利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍
Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样。由于这个性质,Selenium也是一个强大的网络数据采集工具,其可以让浏览器自动加载页面,这样,使用了异步加载技术的网页,也可获取其需要的数据。
Selenium模块是Python的第三方库,可以通过pip进行安装:
|
pip3 install selenium |
Selenium自己不带浏览器,需要配合第三方浏览器来使用。通过help命令查看Selenium的Webdriver功能,查看Webdriver支持的浏览器:
|
from selenium import webdriver help(webdriver) |
查看执行后的结果,如下图所示:
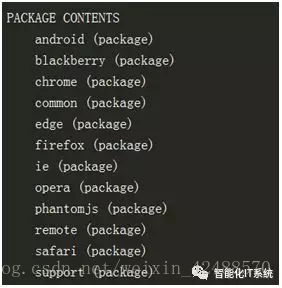
在这个案例中,采用PhantomJS。Selenium和PhantomJS的配合使用可以完全模拟用户在浏览器上的所有操作,包括输入框内容填写、单击、截屏、下滑等各种操作。这样,对于需要登录的网站,用户可以不需要通过构造表单或提交cookie信息来登录网站。
二. 案例介绍
这里所举的案例,是利用Selenium爬取淘宝商品信息,爬取的内容为淘宝网(https://www.taobao.com/)上男士短袖的商品信息,如下图所示:
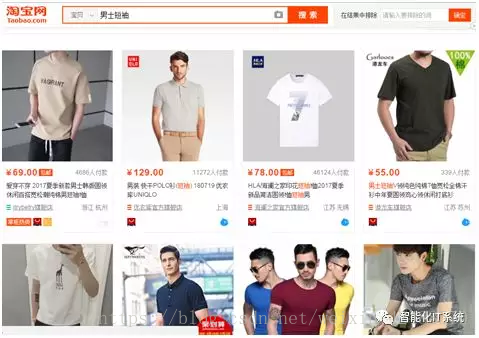
这里可以看到,在用户输入淘宝后,需要模拟输入,在输入框输入“男士短袖”。
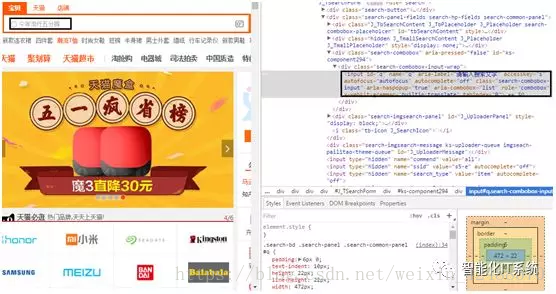
案例中使用Selenium和PhantomJS,模拟电脑的搜索操作,输入商品名称进行搜索,如图所示,“检查”搜索框元素。
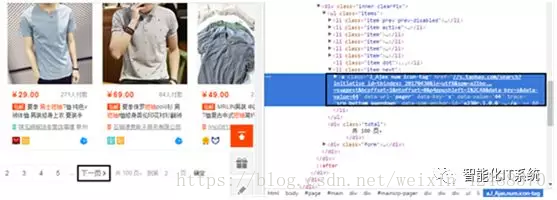
并且如下图所示,“检查”下一页元素:
爬取的内容有商品价格、付款人数、商品名称、商家名称和地址,如下图所示:
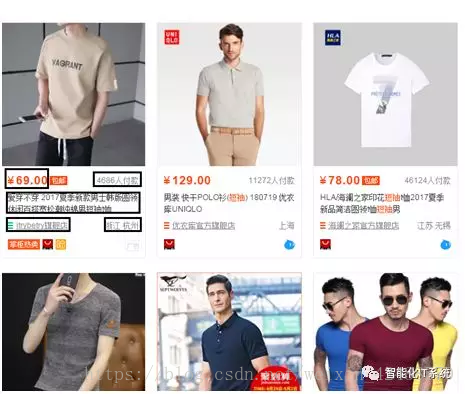
最后把爬取数据存储到MongoDB数据库中。
三. 相关技术
这里把除了selenium之外所需要的知识列一下,这里就不做详细解释了,如果不清楚的话可以百度了解下。
mongoDB的使用,以及在python中用mongodb进行数据存储。
lxml,爬虫三大方法之一,解析效率比较高,使用难度相比正则表达式要低(上一篇文章的解析方法是正则表达式)。
间歇休息的方法:driver.implicitly_wait
四. 源代码
代码如下所示,可复制直接执行:
from selenium import webdriver
from lxml import etree
import time
import pymongo client = pymongo.MongoClient('localhost', 27017)
mydb = client['mydb']
taobao = mydb['taobao'] driver = webdriver.PhantomJS()
driver.maximize_window() def get_info(url,page):
page = page + 1
driver.get(url)
driver.implicitly_wait(10)
selector = etree.HTML(driver.page_source)
infos = selector.xpath('//div[@class="item J_MouserOnverReq"]') for info in infos:
data = info.xpath('div/div/a')[0]
goods = data.xpath('string(.)').strip()
price = info.xpath('div/div/div/strong/text()')[0]
sell = info.xpath('div/div/div[@class="deal-cnt"]/text()')[0]
shop = info.xpath('div[2]/div[3]/div[1]/a/span[2]/text()')[0]
address = info.xpath('div[2]/div[3]/div[2]/text()')[0]
commodity = {
'good':goods,
'price':price,
'sell':sell,
'shop':shop,
'address':address
}
taobao.insert_one(commodity) if page <= 50:
NextPage(url,page)
else:
pass def NextPage(url,page):
driver.get(url)
driver.implicitly_wait(10)
driver.find_element_by_xpath('//a[@trace="srp_bottom_pagedown"]').click()
time.sleep(4)
driver.get(driver.current_url)
driver.implicitly_wait(10)
get_info(driver.current_url,page) if __name__ == '__main__':
page = 1
url = 'https://www.taobao.com/'
driver.get(url)
driver.implicitly_wait(10)
driver.find_element_by_id('q').clear()
