解决KafKa数据存储与顺序一致性保证
“严格的顺序消费”有多么困难
下面就从3个方面来分析一下,对于一个消息中间件来说,”严格的顺序消费”有多么困难,或者说不可能。
发送端
发送端不能异步发送,异步发送在发送失败的情况下,就没办法保证消息顺序。
比如你连续发了1,2,3。 过了一会,返回结果1失败,2, 3成功。你把1再重新发送1遍,这个时候顺序就乱掉了。
存储端
对于存储端,要保证消息顺序,会有以下几个问题:
(1)消息不能分区。也就是1个topic,只能有1个队列。在Kafka中,它叫做partition;在RocketMQ中,它叫做queue。 如果你有多个队列,那同1个topic的消息,会分散到多个分区里面,自然不能保证顺序。
(2)即使只有1个队列的情况下,会有第2个问题。该机器挂了之后,能否切换到其他机器?也就是高可用问题。
比如你当前的机器挂了,上面还有消息没有消费完。此时切换到其他机器,可用性保证了。但消息顺序就乱掉了。
要想保证,一方面要同步复制,不能异步复制;另1方面得保证,切机器之前,挂掉的机器上面,所有消息必须消费完了,不能有残留。很明显,这个很难!!!
接收端
对于接收端,不能并行消费,也即不能开多线程或者多个客户端消费同1个队列。
总结
从上面的分析可以看出,要保证消息的严格有序,有多么困难!
发送端和接收端的问题,还好解决一点,限制异步发送,限制并行消费。但对于存储端,机器挂了之后,切换的问题,就很难解决了。
你切换了,可能消息就会乱;你不切换,那就暂时不可用。这2者之间,就需要权衡了。
业务需要全局有序吗?
通过上面分析可以看出,要保证一个topic内部,消息严格的有序,是很困难的,或者说条件是很苛刻的。
那怎么办呢?我们一定要使出所有力气、用尽所有办法,来保证消息的严格有序吗?
这里就需要从另外一个角度去考虑这个问题:业务角度。正如在下面这篇博客中所说的:
http://www.jianshu.com/p/453c6e7ff81c
实际情况中:
(1)不关注顺序的业务大量存在;
(2) 队列无序不代表消息无序。
第(2)条的意思是说:我们不保证队列的全局有序,但可以保证消息的局部有序。
举个例子:保证来自同1个order id的消息,是有序的!
下面就看一下在Kafka和RocketMQ中,分别是如何对待这个问题的:
Kafka中:发送1条消息的时候,可以指定(topic, partition, key) 3个参数。partiton和key是可选的。
如果你指定了partition,那就是所有消息发往同1个partition,就是有序的。并且在消费端,Kafka保证,1个partition只能被1个consumer消费。
或者你指定key(比如order id),具有同1个key的所有消息,会发往同1个partition。也是有序的。
RocketMQ: RocketMQ在Kafka的基础上,把这个限制更放宽了一步。只指定(topic, key),不指定具体发往哪个队列。也就是说,它更加不希望业务方,非要去要一个全局的严格有序。
Apache Kafka官方保证了partition内部的数据有效性(追加写、offset读);为了提高Topic的并发吞吐能力,可以提高Topic的partition数,并通过设置partition的replica来保证数据高可靠;
但是在多个Partition时,不能保证Topic级别的数据有序性。
因此,如果你们就像死磕kafka,但是对数据有序性有严格要求,那我建议:
- 创建Topic只指定1个partition,这样的坏处就是磨灭了kafka最优秀的特性。
所以可以思考下是不是技术选型有问题, kafka本身适合与流式大数据量,要求高吞吐,对数据有序性要求不严格的场景。
2. 在Producer往Kafka插入数据时,控制同一Key分发到同一Partition,并且设置参数max.in.flight.requests.per.connection=1,也即同一个链接只能发送一条消息,如此便可严格保证Kafka消息的顺序
再谈谈数据一致性保证:
一致性定义:若某条消息对client可见,那么即使Leader挂了,在新Leader上数据依然可以被读到
HW-HighWaterMark: client可以从Leader读到的最大msg offset,即对外可见的最大offset, HW=max(replica.offset)
对于Leader新收到的msg,client不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被client消费,这样就保证了如果Leader fail,该消息仍然可以从新选举的Leader中获取。
对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
数据存储
Topic
一类消息称为一个Topic
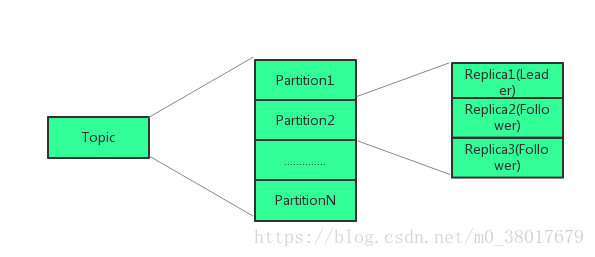
Topic可分为多个Parition;
Parition内部保证数据的有序,按照消息写入顺序给每个消息赋予一个递增的offset;
为保证数据的安全性,每个Partition有多个Replica
多Parition的优点
并发读写,加快读写速度
多Partition分布式存储,利于集群数据的均衡
加快数据恢复的速率:当某台机器挂了,每个Topic仅需恢复一部分的数据,多机器并发
缺点
Partition间Msg无序,若想保证Msg写入与读取的序不变,只能申请一个Partition
Partition
