Solr7.4的学习与使用
学习的原因:
17年的时候有学习使用过lucene和solr,但是后来也遗忘了,最近公司有个项目需要使用到全文检索,正好也顺便跟着学习一下,使用的版本是Solr7.4的,下载地址:http://archive.apache.org/dist/lucene/solr/7.4.0/
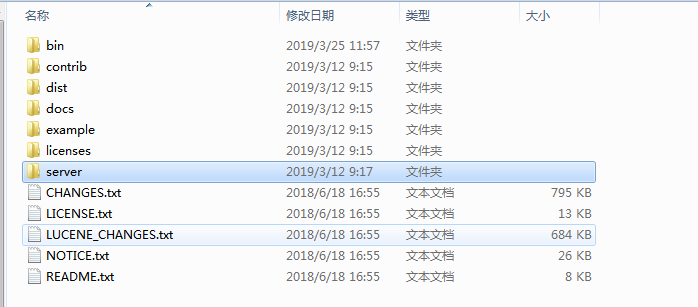
solr解压之后的目录结构:
各文件夹里面的内容: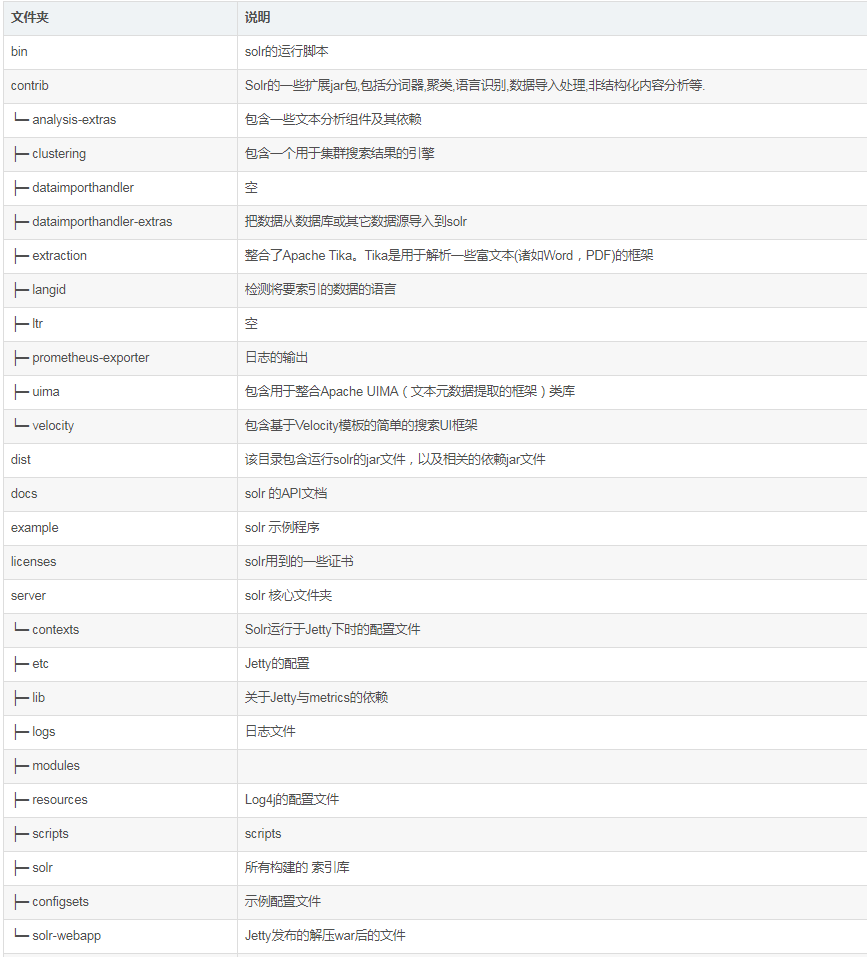
solr从5版本之后不再需要tomcat,使用内置的jetty启动。
下面开始正式开始学习使用Solr:
1、启动solr
因为现在solr使用的内置服务器,我们只需要通过命令启动就可以了。切换到bin目录。
shift+右键 ,出现黑窗口,输入solr start
,出现黑窗口,输入solr start


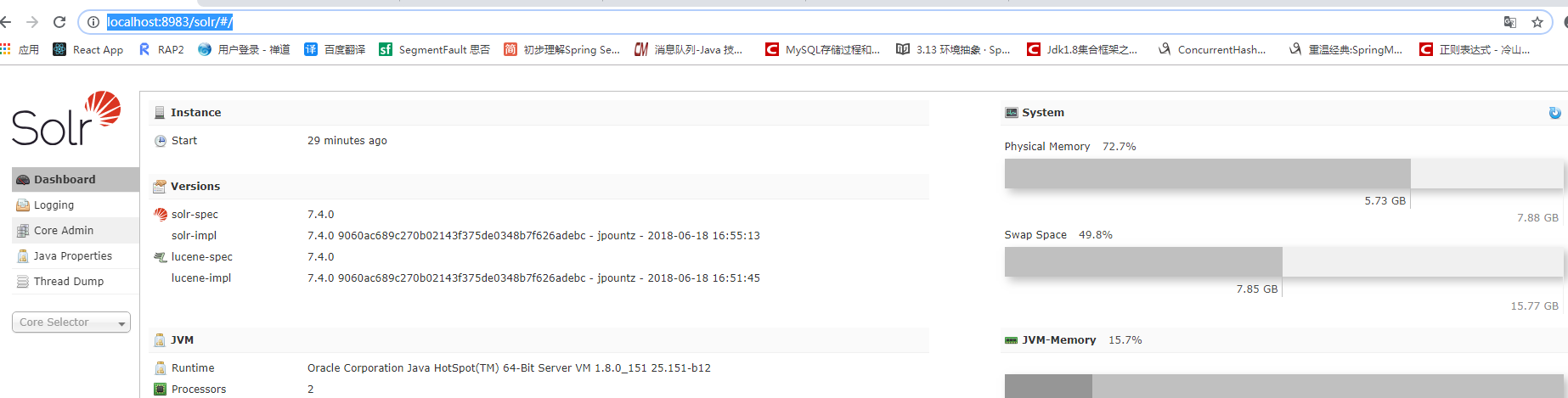
出现截图这样的就是启动成功了,中间有日志报错不用管他。访问:http://localhost:8983/solr/#/,就可以看到solrAdmin页面了
2、配置Solr核心(可以理解为solr的数据库)
配置core有两种方式一种是官方推荐的,一种是在admin页面创建
(1)通过Core Admin创建
。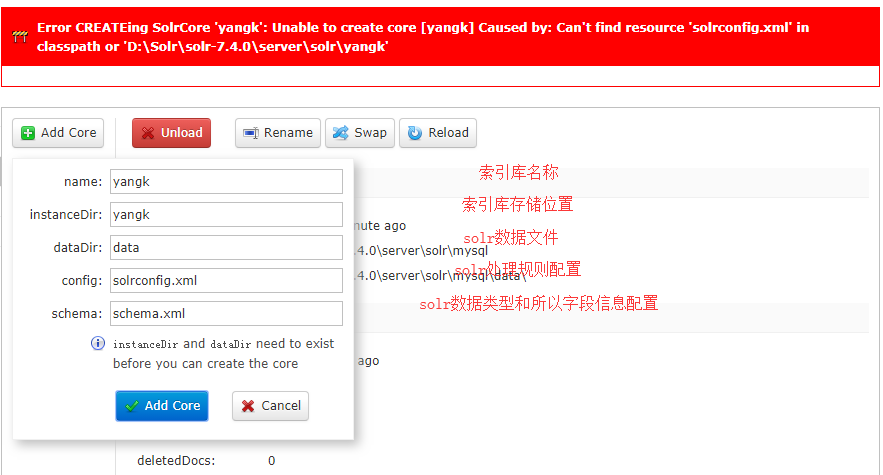
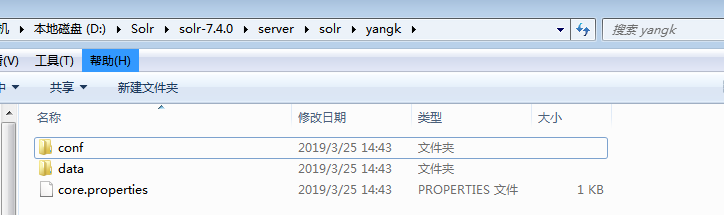
这样创建会报错。可以看到错误提示 无法找打solrconfig.xml文件。这里注意下:创建的instanceDir和dataDir 需存在,就是我们需在solr-7.4.0\server\solr 目录下先去创建目录
