Linux查看机器负载
负载(load)是linux机器的一个重要指标,直观了反应了机器当前的状态。如果机器负载过高,那么对机器的操作将难以进行。
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
查看服务器负载有多种命令,w或者uptime都可以直接展示负载,
$ uptime
12:20:30 up 44 days, 21:46, 2 users, load average: 8.99, 7.55, 5.40
$ w
12:22:02 up 44 days, 21:48, 2 users, load average: 3.96, 6.28, 5.16
load average分别对应于过去1分钟,5分钟,15分钟的负载平均值。
什么是Load?什么是Load Average?
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load
如何判断系统是否已经Over Load
对一般的系统来说,根据cpu数量去判断。如果平均负载始终在1.2以下,而你有2颗cup的机器。那么基本不会出现cpu不够用的情况。也就是Load平均要小于Cpu的数量,一般是会根据15分钟那个load 平均值为首先。
这两个命令只是单纯的反映出负载,linux提供了更为强大,也更为实用的top命令来查看服务器负载。
$top
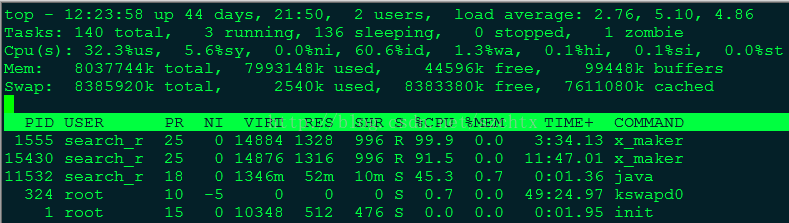
Tasks行展示了目前的进程总数及所处状态,要注意zombie,表示僵尸进程,不为0则表示有进程出现问题。
Cpu(s)行展示了当前CPU的状态,us表示用户进程占用CPU比例,sy表示内核进程占用CPU比例,id表示空闲CPU百分比,wa表示IO等待所占用的CPU时间的百分比。wa占用超过30%则表示IO压力很大。
Mem行展示了当前内存的状态,total是总的内存大小,userd是已使用的,free是剩余的,buffers是目录缓存。
Swap行同Mem行,cached表示缓存,用户已打开的文件。如果Swap的used很高,则表示系统内存不足。
在top命令下,按1,则可以展示出服务器有多少CPU,及每个CPU的使用情况
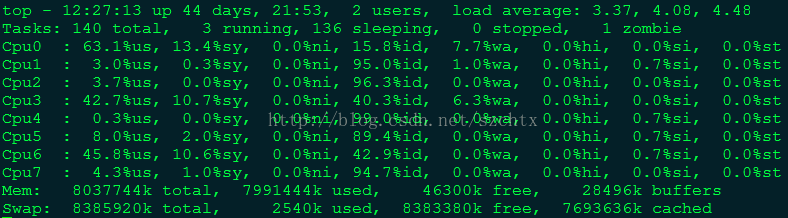
一般而言,服务器的合理负载是CPU核数*2。也就是说对于8核的CPU,负载在16以内表明机器运行很稳定流畅。如果负载超过16了,就说明服务器的运行有一定的压力了。
在top命令下,按shift + "c",则将进程按照CPU使用率从大到小排序,按shift+"p",则将进程按照内存使用率从大到小排序,很容易能够定位出哪些服务占用了较高的CPU和内存。
仅仅有top命令是不够的,因为它仅能展示CPU和内存的使用情况,对于负载升高的另一重要原因——IO没有清晰明确的展示。linux提供了iostat命令,可以了解io的开销。
输入iostat -x 1 10命令,表示开始监控输入输出状态,-x表示显示所有参数信息,1表示每隔1秒监控一次,10表示共监控10次。
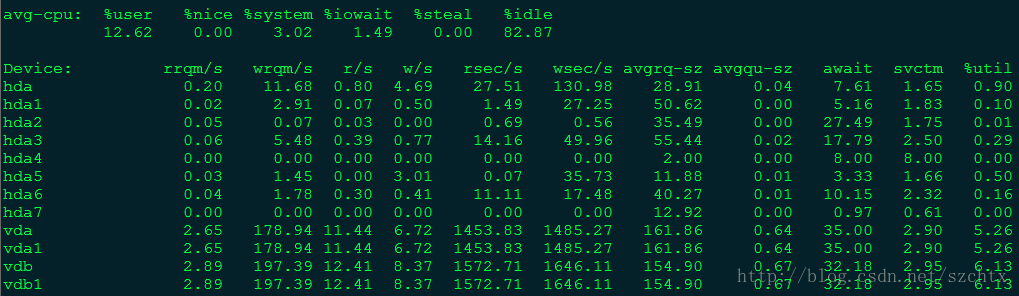
其中rsec/s表示读入,wsec/s表示每秒写入,这两个参数某一个特别高的时候就表示磁盘IO有很大压力,util表示IO使用率,如果接近100%,说明IO满负荷运转。
查看系统负载vmstat
$vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 689568 121068 1397252 0 0 77 8 110 745 4 1 93 1 0
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。 cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比 system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。 cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示) buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。 cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。 swap
si 由内存进入内存交换区数量。 so由内存交换区进入内存数量。 IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。 bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析
Linux查看机器负载的更多相关文章
- 【转】Linux查看机器负载
转自 http://blog.csdn.net/szchtx/article/details/38455385 感谢 负载(load)是Linux机器的一个重要指标,直观了反应了机器当前的状态.如果机 ...