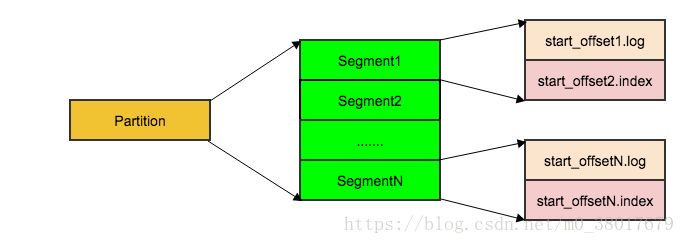
每个Partition分为多个Segment
每个Segment包含两个文件:log文件和index文件,分别命名为start_offset.log和start_offset.index
log文件包含具体的msg数据,每条msg会有一个递增的offset
Index文件是对log文件的索引:每隔一定大小的块,索引msg在该segment中的相对offset和在log文件中的位置偏移量

根据msg的offset和log文件名中的start_offset,找到最后一个不大于msgoffset的segment,即为msg所在的segment;
根据对应segment的index文件,进一步查找msg在log文件中的偏移量
从log文件的偏移量开始读取解析msg,比较msgoffset,找到所要读取的msg
Partition recovery过程
每个Partition会在磁盘记录一个RecoveryPoint, 记录已经flush到磁盘的最大offset。当broker fail 重启时,会进行loadLogs。首先会读取该Partition的RecoveryPoint,找到包含RecoveryPoint的segment及以后的segment, 这些segment就是可能没有完全flush到磁盘segments。然后调用segment的recover,重新读取各个segment的msg,并重建索引
优点
以segment为单位管理Partition数据,方便数据生命周期的管理,删除过期数据简单
在程序崩溃重启时,加快recovery速度,只需恢复未完全flush到磁盘的segment
通过命名中offset信息和index文件,大大加快msg查找时间,并且通过分多个Segment,每个index文件很小,查找速度更快
数据的同步
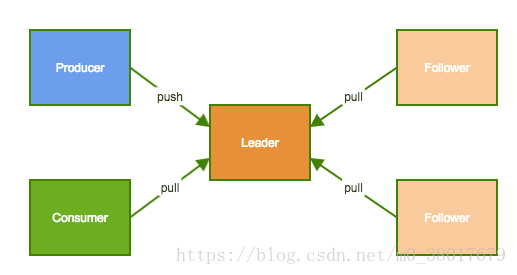
Partition的多个replica中一个为Leader,其余为follower
Producer只与Leader交互,把数据写入到Leader中
Followers从Leader中拉取数据进行数据同步
Consumer只从Leader拉取数据
ISR:所有不落后的replica集合, 不落后有两层含义:距离上次FetchRequest的时间不大于某一个值或落后的消息数不大于某一个值,Leader失败后会从ISR中选取一个Follower做Leader
数据可靠性保证
当Producer向Leader发送数据时,可以通过acks参数设置数据可靠性的级别
0: 不论写入是否成功,server不需要给Producer发送Response,如果发生异常,server会终止连接,触发Producer更新meta数据;
1: Leader写入成功后即发送Response,此种情况如果Leader fail,会丢失数据
-1: 等待所有ISR接收到消息后再给Producer发送Response,这是最强保证
仅设置acks=-1也不能保证数据不丢失,当Isr列表中只有Leader时,同样有可能造成数据丢失。要保证数据不丢除了设置acks=-1, 还要保证ISR的大小大于等于2,具体参数设置:
request.required.acks:设置为-1 等待所有ISR列表中的Replica接收到消息后采算写成功;
min.insync.replicas: 设置为大于等于2,保证ISR中至少有两个Replica
Producer要在吞吐率和数据可靠性之间做一个权衡
数据一致性保证
一致性定义:若某条消息对client可见,那么即使Leader挂了,在新Leader上数据依然可以被读到
HW-HighWaterMark: client可以从Leader读到的最大msg offset,即对外可见的最大offset, HW=max(replica.offset)
对于Leader新收到的msg,client不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被client消费,这样就保证了如果Leader fail,该消息仍然可以从新选举的Leader中获取。
对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
HDFS数据组织
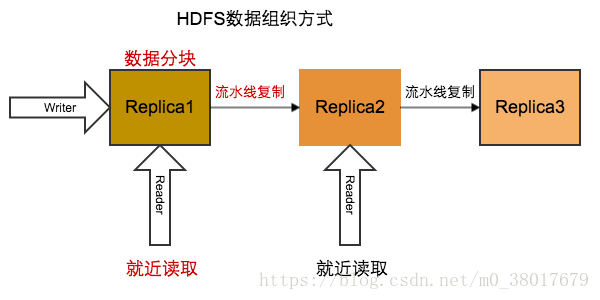
数据分块,比如以64M为一个数据块;
流水线复制:每个数据块没有Leader和Follower之分,采用流水线的方式进行数据复制;
就近读取:为了减少读取时的网路IO,采用就近读取,加快读取速率
解决KafKa数据存储与顺序一致性保证的更多相关文章
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- kafka 数据存储结构+原理+基本操作命令
数据存储结构: Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的.每个topic又可以分成几个不同的partition(每个topic有几个partitio ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- kafka 数据存储和发送
摘要 前面我们已经解释获取和更新metadata以及重要性,那么如何给topic 发送数据? kafkaclient和broker通信,有很多种情况,核心的broker提供的接口有6个 元数据接口(M ...
