python3+selenium入门04-元素定位
我们在对浏览界面做操作时,比如点击按钮,搜索框输入内容。都需要把鼠标挪过去,然后再点击,或者输入内容。在selenium操作时也是一样的。需要先对元素进行定位,然后才能进行操作。可以借助浏览器的开发者工具(浏览器F12打开)来查看网页对应的html代码。然后进行定位。可以稍微学习HTML基础,更容易理解。
定位方式有八种,这八种各有两个方法,一个是find_element_by_方式,这是定位单个元素的。一个是find_elements_by_方式,这是用来定位多个元素的。
使用name属性定位
打开谷歌浏览器,打开百度首页,F12呼出开发者工具
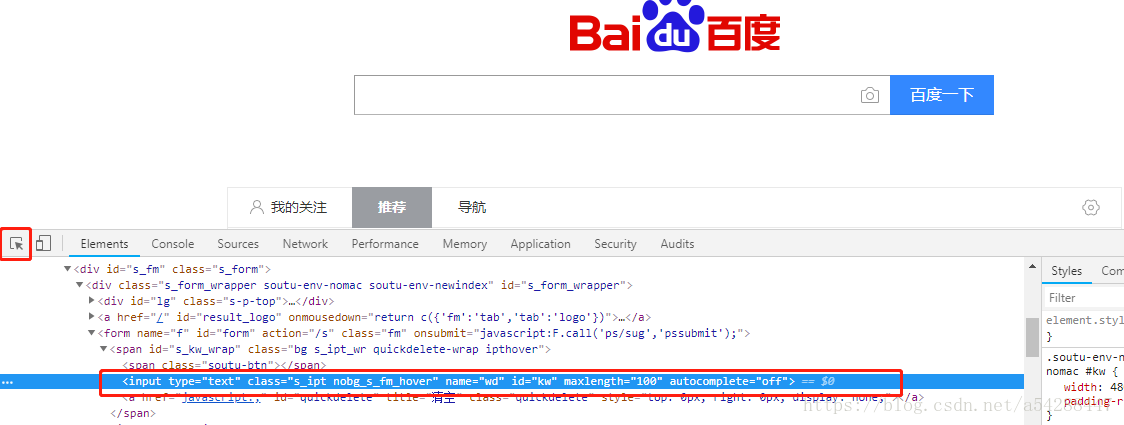
使用左边这个按钮,点击百度搜索框,会自动显示对应HTML代码,可以看到name=‘wd’
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_name('wd')#通过name属性定位输入框
test.send_keys('测试一下')#输入测试一下
使用id属性定位
还是以上面百度搜索框为例,id=‘kw’
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_id('kw')#通过id属性定位输入框
test.send_keys('测试一下')#输入测试一下
通过id和name是比较常用和容易的定位方式。因为一般id和name元素在一个HTML文件中基本是唯一的。不过有时候前端开发也可能不写这两个属性。
使用class定位
还是使用百度搜索框,class='s_ipt'
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_class_name('s_ipt')#通过classname属性定位输入框
test.send_keys('测试一下')#输入测试一下
使用tagname定位

tagname其实就是HTML的标签。不过一个HTML文件里面相同的标签肯定很多,一般很少用到。基本都是定位父元素,然后父元素定位下面所有tagname元素。再根绝其他条件去操作。比如表格啥的。
使用link_text定位
这是用来定位文字超链接的,可以通过文字链接部分的文字描述,定位百度首页上的新闻按钮

from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_link_text('新闻')#通过link_text定位新闻跳转按钮
test.click()#点击按钮
使用partial_link_text定位
这个也是用来定位文字超链接的,和link_text区别在于,这个相当于模糊搜索,只输入部分文字描述就可以了
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_partial_link_text('新')#通过partial_link_text定位新闻跳转按钮
test.click()#点击按钮
使用xpath定位
这个百分百可以定位到,通过层级来的,感兴趣可以学习下xpath的语法,不会也没关系。还是以百度搜索框为例

