azkaban架构介绍
转自:https://blog.csdn.net/huoji1990/article/details/81911904
官网:https://azkaban.readthedocs.io/en/latest/
1. Azkaban(阿兹卡班)是什么?
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies 来设置依赖关系,这个依赖关系必须是无环的,否则会被视为无效的工作流。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
在介绍Azkaban之前,我们先来看一下现有的两个工作流任务调度系统。知名度比较高的应该是Apache Oozie,但是其配置工作流的过程是编写大量的XML配置,而且代码复杂度比较高,不易于二次开发。另外一个应用也比较广泛的调度系统是Airflow,但是其开发语言是Python。由于我们团队内部使用Java作为主流开发语言,所以选型的时候就被淘汰掉了。我们选择Azkaban的原因基于以下几点:
- 提供功能清晰,简单易用的Web UI界面
- 提供job配置文件快速建立任务和任务之间的依赖关系
- 提供模块化和可插拔的插件机制,原生支持command、Java、Hive、Pig、Hadoop
- 基于Java开发,代码结构清晰,易于二次开发
2. Azkaban的适用场景
实际项目中经常有这些场景:每天有一个大任务,这个大任务可以分成A,B,C,D四个小任务,A,B任务之间没有依赖关系,C任务依赖A,B任务的结果,D任务依赖C任务的结果。一般的做法是,开两个终端同时执行A,B,两个都执行完了再执行C,最后再执行D。这样的话,整个的执行过程都需要人工参加,并且得盯着各任务的进度。但是我们的很多任务都是在深更半夜执行的,通过写脚本设置crontab执行。其实,整个过程类似于一个有向无环图(DAG)。每个子任务相当于大任务中的一个流,任务的起点可以从没有度的节点开始执行,任何没有通路的节点之间可以同时执行,比如上述的A,B。总结起来的话,我们需要的就是一个工作流的调度器,而Azkaban就是能解决上述问题的一个调度器。
3. Azkaban架构
Azkaban在LinkedIn上实施,以解决Hadoop作业依赖问题。我们有工作需要按顺序运行,从ETL工作到数据分析产品。最初是单一服务器解决方案,随着多年来Hadoop用户数量的增加,Azkaban 已经发展成为一个更强大的解决方案。
Azkaban由三个关键组件构成:
- 关系型数据库(MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
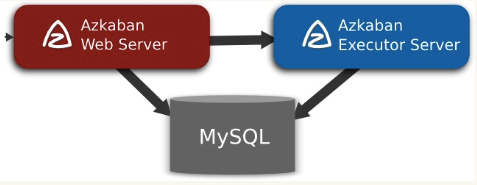
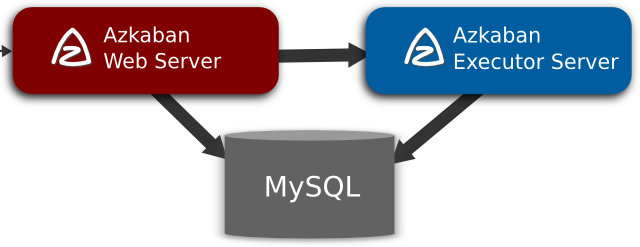
3.1 关系型数据库(MySQL)
Azkaban使用数据库存储大部分状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
AzkabanWebServer使用数据库的原因如下:
- 项目管理:项目、项目权限以及上传的文件。
- 执行流状态:跟踪执行流程以及执行程序正在运行的流程。
- 以前的流程/作业:通过以前的作业和流程执行以及访问其日志文件进行搜索。
- 计划程序:保留计划作业的状态。
- SLA:保持所有的SLA规则
AzkabanExecutorServer使用数据库的原因如下:
- 访问项目:从数据库检索项目文件。
- 执行流程/作业:检索和更新正在执行的作业流的数据
- 日志:将作业和工作流的输出日志存储到数据库中。
- 交互依赖关系:如果一个工作流在不同的执行器上运行,它将从数据库中获取状态。
3.2 AzkabanWebServer
AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它负责project管理、用户登录认证、定时执行工作流、跟踪工作流执行进度等一系列任务。同时,它还提供Web服务操作的接口,利用该接口,用户可以使用curl或其他ajax的方式,来执行azkaban的相关操作。操作包括:用户登录、创建project、上传workflow、执行workflow、查询workflow的执行进度、杀掉workflow等一系列操作,且这些操作的返回结果均是json的格式。并且Azkaban使用方便,Azkaban使用以.job为后缀名的键值属性文件来定义工作流中的各个任务,以及使用dependencies属性来定义作业间的依赖关系链。这些作业文件和关联的代码最终以*.zip的方式通过Azkaban UI上传到Web服务器上。
3.3 AzkabanExecutorServer
以前版本的Azkaban在单个服务中具有AzkabanWebServer和AzkabanExecutorServer功能,目前Azkaban已将AzkabanExecutorServer分离成独立的服务器,拆分AzkabanExecutorServer的原因有如下几点:
- 某个任务流失败后,可以更方便的将其重新执行
- 便于Azkaban升级
AzkabanExecutorServer主要负责具体的工作流的提交、执行,可以启动多个执行服务器,它们通过mysql数据库来协调任务的执行。
4. Azkaban作业流执行过程
- Webserver根据内存中缓存的各Executor的资源状态(Webserver有一个线程会遍历各个active executor,去发送http请求获取其资源状态信息缓存到内存中),按照选择策略(包括executor资源状态、最近执行流个数等)选择一个executor下发作业流;
- executor判断是否设置作业粒度分配,如果未设置作业粒度分配,则在当前executor执行所有作业;如果设置了作业粒度分配,则当前节点会成为作业分配的决策者,即分配节点;
- 分配节点从zookeeper获取各个executor的资源状态信息,然后根据策略选择一个executor分配作业;
- 被分配到作业的executor即成为执行节点,执行作业,然后更新数据库。
5. Azkaban架构的三种运行模式
在版本3.0中,Azkaban提供了以下三种模式:
- solo server mode:最简单的模式,数据库内置的H2数据库,AzkabanWebServer和AzkabanExecutorServer都在一个进程中运行,任务量不大项目可以采用此模式。
- two server mode:数据库为MySQL,管理服务器和执行服务器在不同进程,这种模式下,AzkabanWebServer和AzkabanExecutorServer互不影响。
- multiple executor mode:该模式下,AzkabanWebServer和AzkabanExecutorServer运行在不同主机上,且AzkabanExecutorServer可以有多个。
azkaban架构介绍的更多相关文章
- MySQL高级知识- MySQL的架构介绍
[TOC] 1.MySQL 简介 概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而 ...
