定时任务调度-Celery
确保任务不重叠解决方法:
- from celery import task
- from celery.five import monotonic
- from celery.utils.log import get_task_logger
- from contextlib import contextmanager
- from django.core.cache import cache
- from hashlib import md5
- from djangofeeds.models import Feed
- logger = get_task_logger(__name__)
- LOCK_EXPIRE = 60 * 10 # Lock expires in 10 minutes
- @contextmanager
- def memcache_lock(lock_id, oid):
- timeout_at = monotonic() + LOCK_EXPIRE - 3
- # cache.add fails if the key already exists
- status = cache.add(lock_id, oid, LOCK_EXPIRE)
- try:
- yield status
- finally:
- # memcache delete is very slow, but we have to use it to take
- # advantage of using add() for atomic locking
- if monotonic() < timeout_at and status:
- # don't release the lock if we exceeded the timeout
- # to lessen the chance of releasing an expired lock
- # owned by someone else
- # also don't release the lock if we didn't acquire it
- cache.delete(lock_id)
- @task(bind=True)
- def import_feed(self, feed_url):
- # The cache key consists of the task name and the MD5 digest
- # of the feed URL.
- feed_url_hexdigest = md5(feed_url).hexdigest()
- lock_id = '{0}-lock-{1}'.format(self.name, feed_url_hexdigest)
- logger.debug('Importing feed: %s', feed_url)
- with memcache_lock(lock_id, self.app.oid) as acquired:
- if acquired:
- return Feed.objects.import_feed(feed_url).url
- logger.debug(
- 'Feed %s is already being imported by another worker', feed_url)
celery 特性:
Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。由于在工作的平台中用到Celery系统(用于发送邮件、发送短信、发送上线等任务),记录一下学习的知识。
使用rabbitmq做celery的broker和redis做celery的broker的特性
使用RabbitMQ作为Celery Broker的优点:
Highly customizable routing(高度定制路由)
Persistent queues(一致性队列)
使用redis作为celery brocker的优点:
high speed due to in memory datastore(速度极快的内存数据库)
can double up as both key-value datastore and job queue(可以保证key-value 数据存储及job序列)
celery-安装
pip3 install celery(4.0版本celery beat不支持热加载)
celery-flower监控安装
pip3 install flower
django celery 安装
pip3 install django-celery
celery 原理介绍
某个方法的消息请求celery执行,首先celery根据绑定的规则把任务消息放到制定的路由队列中去,此队列对应的worker节点取出执行。
说明:
为什么要定义多个worker?每个worker都会新建一个进程,充分利用服务器资源,提高执行效率。
同一个服务器可以启动多个worker节点?可以,启动参数里面写上不同的–hostname即可。
celery默认会创建一个celery任务队列,没有任何绑定的任务将会发送到此消息队列中。
celery 多woker实验
celery加redis的多节点配置实例,由于资源限制只找了两台机器做测试
- 10.10.42.33
- 10.10.190.234
我们把redis服务放在10.10.190.234那台服务器上
我们把flower服务也启动在10.10.42.33那台服务器上
代码中定义的队列有queue_add、queue_sum (还有个默认队列celery)
33、234服务器用于启动worker节点
33服务器上启动处理celery和queue_add队列的worker节点
234服务器上启动处理celery和queue_sum队列的worker节点
配置文件展示
celeryconfig配置文件:
- cat celeryconfig.py
- #!/usr/bin/python
- #coding:utf-8
- from kombu import Queue
- CELERY_TIMEZONE = 'Asia/Shanghai'
- ####################################
- # 一般配置 #
- ####################################
- CELERY_TASK_SERIALIZER = 'json'
- CELERY_RESULT_SERIALIZER = 'json'
- CELERY_ACCEPT_CONTENT=['json']
- CELERY_TIMEZONE = 'Asia/Shanghai'
- CELERY_ENABLE_UTC = True
- # List of modules to import when celery starts.