此目录下的conf文件我们可从server\solr\configsets\sample_techproducts_configs中复制
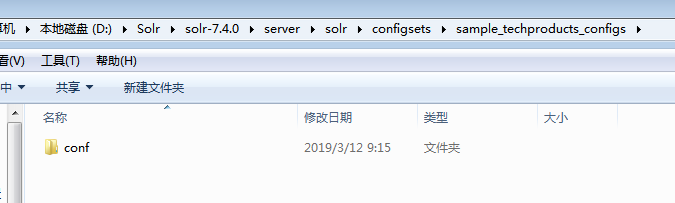
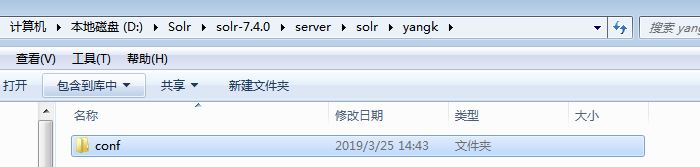
这样再去新增就可以了
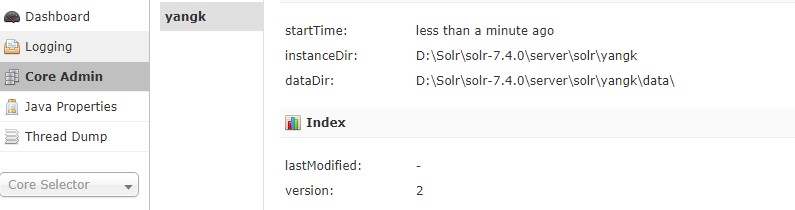
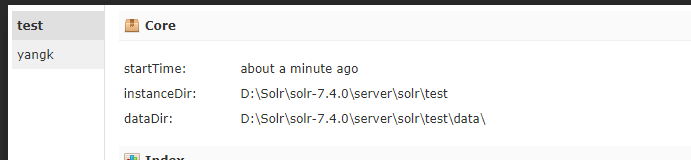
(2)官方推荐
使用命令 solr create -c test

3、配置IK分词器
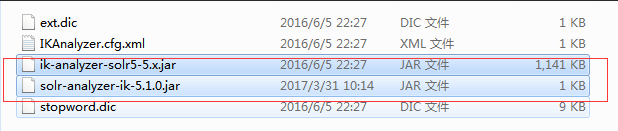
将标记的jar复制到\server\solr-webapp\webapp\WEB-INF\lib
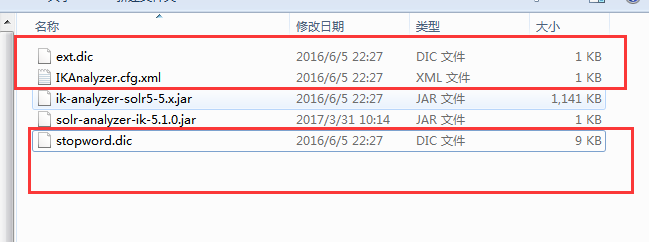
然后在server\solr-webapp\webapp\WEB-INF文件夹下面创建一个classes文件夹将上面标记的复制进去
找到刚刚创建的Core(yangk)下面的conf打开managed-schema添加如下代码:
<fieldType name="yangk_ik" class="solr.TextField">
<analyzer type="index" useSmart="false"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true"
class="org.wltea.analyzer.lucene.IKAnalyzer" /></fieldType>
