Python运维开发基础08-文件基础
一,文件的其他打开模式
"+"表示可以同时读写某个文件:
- r+,可读写文件(可读;可写;可追加)
- w+,写读(不常用)
- a+,同a(不常用
"U"表示在读取时,可以将\r\n自动转换成\n(与r或r+模式同使用)
- rU(不常用)
- r+U(不常用)
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,Linux可忽略,windows处理二进制文件时需标注)
- rb
- wb(不常用)
- ab(不常用)
1.1 文件的读写模式(r+)
创建文件模板
[root@localhost scripts]# cat yun
1111
sdass
sdfsdf
12345678901234567890
111
代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
f = open("yun","r+",encoding="utf-8")
print(f.tell())
f.readline()
print(f.tell())
f.write("你好吗?\n")
f.close()
#输出结果
0 #指针确实在0位置
5 #读了一行后,指针后移5位
#文件内容
[root@localhost scripts]# cat yun
1111
sdass
sdfsdf
12345678901234567890
111
你好吗? #文件追加到了最后一行
- 通过写读模式,我们发现读取的指针的确是从0位置开始的,读了一行后,指针也的确按字符后移了固定位。但是当我们写入数据的时候,数据却出现在了最后一行。
- 是的,r+这种模式就是如此。你可以按顺序读,但是进行写入操作时,就只是追加在最后一行的追加模式了。
追加到文件中的数据能被读出来吗?
#代码演示:
f = open("yun","r+",encoding="utf-8")
f.write("你好吗?\n")
for line in f :
print (line.strip())
f.close()
#输出结果
1111
sdass
sdfsdf
12345678901234567890
111
通过上述演示,我们发现追加到文件中的数据并没有被读出来。因此r+这种读写模式,读和写也是分开的。写入的操作是一种追加到文件末尾的追加写入。
1.2 文件的写读模式(w+)
#代码演示
f = open("yun","w+",encoding="utf-8")
print (f.tell())
print (f.readline().strip())
print (f.tell())
f.close()
#输出结果
没有任何输出
#文件内容
0
0
我们发现我们用w+模式没有读取到任何内容,指针也没有移动。而且源文件也被清空了。那我们写入数据呢?
#代码演示:
f = open("yun","w+",encoding="utf-8")
print (f.tell())
print (f.readline().strip())
print (f.tell())
f.write("你好吗\n")
f.write("你好吗\n")
f.write("你好吗\n")
f.close()
#输出结果
0
0
#文件内容
空空如也
[root@localhost scripts]# cat yun
你好吗 #源文件内容没了
你好吗
你好吗
我们发现w+的写读模式,源文件仍旧被清空了。所以读不出来任何东西。那么已经写入东西能被再次读出来吗?
#代码演示:
f = open("yun","w+",encoding="utf-8")
print (f.tell())
print (f.readline().strip())
print (f.tell())
f.write("你好吗\n")
f.write("你好吗\n")
f.write("你好吗\n")
print (f.tell())
print (f.readline())
print (f.tell())
print (f.read())
print (f.tell())
f.close()
#输出结果
0 #初始指针位置
0 #读取操作,指针位置不变
30 #写入以后,指针位置变了