- CELERY_IMPORTS = ('tasks', )
- CELERYD_MAX_TASKS_PER_CHILD = 40 # 每个worker执行了多少任务就会死掉
- BROKER_POOL_LIMIT = 10 #默认celery与broker连接池连接数
- CELERY_DEFAULT_QUEUE='default'
- CELERY_DEFAULT_ROUTING_KEY='task.default'
- CELERY_RESULT_BACKEND='redis://:fafafa@10.10.190.234:6379/0'
- BROKER_URL='redis://:fafafa@10.19.190.234:6379/0'
- #默认队列
- CELERY_DEFAULT_QUEUE = 'celery' #定义默认队列
- CELERY_DEFAULT_ROUTING_KEY = 'celery' #定义默认路由
- CELERYD_LOG_FILE="./logs/celery.log"
- CELERY_QUEUES = (
- Queue("queue_add", routing_key='queue_add'),
- Queue('queue_reduce', routing_key='queue_sum'),
- Queue('celery', routing_key='celery'),
- )
- CELERY_ROUTES = {
- 'task.add':{'queue':'queue_add', 'routing_key':'queue_add'},
- 'task.reduce':{'queue':'queue_reduce', 'routing_key':'queue_sum'},
- }
查看任务配置文件:
cat task.py
- import os
- import sys
- import datetime
- BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
- sys.path.append(BASE_DIR)
- from celery import Celery
- from celery import chain, group, chord, Task
- from celeryservice import celeryconfig
- app = Celery()
- app.config_from_object(celeryconfig)
- __all__ = ['add', 'reduce','sum_all', 'other']
- ####################################
- # task定义 #
- ####################################
- @app.task
- def add(x, y):
- return x + y
- @app.task
- def reduce(x, y):
- return x - y
- @app.task
- def sum(values):
- return sum([int(value) for value in values])
- @app.task
- def other(x, y):
- return x * y
flower任务配置文件
cat flower.py
- #!/usr/bin/env python
- #coding:utf-8
- broker_api = 'redis://:afafafafa@10.10.190.234:6379/0'
- logging = 'DEBUG'
- address = '0.0.0.0'
- port = 5555
- basic_auth = ['zero:zero'] #外部访问密码
- persistent=True #持久化celery tasks(如果为false的话,重启flower之后,监控的task就消失了)
- db="./flower/flower_db"
启动服务:
在33上启动服务
- celery worker -A task --loglevel=info --queues=celery,queue_add --hostname=celery_worker33 >/dev/null 2>&1 &
在234上启动服务
- celery worker -A task --loglevel=info --queues=celery,queue_add --hostname=celery_worker33 >/dev/null 2>&1 &
服务验证:
在任一台有celeryservice项目代码的服务器上,运行add、reduce、sum、other任务(测试可简单使用add.delay(1,2)等)
add只会在33上运行,
sum任务,可能会在33或234服务器的worker节点运行
reduce任务,只会在234上运行。
other任务可能会在33或者234上运行。
关于使用过程中的优化
使用celery的错误处理机制
如下内容来自于网站,还没实践,存档用。
大多数任务并没有使用错误处理,如果任务失败,那就失败了。在一些情况下这很不错,但是作者见到的多数失败任务都是去调用第三方API然后出现了网络错误,
或者资源不可用这些错误,而对于这些错误,最简单的方式就是重试一下,也许就是第三方API临时服务或者网络出现问题,没准马上就好了,那么为什么不试着加个重试测试一下呢?
- @app.task(bind=True, default_retry_delay=300, max_retries=5)
- def my_task_A():
- try:
- print("doing stuff here...")
- except SomeNetworkException as e:
- print("maybe do some clenup here....")
- self.retry(e)
定时任务遇到的问题:
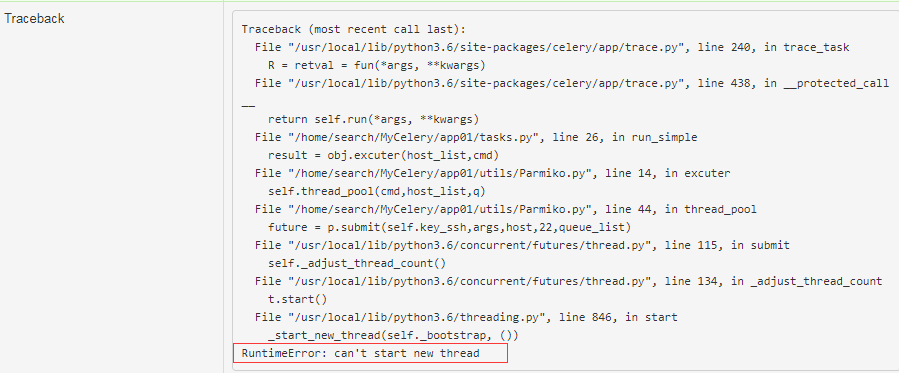
通过flower 查看 跑多线程报错, 需要减少线程数.