在这里我们发现并没有schema.xml。这是因为Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml确找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema
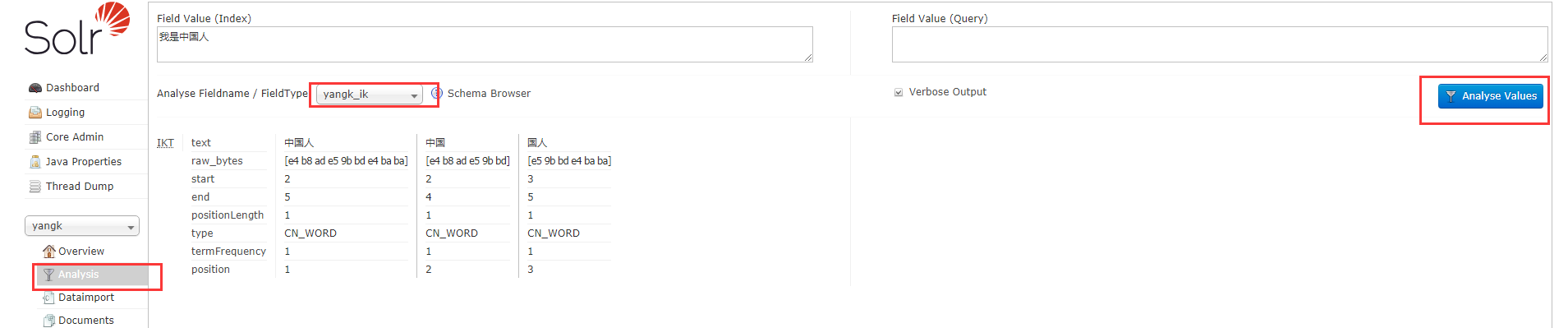
这里想要看到配置的分词器,需要重启下solr 命令:solr restart –p 端口号 重启solr服务
4、Solr整合Mysql
整合Mysql肯定需要Mysql的包,这里使用的是8.0的,将mysql的包放到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib下面

然后到solr-7.4.0\dist文件下下面找到

将这两个包也放到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib下面
为了区分,我从新创建一个croe取名mysql,然后找到solr-7.4.0\example\example-DIH\solr\db文件夹

将solr-7.4.0\example\example-DIH\solr\db文件里面的内容复制到mysql文件夹里面
进入conf里面找到db-data-config.xml修改配置文件,改为自己的数据库信息
<dataConfig>
<dataSource driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://localhost:3306/springboot?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC" user="root" password="root" />
<document>