30 #读取不出来任何东西,指针位置不变
30
1.3 追加读模式(a+)
这种模式和a模式完全一样
1.4 二进制读模式(rb)
这种模式是将数据以二进制的格式读取到内存中在输出到屏幕上。
#代码演示
f = open("yun","rb")
print (f.readline().strip())
print (f.readline().strip())
f.close()
#输出结果
b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x90\x97\xef\xbc\x9f'
b'sdfsdf'
- 这里需要特别注意的是,在打开文件时,不能再定义encoding="utf-8",这个和rb模式冲突。encoding的意思是将文件内容转码成utf-8格式。如果不写,会遵照代码默认方式转码。如果代码没有默认的,在linux下默认用utf-8进行转码,在windows上默认ASCII码。rb这个模式是默认用二进制格式转换读取文件。
- 在网络编程里,比如FTP服务器端和客户端发送数据,Python3.0强制在发送数据时必须是二进制格式。因此在网络编程中,我们会常用这种数据格式。
知识扩展:
Windows的那些启动文件或者快捷方式.exe都是二进制格式的文件,我们想要读取它的内容,就必须用二进制格式(rb)。
二,文件内容的修改技巧
创建文件模板:
[root@localhost scripts]# cat yun
《奋斗自白》
1,自报家门
2,上次考试失利原因
3,下次考试要如何准备
4,奋斗自白
5,自白收尾
《作弊自白》
1,自报家门
2,上次做了啥事
3,为何要做
4,导致后果
5,以后如何做
6,自白收尾
《圆梦自白》
1,自报家门
2,之前的努力宣言内容
3,达成之后的喜悦
4,以后要如何更加努力
5,自白收尾
现在我们想要文件里的所有“自白收尾”内容,改成“Mr.chen”
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
f = open("yun","r",encoding="utf-8")
f_new = open("yun.bak","w",encoding="utf-8")
for line in f :
if "自白收尾" in line :
line = line.replace("自白收尾","Mr.chen",-1)
f_new.write(line)
f.close()
f_new.close()
os.system("/bin/mv yun.bak yun")
执行后的文件内容:
[root@localhost scripts]# cat yun
《奋斗自白》
1,自报家门
2,上次考试失利原因
3,下次考试要如何准备
4,奋斗自白
5,Mr.chen
《作弊自白》
1,自报家门
2,上次做了啥事
3,为何要做
4,导致后果
5,以后如何做
6,Mr.chen
《圆梦自白》
1,自报家门
2,之前的努力宣言内容
3,达成之后的喜悦
4,以后要如何更加努力
5,Mr.chen
三,文件读写管理器(with)
我们每次再打开一个文件的时候,系统都会有一个进程在占用着文件。如果我们忘记f.close(),那么其他进程就无法再打开这个文件了,直到程序结束为止。那么有没有一种方法在我们用完了文件后,自动帮我们关闭文件呢?有的,这就是文件读写管理器(with)。
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
with open("yun","r",encoding="utf-8") as f :
for line in f :
print (line)
这种文件读写管理器,当你对文件操作的代码执行完毕后,会自动关闭文件释放资源。这样我们就不会忘记了。当然,这种方式也存在问题,这个等我们以后遇到了再说。
利用文件管理器同时打开两个文件实现文件的读和写
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
with open("yun","r") as f ,open("yun.bak","w") as f_new :
for line in f :
if "Mr.chen" in line :