celery配置文件的一些详细解释:
- # -*- coding:utf-8 -*-
- from datetime import timedelta
- from settings import REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, REDIS_DB_NUM
- # 某个程序中出现的队列,在broker中不存在,则立刻创建它
- CELERY_CREATE_MISSING_QUEUES = True
- CELERY_IMPORTS = ("async_task.tasks", "async_task.notify")
- # 使用redis 作为任务队列
- BROKER_URL = 'redis://:' + REDIS_PASSWORD + '@' + REDIS_HOST + ':' + str(REDIS_PORT) + '/' + str(REDIS_DB_NUM)
- #CELERY_RESULT_BACKEND = 'redis://:' + REDIS_PASSWORD + '@' + REDIS_HOST + ':' + str(REDIS_PORT) + '/10'
- CELERYD_CONCURRENCY = 20 # 并发worker数
- CELERY_TIMEZONE = 'Asia/Shanghai'
- CELERYD_FORCE_EXECV = True # 非常重要,有些情况下可以防止死锁
- CELERYD_PREFETCH_MULTIPLIER = 1
- CELERYD_MAX_TASKS_PER_CHILD = 100 # 每个worker最多执行万100个任务就会被销毁,可防止内存泄露
- # CELERYD_TASK_TIME_LIMIT = 60 # 单个任务的运行时间不超过此值,否则会被SIGKILL 信号杀死
- # BROKER_TRANSPORT_OPTIONS = {'visibility_timeout': 90}
- # 任务发出后,经过一段时间还未收到acknowledge , 就将任务重新交给其他worker执行
- CELERY_DISABLE_RATE_LIMITS = True
- # 定时任务
- CELERYBEAT_SCHEDULE = {
- 'msg_notify': {
- 'task': 'async_task.notify.msg_notify',
- 'schedule': timedelta(seconds=10),
- #'args': (redis_db),
- 'options' : {'queue':'my_period_task'}
- },
- 'report_result': {
- 'task': 'async_task.tasks.report_result',
- 'schedule': timedelta(seconds=10),
- #'args': (redis_db),
- 'options' : {'queue':'my_period_task'}
- },
- #'report_retry': {
- # 'task': 'async_task.tasks.report_retry',
- # 'schedule': timedelta(seconds=60),
- # 'options' : {'queue':'my_period_task'}
- #},
- }
- ################################################
- # 启动worker的命令
- # *** 定时器 ***
- # nohup celery beat -s /var/log/boas/celerybeat-schedule --logfile=/var/log/boas/celerybeat.log -l info &
- # *** worker ***
- # nohup celery worker -f /var/log/boas/boas_celery.log -l INFO &
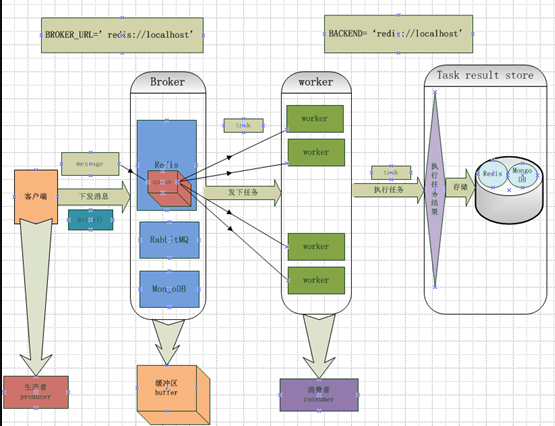
celery整体架构图:
定时任务调度-Celery的更多相关文章
- python中的轻量级定时任务调度库:schedule
提到定时任务调度的时候,相信很多人会想到芹菜celery,要么就写个脚本塞到crontab中.不过,一个小的定时脚本,要用celery的话太“重”了.所以,我找到了一个轻量级的定时任务调度的库:sch ...