对着直接右键copy-copy xpath
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_xpath('//*[@id="kw"]')#通过xpath定位搜索框
test.send_keys('测试一下')#输入测试一下
使用css定位
和xpath一样,拷贝的时候选上面的copy-selector就行
from selenium import webdriver dr = webdriver.Chrome()#初始化chrome浏览器实例
dr.maximize_window()#浏览器最大化
dr.get('https://www.baidu.com')#打开百度首页
test = dr.find_element_by_css_selector('#kw')#通过xpath定位搜索框
test.send_keys('测试一下')#输入测试一下
python3+selenium入门04-元素定位的更多相关文章
- selenium+java二元素定位
页面元素定位是自动化中最重要的事情, selenium Webdriver 提供了很多种元素定位的方法. 测试人员应该熟练掌握各种定位方法. 使用最简单,最稳定的定位方法. 自动化测试步骤 定位元素 ...
- selenium自动化之元素定位方法
在使用selenium webdriver进行元素定位时,有8种基本元素定位方法(注意:并非只有8种,总共来说,有16种). 分别介绍如下: 1.name定位 (注意:必须确保name属性值在当前ht ...
- Python3-Selenium自动化测试框架(二)之selenium使用和元素定位
Selenium自动化测试框架(二)之selenium使用和元素定位 (一)selenium的简单使用 1.导包 from selenium import webdriver 2.初始化浏览器 # 驱 ...
- selenium webdriver python 元素定位
总结 定位查找时,返回查找到的第一个match的元素.如果找不到,则 raise NoSuchElementException 单个元素定位: find_element_by_idfind_e ...
- python3+selenium入门10-表单切换
当元素在ifarm或farm中时,需要先进入到表单中,然后才能定位元素进行操作.直接对元素定位.会提示元素无法找到. <!DOCTYPE html> <html> <he ...
- python3+selenium入门07-元素等待
在使用selenium进行操作时,有时候在定位元素时会报错.这可能是因为元素还没有来得及加载导致的.可以等过元素等待,等待元素出现.有强制等待,显式等待,隐式等待. 强制等待 就是之前文章中的time ...
- python3+selenium入门05-元素操作及常用方法
学习了元素定位之后,来看一些元素的操作,还有一些常用的方法 clear()清空输入框内容 click()点击 send_keys()键盘输入 import time from selenium imp ...
- Selenium之WebDriver元素定位方法
Selenium WebDriver 只是 Python 的一个第三方框架, 和 Djangoweb 开发框架属于一个性质. webdriver 提供了八种元素定位方法,python语言中也有对应的方 ...
- 【Selenium专题】元素定位之CssSelector
CssSelector是我最喜欢的元素定位方法,Selenium官网的Document里极力推荐使用CSS locator,而不是XPath来定位元素,原因是CSS locator比XPath loc ...
随机推荐
- 安装FreeIPA以及应用时报错汇总
安装FreeIPA以及应用时报错汇总 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.ERROR DNS zone yinzhengjie.org.cn already exis ...
- Mybatis笔记三:全局配置文件
目录 配置文件 dtd提示 properties标签(不怎么用) typeAliases 自动把下划线换成驼峰命名 配置文件 看着这个配置文件,我们将对这个配置文件进行细致的讲解 <?xml v ...
- cmd命令查看当前IIS运行的网站iisapp appcmd
xp,2003中用的命令是:iisapp -a 2007,2008,2012系统中: cmd命令行进入%windir%\system32\inetsrv\目录下 运行appcmd.exe list w ...
- com.netflix.client.ClientException: Load balancer does not have available server for client xxxx
版本 spring boot: 2.0.1.RELEASE spring cloud: Finchley.M9 错误 通过zuul调用eureka注册的服务,错误内容如下 Caused by: com ...
- ACM-ICPC 2018 南京赛区网络预赛 B The writing on the wall(思维)
https://nanti.jisuanke.com/t/30991 题意 一个n*m的方格矩阵,有的格子被涂成了黑色,问该矩阵中有多少个子矩阵,子矩阵不包含黑色格子. 分析 参考https://bl ...
- 面向对象(Object Orientation Programming)
Three characteristic of object orientation: Encapsulation: capturing data and keeping it safely and ...
- 深入浅出mybatis之入门使用
写在前面 mybatis是一个持久层框架,可以支持SQL定制和存储过程,实现数据库记录到Java POJO对象之间的映射. 所以说,mybatis是一个ORM框架. 这个ORM可以通过2种方式实现:x ...
- Vue.Draggable/SortableJS 的排序功能,在VUE中的使用
此插件git: https://github.com/SortableJS/Vue.Draggable 基于Sortable.js http://www.cnblogs.com/xiangsj/p/6 ...
- Immunity Debugger学习 二
1.Exploit开发 发现漏洞只是一个开始,在你完成利用程序之前,还有很长一段路要走.不过Immunity专门为了这项任务做了许多专门设计,相信能帮你减少不少痛苦.接下来我们开发一些PyComman ...
- (5)top k大的数目
一.问题 在一个很长的数组中,求出top k大小的数目 二.办法 用优先队列 时间复杂度O(nlog(k)),应该是最差的情况下是这个 三.Code package algorithm; import ...