deeplearning 重要调参参数分析
reference: https://blog.csdn.net/jningwei/article/details/79243800
learning rate:学习率,控制模型的学习进度,决定权值更新的速度。也叫做步长,即反向传播算法的 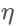
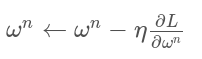
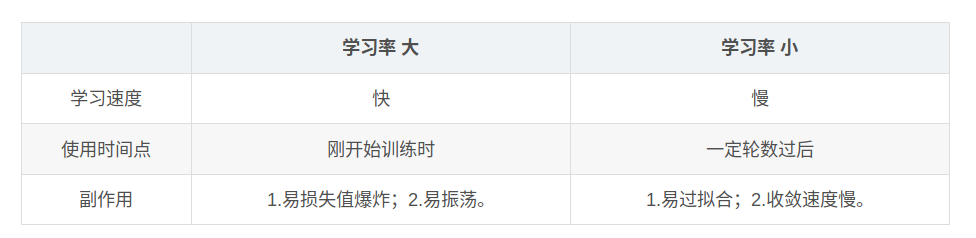
学习率的设置
在训练开始时,根据迭代次数动态设置学习率。
刚开始时,学习率以0.01~0.001 为宜,一定轮数后,开始下降,在快结束时学习率的衰减应该在100倍以上。由于迁移学习,模型已在原始数据上收敛,应设置较小的学习率(<= 0.00001),
在新数据上进行微调。
学习率缓解机制
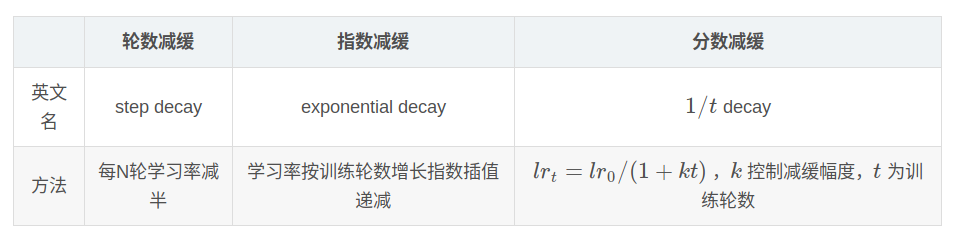
目标函数损失值看lr
理想情况下的损失曲线应该是滑梯式的,绿线所示:
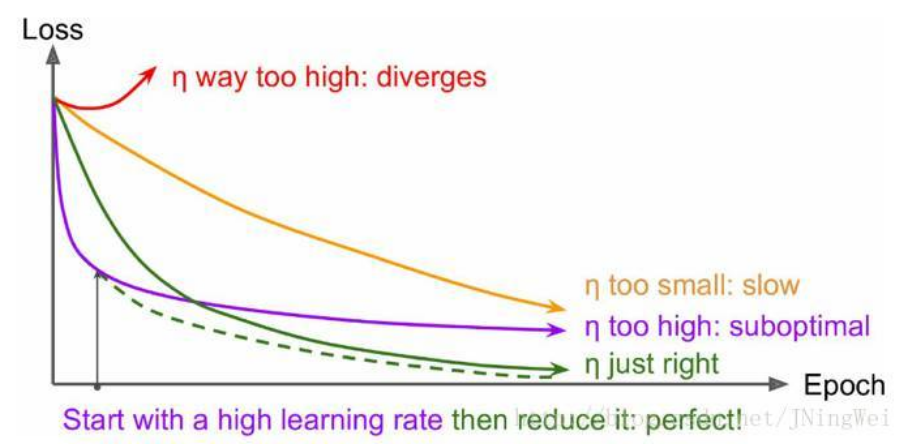
分析 :红线一开始就上扬,说明初始学习率过大,从而导致震荡,应该减小学习率。
黄线初始学习率较小,loss曲线收敛缓慢,易过拟合,应增大初始学习率。
紫线初始学习率过大,导致无法过拟合,应减小学习率。
权重衰减
为了避免网络的过拟合,对cost function引入正则项,作用是减小不重要参数对最后结果的影响,有用的权重不会受到weight decay的影响。过拟合时权重值逐渐变大,在loss function增加一个惩罚项。不是为了提高收敛速度或是收敛精度,正则项指示模型的复杂度,权重衰减调节模型复杂度对损失函数的影响。
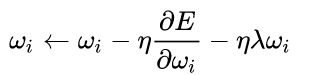
Momentum
基本思想是为了找到最优加入“惯性”的影响,当误差曲面中存在平坦区域时,SGD可以更快的学习。
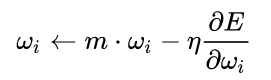
Learning Rate Decay
目的是为了提高SGD的寻优化能力,每次迭代的时候减小学习率的大小。
BN的好处:BN在NeuralNetwork 的激活函数之前,将wx+b按照特征进行标准化处理。
1.Normalization可以使特征缩放至【0,1】,在反向传播时梯度在1左右,避免梯度消失。
2.提高学习速率,标准化后更快达到收敛。
3.减少模型对初始化的依赖。
batch大小的作用
batch决定梯度下降的方向。如果batch size为全体数据集,则确定的方向可以更好的代表样本总体,更加准确的朝向极值的方向。缺点是内存的限制。
如果设置为1,即为在线学习,每次修正方向都以各自样本的梯度方向修正,难以收敛。
在合理的范围内增大batch_size可以提高内存利用率,减少跑完整个数据集的所需要的迭代次数,加快了相对于相同数据量的处理速度。一般设置为8的倍数。
deeplearning 重要调参参数分析的更多相关文章
- word2vec参数调整 及lda调参
一.word2vec调参 ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -neg ...