<entity name="item" query="select id,name from sys_area">
<field column="id" name="id" />
<field column="name" name="name" />
</entity>
</document>
</dataConfig>
DataSource:数据库连接信息 Entity:对应数据库的数据表 Field:数据库字段,对应于solr的schema.xml中的 field 字段。其中 column 表示数据库字段名,name 表示 field 的 name。
然后在找到solrconfig.xml配置requestHandler

然后找到managed-schema,配置分词器和索引字段

注意:field节点对应db-data-import.xml中的field节点 其中他们的name属性保持一致。如果查询想使用Ik的话,可以把type属性设置为mysql_ik类型。但是因为managed-schema已经存在了id和name的field,所以我配置的时候报错了。如果managed-schema已有的就不需要配置了。只要配置没有的字段就行了。
这个时候配置成功了就可以导入索引
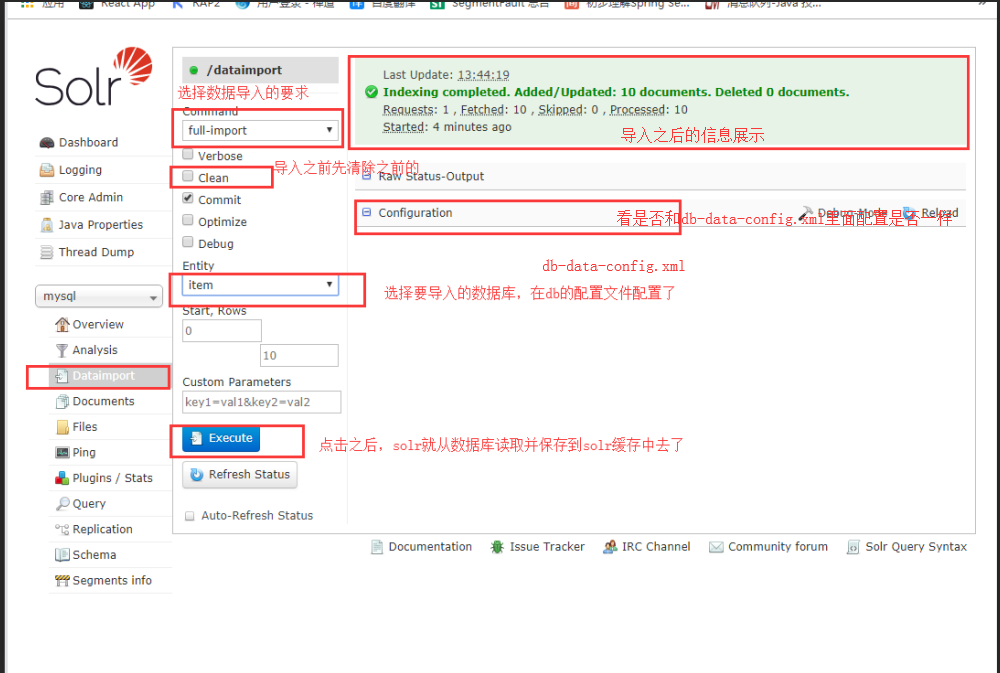
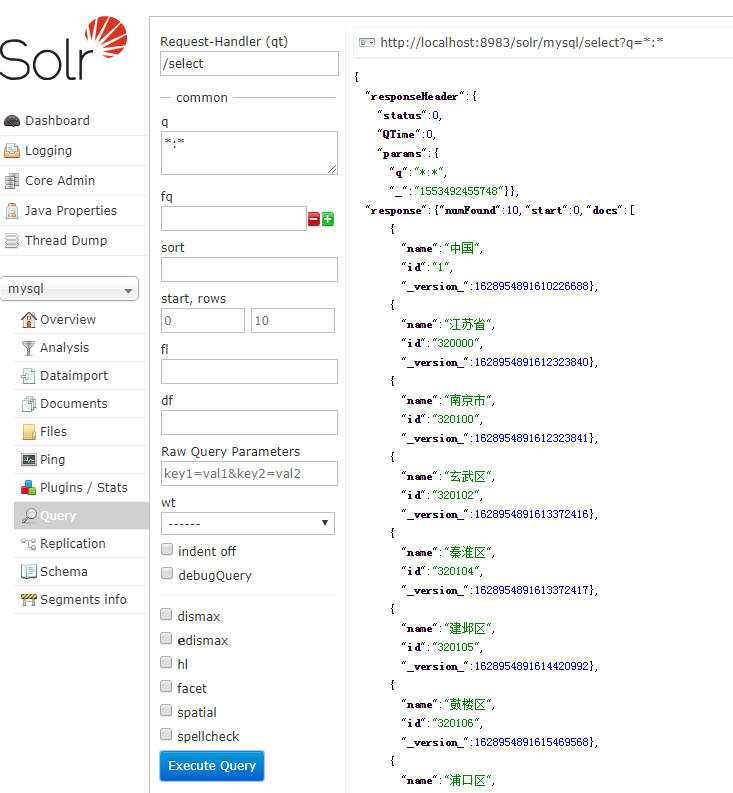
这个时候索引库就导入成功
5、使用solrj
maven配置solrj的包
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
</dependency>
java代码
public class SolrjDrmo {
// 这个是solr索引库的连接地址