line = line.replace("Mr.chen","自白收尾",-1)
f_new.write(line)
四,字符转编码操作
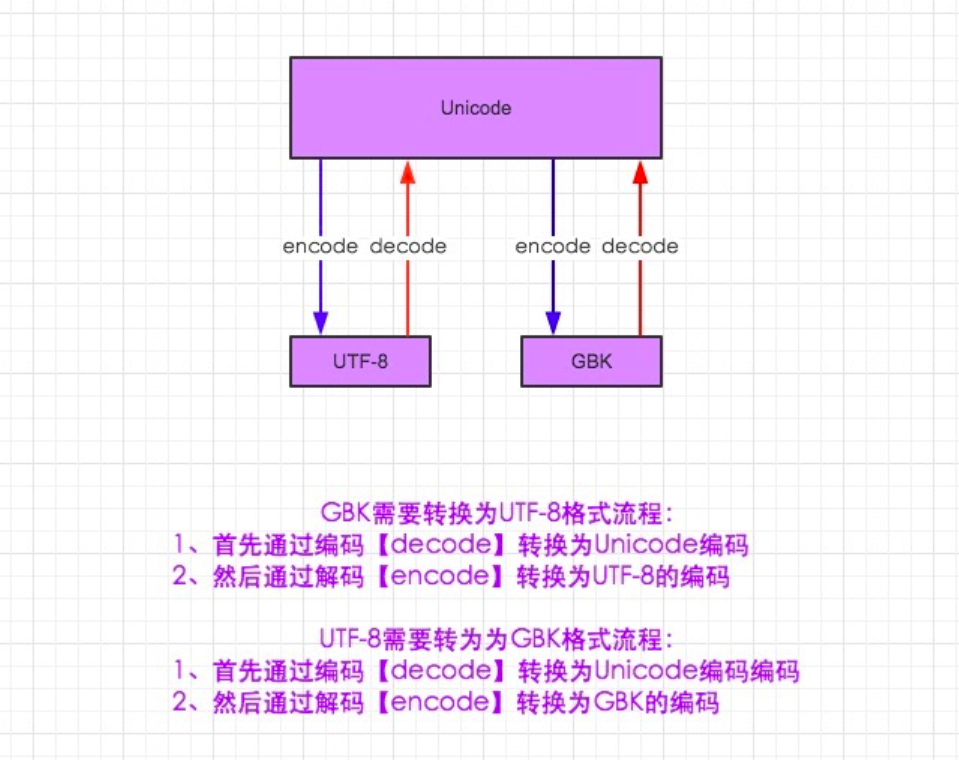
4.1 Python2.7中的字符转码规则
- 我们在用Python27时之所以要在最上面写
-*- coding:utf-8 -*-,最主要的原因是,支持中文的编码是utf-8格式的,它是Unicode中的一个子集。因此,其实Unicode本身也是支持中文的。utf-8只是占3个字节位的意思,也就是说一个中文字占3字节(2**3次方)。- 假如我们在Python27中不写上
-*- coding:utf-8 -*-句话,那么运行起来,中文就会出现错误。
#操作演示Python27
name = "你好吗?" #去掉-*- coding:utf-8 -*-句话
print (name)
#运行结果
[root@localhost scripts]# python -V
Python 2.7.13
[root@localhost scripts]# python test2.py
File "test2.py", line 4
SyntaxError: Non-ASCII character '\xe4' in file test2.py on line 4, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
报错显示ACCII字符格式存不下这个中文。这是因为,如果你在文本中标注utf-8格式进行转码的话,Python27默认使用ASCII码来进行转码。
#代码演示
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:Mr.chen
import sys
print (sys.getdefaultencoding()) #查看Python27默认的转码格式
#输出结果
[root@localhost scripts]# python test.py
ascii
假如:我们想将数据转码成gbk2312的格式,从而可以在windows上识别,那么我们需要如下方式进行转码。
#代码演示:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:Mr.chen
import sys
print (sys.getdefaultencoding()) #打印默认字符集
name = "你好吗?" #因为台头写了utf-8转码,因此这个数据是utf-8格式的,某则就会是ascII格式,但是不能存中文,因此会报错
print (name) #输出utf-8格式的中文
name_gbk = name.encode("gbk") #将utf-8格式转码成gbk格式
print (name_gbk) #输出gbk格式数据
#运行结果
[root@localhost scripts]# python test.py
ascii #默认字符集
你好吗? #utf-8格式中文,因为xshell设置了utf-8解码所以能够识别
Traceback (most recent call last): #报错了,这是为什么
File "test.py", line 11, in <module>
name_gbk = name.encode("gbk")
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
上面的测试,再次报错了。这是为什么呢?由上面给同学们看的图,可知从utf-8数据要想转换到gbk数据,那是需要先解码成Unicode数据格式的。也就是说先解码(decode),再转码才行(encode)。可是我们没有指定解码的格式,因此Python27会用默认解码方式,也就是解码ASCII<===>decode("ASCII"),而那个str是个utf-8格式编码数据,因此再次报错。
#代码演示:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:Mr.chen
import sys
print (sys.getdefaultencoding())
name = "你好吗?"