- xgboost的sklearn接口和原生接口参数详细说明及调参指点
from xgboost import XGBClassifier XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=100,silen ...
- XGBoost和LightGBM的参数以及调参
一.XGBoost参数解释 XGBoost的参数一共分为三类: 通用参数:宏观函数控制. Booster参数:控制每一步的booster(tree/regression).booster参数一般可以调 ...
- XGBoost 重要参数(调参使用)
XGBoost 重要参数(调参使用) 数据比赛Kaggle,天池中最常见的就是XGBoost和LightGBM. 模型是在数据比赛中尤为重要的,但是实际上,在比赛的过程中,大部分朋友在模型上花的时间却 ...
- DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化
DeepMind提出新型超参数最优化方法:性能超越手动调参和贝叶斯优化 2017年11月29日 06:40:37 机器之心V 阅读数 2183 版权声明:本文为博主原创文章,遵循CC 4.0 BY ...
- 机器学习笔记——模型调参利器 GridSearchCV(网格搜索)参数的说明
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数.但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果.这个时候就是需要动脑筋了.数据量比较大 ...
- 漫谈PID——实现与调参
闲话: 作为一个控制专业的学生,说起PID,真是让我又爱又恨.甚至有时候会觉得我可能这辈子都学不会pid了,但是经过一段时间的反复琢磨,pid也不是很复杂.所以在看懂pid的基础上,写下这篇文章,方便 ...
- CatBoost算法和调参
欢迎关注博主主页,学习python视频资源 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?co ...
- GBDT调参总结
一.GBDT类库弱学习器参数 二.回归 数据集:已知用户的30个特征,预测用户的信用值 from sklearn.ensemble import GradientBoostingRegressor f ...
随机推荐
- Django中模板语音变量forloop
forloop.counter 从1开始 forloop.counter0 从0开始 forloop.revcounter 倒序(表示循环中剩余项的整型变量.) forloop.revcount ...
- MySQL:Your password has expired. To log in you must change it using a client that supports expired passwords
MySQL:V5.6.37 安装后发现没远程权限,为了方便,就直接把hostname@root修改为%@root,密码修改为和localhost@root一样 然后尴尬的事情发生了,本地登陆正常,远程 ...
- Linux下的Jenkins+Tomcat+Maven+Git+Shell环境的搭建使用(jenkins自动化部署)【转】
jenkins自动化部署 目标:jenkins上点构建(也可以自动检查代码变化自动构建)>>>项目部署完成. 一.安装jenkins 1.下载jenkins 这里我选择的是war包安 ...
- NodeJS基础教程
关于 本书致力于教会你如何用Node.js来开发应用,过程中会传授你所有所需的“高级”JavaScript知识.本书绝不是一本“Hello World”的教程. 状态 你正在阅读的已经是本书的最终版. ...
- linux系统网络相关问题
暂时将你的 eth0 这张网络卡的 IP 设定为 192.168.1.100 ,如何进行? ifconfig eth0 192.168.1.100 我要增加一个路由规则,以 eth0 连接 192.1 ...
- 高效的多维空间点索引算法 — Geohash 和 Google S2
原文地址:https://www.jianshu.com/p/7332dcb978b2 引子 每天我们晚上加班回家,可能都会用到滴滴或者共享单车.打开 app 会看到如下的界面: app ...
- 关于iwinfo的调试
在调试 主动扫描时,调用命令 “iwinfo wlan0 scan”时, 在iwinfo中添加的调试语句没有打印和记录到log中去. 后查看iwinfo的makefile发现,在生成iwinfo程序 ...
- ES--04
第三十一讲! 分布式文档系统 写一致性原理以及相关参数 课程大纲 (1)consistency,one(primary shard),all(all shard),quorum(default) 我们 ...
- fpm定制化RPM包之nginx rpm包的制作
fpm定制化RPM包之nginx rpm包的制作 1.安装ruby模块 # yum -y install ruby rubygems ruby-devel 2.添加阿里云的Rubygems仓库,国外资 ...
- 【原创】数据库基础之Mysql(3)mysql删除历史binlog
mysql开启binlog后会在/var/lib/mysql下创建binlog文件,如果手工删除,则下次mysql启动会报错: mysqld: File './master-bin.000001' n ...