private static final String URL = "http://localhost:8983/solr/mysql";
public static void main(String[] args) throws SolrServerException, IOException {
// 创建solr客户端连接
HttpSolrClient hsc = new HttpSolrClient.Builder(URL).build();
// 创建查询对象
SolrQuery query = new SolrQuery();
query.setQuery("*:*");// 设置查询全部数据的条件
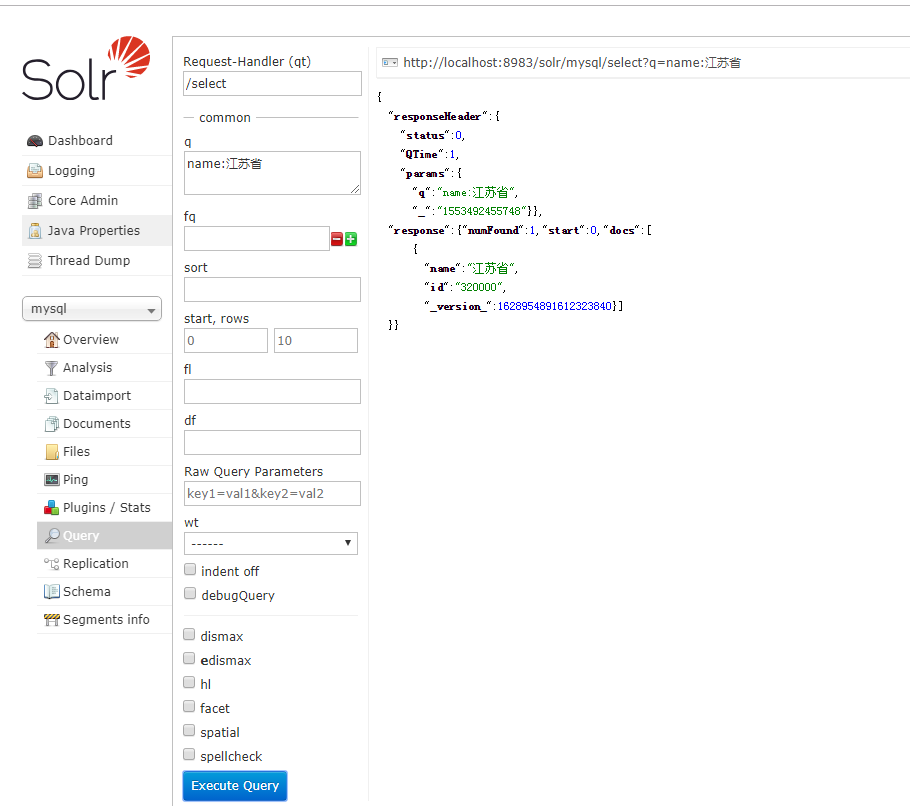
/* query.setQuery("name:江苏省"); */ // 列名:值
List<Map<String, Object>> list = getSolrQuery(hsc, query);
if (list == null) {
System.out.println("没有数据");
return ;
}
for (Map<String, Object> map : list) {
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
Object value = map.get(key);
System.out.println(key + "," + value);
}
System.out.println(" ");
}
}
public static List<Map<String, Object>> getSolrQuery(HttpSolrClient client, SolrQuery query)
throws SolrServerException, IOException {
List<Map<String, Object>> list = null;
// 执行查询并返回结果
QueryResponse resp = client.query(query);
SolrDocumentList results = resp.getResults();
// 获取查询到的数据总量
long numFound = results.getNumFound();
// 判断总量是否大于0,
) {
// 如果小于0,表示未查询到任何数据,返回null
return null;
} else {
// 如果大于0,表示有数据
// 创建list存储每条数据
list = new ArrayList<>();
// 遍历结果集
for (SolrDocument doc : results) {
// 得到每条数据的map集合
Map<String, Object> map = doc.getFieldValueMap();
// 添加到list
list.add(map);
}
// 返回list集合
return list;
}
}
}
IK分词器的下载地址:https://files.cnblogs.com/files/yangk1996/ikanalyzer-solr6.5.zip
至此一个简单的SolrDemo就搭建成功,如果中间有错误的地方,欢迎指正
Solr7.4的学习与使用的更多相关文章
- solr7.1.0学习笔记(10)---Solr发布到Tomcat
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/weixin_39082031/article/details/79069554 将solr作为一个单 ...