- 11: python中的轻量级定时任务调度库:schedule
1.1 schedule 基本使用 1.schedule 介绍 1. 提到定时任务调度的时候,相信很多人会想到芹菜celery,要么就写个脚本塞到crontab中. 2. 不过,一个小的定时脚本,要用 ...
- [源码分析] 定时任务调度框架 Quartz 之 故障切换
[源码分析] 定时任务调度框架 Quartz 之 故障切换 目录 [源码分析] 定时任务调度框架 Quartz 之 故障切换 0x00 摘要 0x01 基础概念 1.1 分布式 1.1.1 功能方面 ...
- #研发中间件介绍#定时任务调度与管理JobCenter
郑昀 最后更新于2014/11/11 关键词:定时任务.调度.监控报警.Job.crontab.Java 本文档适用人员:研发员工 没有JobCenter时我们要面对的: 电商业务链条很长,业 ...
- Java定时任务调度详解
前言 在实际项目开发中,除了Web应用.SOA服务外,还有一类不可缺少的,那就是定时任务调度.定时任务的场景可以说非常广泛,比如某些视频网站,购买会员后,每天会给会员送成长值,每月会给会员送一些电影券 ...
- Spring4.0.1+Quartz2.2.1实现定时任务调度[亲测可用]
Spring4.0.1+Quartz2.2.1实现定时任务调度[亲测可用] tip:只需要配置xml文件即可 1.第三方依赖包的引入 <properties> <project.bu ...
- SpringQuartz 实现定时任务调度
最近公司新项目需要用到定时器,于是研究了一下发现: Spring中使用Quartz有两种方式实现: 第一种是任务类继承QuartzJobBean 第二种则是在配置文件里定义任务类和要执行的方法,类和方 ...
- 开源一个定时任务调度器 webscheduler
在企业应用中定时任务调度的需求是必不可少的,比如定时同步数据,定时结转数据,定时检测异常等等.公司之前是在使用一款采用.net 开发的windows服务形式的定时程序,基本能满足需求,在一段时间的时候 ...
- 一文揭秘定时任务调度框架quartz
之前写过quartz或者引用过quartz的一些文章,有很多人给我发消息问quartz的相关问题, quartz 报错:java.lang.classNotFoundException quartz源 ...
随机推荐
- Vuex的API文档
前面的话 本文将详细介绍Vuex的API文档 概述 import Vuex from 'vuex' const store = new Vuex.Store({ ...options }) [构造器选 ...
- 排列组合n选m算法
找10组合算法,非递归 http://blog.csdn.net/sdhongjun/article/details/51475302
- Nintex Workflow Get Attachment link
不多解释,直接上图,操作简单
- 前端传递给后端且通过cookie方式,尽量传递id
前端传递给后端且通过cookie方式,尽量传递id
- 醉汉随机行走/随机漫步问题(Random Walk Randomized Algorithm Python)
世界上有些问题看似是随机的(stochastic),没有规律可循,但很可能是人类还未发现和掌握这类事件的规律,所以说它们是随机发生的. 随机漫步(Random Walk)是一种解决随机问题的方法,它 ...
- 【支付宝】"验签出错,sign值与sign_type参数指定的签名类型不一致:sign_type参数值为RSA,您实际用的签名类型可能是RSA2"
问题定位:从描述就可以看的出来了,你现在sign_type是 RSA类型的,要改成跟你现在用的签名类型一致的类型,也就是 要改为 RSA2 PHP为例 // 新版只支持此种签名方式 商户生成签名字符 ...
- Android studio preview界面无法预览,报错render problem
1.查看报错信息,如果有报错,该叹号应为红色,点击查看报错,显示为render problem 2.打开res/styles.xml修改为如图,添加Base. 3.再打开preview界面
- Android里透明的ListView
发现了一个list滚动时,某item背景透明的问题.网上搜索一下,发现有很多人在问list背景黑色的问题,交流中给出的解决方案基本上很统一. 先是解释问题产生的原因是Android对list的滚动做了 ...
- [CF1107E]Vasya and Binary String【区间DP】
题目描述 Vasya has a string s of length n consisting only of digits 0 and 1. Also he has an array a of l ...
- visual studio 阅读 linux-kernel
@2018-12-13 [小记] 使用 visual studio 阅读 linux-kernel 方法 a. 文件 ---> 新建 --->从现有代码创建项目 b. 指定项目存储位置,命 ...