driver.find_element_by_id('q').send_keys('男士短袖')
driver.find_element_by_class_name('btn-search').click()
get_info(driver.current_url,page)
五. 代码解析
(1)1~4行
导入程序需要的库,selenium库用于模拟请求和交互。lxml解析数据。pymongo是mongoDB 的交互库。
(2)6~8行
打开mongoDB,进行存储准备。
(3)10~11行
最大化PhantomJS窗口。
(4)14~33行
利用lxml抓取网页数据,分别定位到所需要的信息,并把信息集成至json,存储至mongoDB。
(5)35~47行
分页处理。
(5)51~57行
利用selenium模拟输入“男士短袖”,并模拟点击操作,并获取到对应的页面信息,调取主方法解析。
———————————————————
公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。

利用Selenium爬取淘宝商品信息的更多相关文章
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
- 爬取淘宝商品信息,放到html页面展示
爬取淘宝商品信息 import pymysql import requests import re def getHTMLText(url): kv = {'cookie':'thw=cn; hng= ...
- 使用Selenium爬取淘宝商品
import pymongo from selenium import webdriver from selenium.common.exceptions import TimeoutExceptio ...
- selenium+pyquery爬取淘宝商品信息
import re from selenium import webdriver from selenium.common.exceptions import TimeoutException fro ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- Selenium爬取淘宝商品概要入mongodb
准备: 1.安装Selenium:终端输入 pip install selenium 2.安装下载Chromedriver:解压后放在…\Google\Chrome\Application\:如果是M ...
- selenium+phantomjs+pyquery 爬取淘宝商品信息
from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium ...
随机推荐
- C# 结合 using 语句块的三种实用方法
一.简介 阅读 Abp 源码的过程中,自己也学习到了一些之前没有接触过的知识.在这里,我在这儿针对研究学习 Abp 框架中,遇到的一些值得分享的知识写几篇文章.如果有什么疑问或者问题,欢迎大家评论指正 ...
- sql server 备份与恢复系列五 完整模式下的备份与还原
一.概述 前面介绍了简单恢复模式和大容量恢复模式,这篇继续写完整恢复模式下的备份与还原.在完整恢复模式里最大的优点是只要能成功备份尾日志,就可以还原到日志备份内包含的任何时点("时点恢复&q ...
- Android布局:宽度适应的横向跟随,防止挤掉重要视图
不知道这样的布局该怎么描述,标题也是乱取的..直接上图吧 最近遇到了这样要求的布局: 1.上图中的“标题”长度不定,“状态”标签可能有多个并紧跟在标题右边,“属性”一直居右显示: 2.当“标题”过长, ...
- .Net和C#介绍
一.前言 本文主要针对刚入门以及还需要对基础进行恶补一下的兄弟进行基础介绍,并尽可能的做到客观,如有错误也虚心接受高手门的纠正. 二..Net平台简介 .net即DotNet,首先我先给出微软的定义: ...
- 【Go】优雅的读取http请求或响应的数据
[Go]优雅的读取http请求或响应的数据 原文链接:https://blog.thinkeridea.com/201901/go/you_ya_de_du_qu_http_qing_qiu_huo_ ...
- MAC 地址(单播、组播、广播地址分类)
简介 一个制造商在生产制造网卡之前,必须先向 IEEE 注册,以获取到一个长度为 24bit 的厂商代码,也称为 OUI(Organizationally-Unique Identifier).制造商 ...
- Redis Cluster集群架构实现(四)--技术流ken
Redis集群简介 通过前面三篇博客的介绍<Redis基础认识及常用命令使用(一)--技术流ken>,<Redis基础知识补充及持久化.备份介绍(二)--技术流ken>,< ...
- [转]Ubuntu18.04下使用Docker Registry快速搭建私有镜像仓库
本文转自:https://blog.csdn.net/BigData_Mining/article/details/88233015 1.背景 在 Docker 中,当我们执行 docker pull ...
- WebBrowser引用IE版本问题,更改使用高版本IE
做了一个Winform的项目.项目里使用了WebBrowser控件.以前一直都以为WebBrowser是直接调用的系统自带的IE,IE是呈现出什么样的页面WebBrowser就呈现出什么样的页面.其实 ...
- 博客使用base64编码图片测试
为了解决发博客时需要先要上传,所以查了一下这个方法 1.把本地图片转为base64编码的字符串, 网上有很多提供这个功能的网站,转换后像这样 data:image/jpeg;base64,/9j/4A ...