- linux查看系统负载
摘要:number of cores = max load , linux 系统负载高 如何检查? 1:load Average 1.1:什么是Load?什么是Load Average? ...
- Linux 查看系统负载
查看系统负 # 查看系统负载 命令:uptime :: up :, users, load average: 0.00, 0.00, 0.00 注:load average: 0.00, 0.00, ...
- linux 查看机器的cpu,操作系统等命令
看cpu信息,型号,几核 [root@f3 ~]# cat /proc/cpuinfo | grep name | cut -f2 -d:| uniq -c 16 Intel(R) Xeon(R) C ...
- [linux]查看机器有几个cpu,是否支持64位
1. 查看物理CPU的个数#cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l 2. 查看逻辑CPU的个数#cat /pr ...
- linux 查看系统负载:uptime
uptime命令用于查看系统负载,跟 w 命令的输出内容一致 [root@mysql ~]# uptime :: up days, :, user, load average: 1.12, 0.97, ...
- Linux查看机器和硬盘的SN
查看硬件RAID中某块硬盘SN # sas 口: [root@ ~]$ smartctl -a /dev/sda -d megaraid,n *** Serial number: 6RJ974SR * ...
- Linux查看系统负载常用命令
1.查看负载 uptime :: up day, :, user, load average: 0.00, 0.00, 0.00 在过去1分钟.5分钟.15分钟内平均进程数量 2.查看用户 w :: ...
- linux 查看机器内存方法 (free命令)
工作中遇到了统计机器内存的问题.记录一下. free命令可以查看那机器内存. 如下图单位是M 查看man free可以知道,也可以直接从/proc/meminfo文件中读取.
随机推荐
- 团队第九次 # scrum meeting
github 本此会议项目由PM召开,召开时间为4-14日晚上9点,以大家在群里讨论为主 召开时长10分钟 任务表格 袁勤 负责协调前后端 https://github.com/buaa-2016/p ...
- mvc开发中DTO,DO,FROM的区别
DO:数据库实体类映射到model里的实体类,每个字段都和数据库相对应,一般来说开发的时候不要去添加或者修改里面的实体 DTO:与前台交互的时候(一般来说是查询操作)有一些数据字段是那一张表里面没有囊 ...
- (Python基础)简单购物车代码
以下是最简单,最基础的购物车代码,一起学习,一起参考.product_list = [ ('Iphone',5800), ('Mac Pro',15800), ('car',580000), ('co ...
- H5-meta标签使用大全
meta标签有下面的作用:搜索引擎优化(提高搜索性能),控制页面功能化. meta标签的组成:meta标签共有两个属性,它们分别是http-equiv属性和name属性. 1.name属性 name属 ...
- 关于XML的小思考
最近一段时间又接触了XML语言,现在看来它是一种可扩展标记语言,它的格式是标签语言,例如<>****<>此类,它在动态编译中有重要的作用,举个例子,一个班级里有37个人,到学期 ...
- redis的使用与 django的redis的使用
1. 使用redis数据库分为两种: 第一种是在python语言中直接使用的方式, 第二种就是在django中使用django_redis模块来数用 第一种直接在python语言中使用redis im ...
- spring三大核心
IOC(控制反转) 下面是多个针对此理解的表达. 一个对象A依赖另一个对象B就要自己去new 这是高度耦合的 IOC容器的使用. 比如在B中使用A很多,哪一天A大量更改,那么B中就要修改好多代码. 通 ...
- 把nginx当完全tcp端口转发器
在nginx.conf里加入 stream { server { listen 18443; proxy_pass 58.xxx.xxx.xxx:8443; ...
- UE4AI行为树笔记
- <Dare To Dream>第五次作业:团队项目需求改进与系统设计
任务1完成情况: a.分析<家教服务管理系统需求规格说明书>初稿的不足: uml建模不完整,无类图.流程图,仅有的用例图也不规范. b.功能分析的四个象限: c. 团队项目的WBS: d. ...