- 从零开始编写自己的C#框架(5)——三层架构介绍
三层架构对于开发人员来说,已经是司空见惯了,除了大型与超小型项目外,大多都是这种架构来进行开发. 在这里为初学者们简单介绍一下三层架构: (下面内容摘自<趣味理解:三层架构与养猪—<.NE ...
- SOA架构介绍和理解
SOA架构介绍和理解 SOA的正确方法论及目标模型,其实SOA在实现架构落地上,需要考虑到对服务的组合,不断的重用现有的服务,让企业应用可以逐步集成,快速实现业务的迭代. 通过SOA架构分层将服务按照 ...
- MemSQL分布式架构介绍(一)
最近在了解MemSQL架构,看了些官方文档,在这里做个记录,原文在这里:http://docs.memsql.com/latest/concepts/distributed_architecture/ ...
- Apache Shiro 使用手册(一)Shiro架构介绍 - kdboy - ITeye技术网站
转载 原文地址 http://kdboy.iteye.com/blog/1154644 一.什么是Shiro Apache Shiro是一个强大易用的Java安全框架,提供了认证.授权.加密和会话管理 ...
- Apache Shiro 使用手册(一)Shiro架构介绍
一.什么是Shiro Apache Shiro是一个强大易用的Java安全框架,提供了认证.授权.加密和会话管理等功能: 认证 - 用户身份识别,常被称为用户"登录": 授权 - ...
- MemSQL分布式架构介绍(二)
接上次的MemSQL分布式架构介绍(一),原文在这里:http://docs.memsql.com/latest/concepts/distributed_architecture/ 首先上张图,是我 ...
- 大型网站技术架构介绍--squid
一.大型网站技术架构介绍 1.pv高 ip高 并发量 2.大型网站架构重点 1. 高性能:响应时间,TPS,系统性能计数器.缓存,消息队列等. 高可用性High Availabilit ...
- Android_进化史和平台架构介绍
一.Android平台发展史 2008年9月,谷歌正式发布了Android 1.0系统,全球第一台Android设备HTC (G1) 2009年4月,谷歌正式推出了Android 1.5 ...
随机推荐
- JavaScript作用域(第七天)
我们都知道js代码是由自上而下的执行,但我们来看看下面的代码: test(); function test(){ console.log("hello world"); }; 如果 ...
- pip install torch on windows, and the 'from torch._C import * ImportError: DLL load failed:' solution
通过pip安装PyTorch 0.4.0成功(cpu, not gpu; python3.5; pip): pip3 install http://download.pytorch.org/whl/c ...
- [工作积累] TAA Ghosting 的相关问题
因为TAA要使用上一帧的历史结果,那么在相机移动的时候,颜色就会有残留,出现ghosting(残影). 由于上一帧历史是累积的,是由上一帧的直接渲染结果和上上帧的结果做了合并,所以ghosting并不 ...
- 去重和分类后缀asp、php等路径 用python3写的
我们在做渗透的时候肯定会用上扫描器的,本人一般会用御剑,当然你也会喜欢别的工具. 很多时候,能否渗透成功其实还挺依赖与字典的,如果把后台给扫出来了,恰好还弱口令,那么岂不是美滋滋. 因此,有一个好的字 ...
- 谈lisp
The Lisp Curse /Lisp魔咒 http://winestockwebdesign.com/Essays/Lisp_Curse.html 英文出处 http://www.soimort. ...
- python padas 学习
import matplotlib from pandas import DataFrame import numpy as np import pandas as pd import MySQLdb ...
- 反向Ajax:WebSocket
郭晨 软件151 1531610114 WebSocket 在HTML5中出现的WebSocket是一种比Comet还要新的反向Ajax技术,WebSocket启用了双向的全双工通信信道,许多浏览器( ...
- python 执行oracle、python脚本文件
import os # sql脚本结尾加';'!!! os.system('sqlplus.exe scott/s123@127.0.0.1:1521/ORCL @D:/PycharmProjects ...
- JVM GC机制
垃圾收集主要是针对堆和方法区进行. 回收机制: 现在的JVM基本都使用分代回收机制,把堆中内存区域分为新生代,老年代. 新生代: Eden(80%) Survivor0(10%) Survivor1( ...
- 19.1 PORT CONTROL DESCRIPTIONS
[原文] PORT CONFIGURATION REGISTER (GPACON-GPJCON) In S3C2440A, most of the pins are multiplexed pins. ...