- Java内存模型(三)原子性、内存可见性、重排序、顺序一致性、volatile、锁、final
一.原子性 原子性操作指相应的操作是单一不可分割的操作.例如,对int变量count执行count++d操作就不是原子性操作.因为count++实际上可以分解为3个操作:(1)读取变量co ...
- Java内存模型深度解析:顺序一致性--转
原文地址:http://www.codeceo.com/article/java-memory-3.html 数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据 ...
- java内存模型-顺序一致性
数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java 内存模型规范对数据竞争的定义如下: 在一个线程中写一个变量, 在另一个线程读同一个变量, 而且写和读没有通过同步来排序. 当代 ...
- 深入理解Java内存模型(三)——顺序一致性
数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据竞争的定义如下: 在一个线程中写一个变量, 在另一个线程读同一个变量, 而且写和读没有通过同步来排序. 当代码 ...
- 【转】深入理解Java内存模型(三)——顺序一致性
数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据竞争的定义如下: 在一个线程中写一个变量, 在另一个线程读同一个变量, 而且写和读没有通过同步来排序. 当代码 ...
随机推荐
- GreenDao设置数据版本
GreenDao设置数据库版本增加后,会自动删除并创建新数据库,将SCHEMA_VERSION增加即可. 在3.0里可以在config配置里进行设置 apply plugin: 'com.androi ...
- ASP.NET Web API 2 之 HttpRequestMessage 对象
Ø 前言 在 Web API 中经常会使用到 HttpRequestMessage 和 HttpResponseMessage 对象,这两个对象封装了对 Web API 的请求和响应,位于 Syst ...
- 【bzoj 2049】Cave 洞穴勘测
Description 辉辉热衷于洞穴勘测.某天,他按照地图来到了一片被标记为JSZX的洞穴群地区.经过初步勘测,辉辉发现这片区域由n个洞穴(分别编号为1到n)以及若干通道组成,并且每条通道连接了恰好 ...
- 【BZOJ】2286: [Sdoi2011]消耗战 虚树+DP
[题意]给定n个点的带边权树,每次询问给定ki个特殊点,求隔离点1和特殊点的最小代价.n<=250000,Σki<=500000. [算法]虚树+DP [题解]考虑普通树上的dp,设f[x ...
- VGG-16详解
VGG16输入224*224*3的图片,经过的卷积核大小为3x3x3,stride=1,padding=1,pooling为采用2x2的max pooling方式: 1.输入224x224x3的图片, ...
- linux scanf函数%d后加空白
参考链接: https://bbs.csdn.net/topics/390389059 关键点: scanf()中空白字符(包括/n,space)会使scanf()函数在读操作中略去输入中的零个或者一 ...
- python - 条件语句/循环语句/迭代器
条件测试:if 条件表达式python 的比较操作 所有的python对象都支持比较操作 可用于测试相等性.相对大小等 如果是复合对象,pyt ...
- Django中session的基础了解
基于cookie做用户验证时:敏感信息不适合放在cookie中 session依赖cookie session原理 cookie是保存在用户浏览器端的键值对 session是保存在服务器端的键值对 s ...
- mybatis中useGeneratedKeys和keyProperty的作用
在使用mybatis时,常常会出现这种需求: 当主键是自增的情况下,添加一条记录的同时,其主键是不能使用的,但是有时我们需要该主键,这时我们该如何处理呢?这时我们只需要在其对应xml中加入以下属性即可 ...
- Python学习笔记-数字类型
如何定义一个数字类型 定义var1为一个INT类型,所以在5/3 输出的是 1. var1 = 5 var1=var1/3 print var1 定义var1为一个INT类型,因为var1是INT类型 ...