- JavaEE进阶——全文检索之Solr7.4服务器
I. Solr Solr简介 Solr是Apache的顶级开源项目,使用java开发 ,基于Lucene的全文检索服务器. Solr比Lucene提供了更多的查询语句,而且它可扩展.可配置,同时它对L ...
- solr学习篇(三) solr7.4 连接MySQL数据库
目录 导入相关jar包 配置连接信息 将数据库导入到solr中 验证是否成功 创建一个Core,创建Core的方法之前已经很详细的讲解过了,如果还是不清楚请参考 solr7.4 安装配置篇: 1.导入 ...
- solr学习篇(一) solr7.4 安装配置篇
目录: solr简介 solr安装 创建core 1.solr简介 solr是企业级应用的全文检索项目,它是基于Apache Lucence搜索引擎开发出来的用于搜索的应用工程 运行环境:solr需要 ...
- Solr7.x学习(4)-导入数据
导入配置可参考官网:http://lucene.apache.org/solr/guide,http://lucene.apache.org/solr/guide/7_7/ 1.数据准备(MySQL8 ...
- Solr7.x学习(3)-创建core并使用分词器
1.创建core文件夹 ck /usr/local/solr-7.7.2/server/solr mkdir first_core cp -r configsets/_default/* first_ ...
- Solr7.x学习(2)-设置开机启动
1.创建solr用户 useradd solr 2.设置solr-7.7.2目录拥有者 cd /usr/local/ chown -R solr:solr solr-7.7.2 3.在/etc/ini ...
- Solr7.x学习(1)-安装
1.下载solr-7.7.2.tgz和jdk-8u221-linux-x64.tar.gz 2.将文件解压到/usr/local目录 cd /usr/local/ tar -zxvf jdk-8u22 ...
- Solr7.x学习(8)-使用spring-data-solr
1.maven配置 <dependency> <groupId>org.springframework.data</groupId> <artifactId& ...
随机推荐
- nSum “已知target再求和”类型题目总结:n-2重循环+left/right
Sum类的题目一般这样: input: nums[], target output: satisfied arrays/ lists/ number 拿到题目,首先分析: 1. 是几个数的sum 2. ...
- Linux mmap函数简介
一.简介 Linux提供了内存映射函数mmap, 它把文件内容映射到一段内存上(准确说是虚拟内存上), 通过对这段内存的读取和修改, 实现对文件的读取和修改, 先来看一下mmap的函数声明: 头文件: ...
- [C#] Delegate, Multicase delegate, Event
声明:这篇博客翻译自:https://www.codeproject.com/Articles/1061085/Delegates-Multicast-delegates-and-Events-in- ...
- viewDidAppear在何时调用?
[viewDidAppear在何时调用] If the view belonging to a view controller is added to a view hierarchy directl ...
- Oracle学习笔记(十二)
十三.存储过程和存储函数1.掌握存储过程(相当于建立一个函数或者方法体,然后通过外部对其调用) 指存储在数据库中供所有程序调用的子程序叫做存储过程或存储函数. 相同点: 完成特定功能的程序 区别: 是 ...
- gcc支持的一种结构体赋值方式
struct info{ int a; char b; struct fd{ int c; int d; }fg;}; 其实我们也可以这样赋值:同样对于其他的类型也是一样 ...
- VS中的Debug 和 Release 编译方式的本质区别
VS中的Debug 和 Release 编译方式的本质区别 Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序.Release 称为发布版本,它往往是进行了各种优化,使 ...
- scala中Nil用法
http://www.runoob.com/scala/scala-lists.html 即Nil是空List 双冒号是追加进入 package com.yjsj.spark object scala ...
- asp.net部署时加密config文件
1:运行cmd,并定位到C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727(可以直接运行vs2005的命令提示工具,但是貌似vs2010默认指向的framewo ...
- 开源WebGIS实施方案(五):基于SLD实现图层符号化及其应用
SLD概述 SLD(OpenGIS® Styled Layer Descriptor):图层样式注记.其当前版本是1.1.0.SLD是一种描述地图图层样式的标准,一般用于WMS中的图层符号化. 说白了 ...