loader.add_css("job_addr", ".work_addr")
item_loader.add_css("tags",".position-label.clearfix li::text")
item_loader.add_css("company_name", ".job_company dt a img::attr(alt)")
item_loader.add_css("company_url", ".job_company dt a::attr(href)")
item_loader.add_value("crawl_time", datetime.datetime.now())
# item_loader.add_css("crawl_update_time",".work_addr")
lagou_item = item_loader.load_item()
return lagou_item
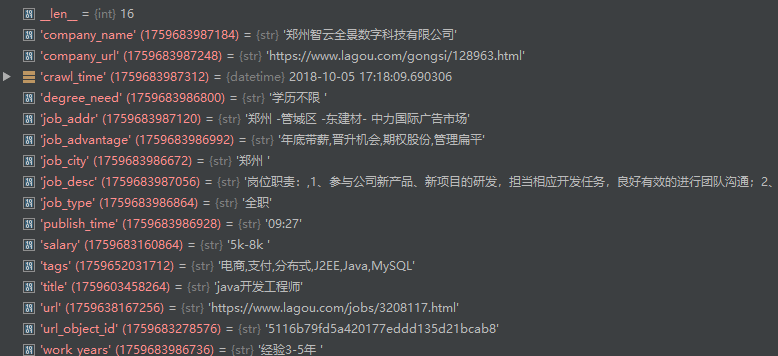
3.3处理后调试内容如下
4.sql语句书写(也写在items.py中,方便管理)
def get_insert_sql(self):
insert_sql = """
insert into lagou_spider(title, url, url_object_id, tags,salary, job_city, work_years, degree_need,
job_type, publish_time, job_advantage, job_desc, job_addr, company_url, company_name, job_id,crawl_time)
VALUES (%s, %s, %s, %s, %s, %s ,%s, %s, %s, %s, %s, %s, %s, %s, %s, %s,%s) ON DUPLICATE KEY UPDATE job_desc=VALUES(job_desc)
"""
#利用正则获取url中的id
job_id = extract_num(self["url"])
params = (self["title"], self["url"], self['url_object_id'],self['tags'], self["salary"], self["job_city"], self["work_years"], self["degree_need"],
self["job_type"], self["publish_time"], self["job_advantage"], self["job_desc"], self["job_addr"],
self["company_url"],
self["company_name"], job_id,self['crawl_time'].strftime(SQL_DATETIME_FORMAT)) return insert_sql, params
5.到这数据已经能爬取并保存了:

6.注意:
访问过于频繁拉钩网会禁ip(这是常用的反爬技术,只需使用ip代理池就行),网页无法正常返回,但是状态码仍然是200(正规应该是403,我们可以依靠状态码监控),虽然加大了爬取的难度(对于拉钩网可以判断url中是否有forbidden把这样的url过滤掉,然后把爬虫暂停会或换ip),但是对于百度谷歌等搜索引擎的爬虫也判断为200的状态,会把它纳入搜索中,当SEO爬取到这些网页,会判断这些页面内容都是相同的(以为有恶意SEO的表现),会降权,是很不友好的。
scrapy全站爬取拉勾网及CrawSpider介绍的更多相关文章
- 爬虫---scrapy全站爬取
全站爬取1 基于管道的持久化存储 数据解析(爬虫类) 将解析的数据封装到item类型的对象中(爬虫类) 将item提交给管道, yield item(爬虫类) 在管道类的process_item中接手 ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- scrapy增量爬取
开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的 ...
- scrapy使用爬取多个页面
scrapy是个好玩的爬虫框架,基本用法就是:输入起始的一堆url,让爬虫去get这些网页,然后parse页面,获取自己喜欢的东西.. 用上去有django的感觉,有settings,有field.还 ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- scrapy_全站爬取
如何查询scrapy有哪些模版? scrapy genspider –list 如何创建crawl模版? scrapy genspider -t crawl 域名 scrapy genspider - ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
随机推荐
- UVA437-The Tower of Babylon(动态规划基础)
Problem UVA437-The Tower of Babylon Accept: 3648 Submit: 12532Time Limit: 3000 mSec Problem Descrip ...
- 转://利用从awr中查找好的执行计划来优化SQL
原文地址:http://blog.csdn.net/zengxuewen2045/article/details/53495613 同事反应系统慢,看下是不是有锁了,登入数据库检查,没有异常锁定,但发 ...
- Python:Day48 Jquery
引用方式: <script src="jquery-3.3.1.js"></script> jQuery就是一个jQuery对象,可以简写成$ 基本语法:$ ...
- 【css】怎么让Chrome支持小于12px 的文字
谷歌浏览器Chrome是Webkit的内核,有一个 -webkit-text-size-adjust 的私有 CSS 属性,通过它即可实现字体大小不随终端设备或浏览器影响.CSS样式定义如下:-web ...
- Java内存模型(和堆栈等不是同一层次的划分)
什么叫Java内存模型? 现代计算机通过指令的重排序来提升计算机的性能,而没有限制条件的指令重排序会使得程序的行为不可预测,JMM就是通过一系列的操作规则限制指令重排序的方式使得指令重排序不会破坏JM ...
- centos 7 安装mqtt 修改用户名和密码
我先新买个Centos 的系统 咱登录呢就用这个软件,主要是方便,可以少安装一些东西 根据自己的系统选择,上面的是32位的. 输入 root 回车 输入密码然后回车 输入的时候什么也不显示 输入 c ...
- 错误 103 未能加载文件或程序集“Telerik.Web.UI”或它的某一个依赖项。磁盘空间不足。 (异常来自 HRESULT:0x80070070)
运行vs2010时出现错误: 错误 103 未能加载文件或程序集“Telerik.Web.UI”或它的某一个依赖项.磁盘空间不足. (异常来自 HRESULT:0x80070070) 处理方式:清理C ...
- Spring Boot 之日志记录
Spring Boot 之日志记录 Spring Boot 支持集成 Java 世界主流的日志库. 如果对于 Java 日志库不熟悉,可以参考:细说 Java 主流日志工具库 关键词: log4j, ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- HBase篇(5)- BloomFilter
[每日五分钟搞定大数据]系列,HBase第五篇.上一篇我们落下了Bloom Filter,这次我们来聊聊这个东西. Bloom Filter 是什么? 先简单的介绍下Bloom Filter(布隆过滤 ...