print (name)
name_unicode = name.decode("utf-8")
print (name_unicode)
name_gbk = name_unicode.encode("gbk")
print (name_gbk)
#输出结果
[root@localhost scripts]# python test.py
ascii #默认字符集编码
你好吗? #utf-8格式中文
你好吗? #unicode个是中文
ţºĂ #gbk格式中文,是个乱码
从测试可知,utf-8和unicode字符集其实都支持中文。再xshell的字符集设置上由于我们设置的utf-8所以就都能够识别。再次说明utf-8字符集只是unicode的一个子集。unicode是一个通用型编码格式。而gbk字符集,我们就无法正常显示。现在我们调一下xshell的字符集类型,调整成gbk格式。
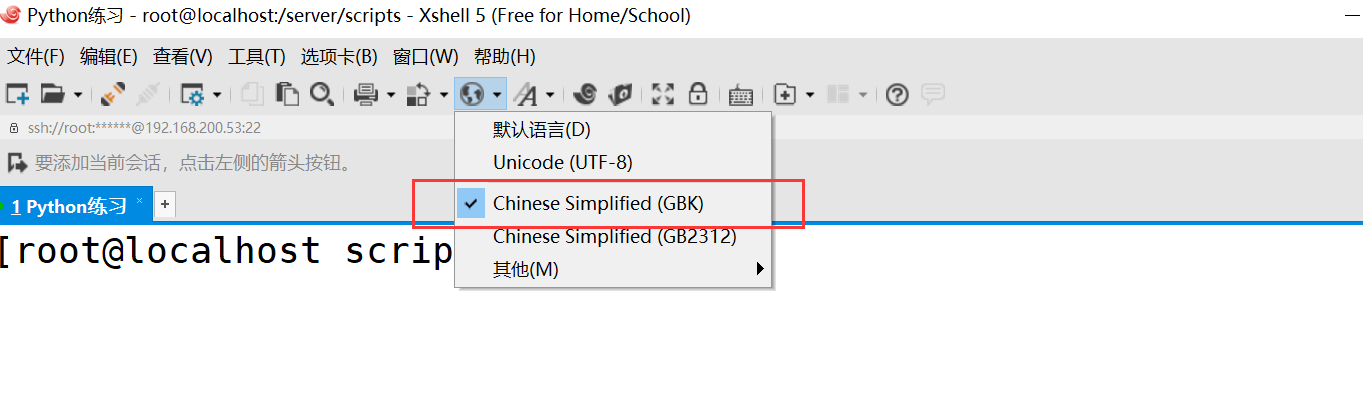
然后我再次重新运行那段Python27程序
#输出结果显示
[root@localhost scripts]# python test.py
ascii
浣犲ソ鍚楋紵 #utf-8乱码了
浣犲ソ鍚楋紵 #unicode乱码了
你好吗? #gbk格式正常显示了
通过测试可知。在Python27中utf-8要想转换成其他格式数据都需要先对utf-8进行解码从而得到unicode编码(通用型编码),然后再转码到其他字符集。如果我们的中文想要在日本的机器上正常显示中文的话,就需要先将utf-8解码得到unicode编码然后再转码成日本的字符集格式。
4.2 在Python3.X中的字符转码规则。
在Python3.0开始,再不需要为乱码的事情发愁。也就是说Python3.0再无乱码。所有转码都会被默认转换成bytes数据类型,而不是str
在Python3.x中的默认字符集为utf-8
#代码演示:
import sys
print (sys.getdefaultencoding())
#输出结果
[root@localhost scripts]# python3 test.py
utf-8
在Python3.x中的转码默认转换成字节类型bytes
#代码演示
#!/usr/bin/env python3
# author:Mr.chen
import sys
print (sys.getdefaultencoding()) #输出默认字符集
name = "你好吗?" #台头没声明,默认是utf-8类型编码
print (name)
name_gbk = name.encode("gbk") #没有输入decode,默认decode("utf-8")
print (name_gbk) #输出gbk编码的字符集
#输出结果
[root@localhost scripts]# python3 test.py
utf-8
你好吗?
b'\xc4\xe3\xba\xc3\xc2\xf0\xa3\xbf' #Python3转码默认转换成bytes类型的数据而不是str类型。
为了方便验证Python3.X是否已经转码了,我们继续试验
#代码演示:
#!/usr/bin/env python3
# author:Mr.chen
import sys
print (sys.getdefaultencoding()) #输出默认字符集
name = "你好吗?" #默认编译成utf-8格式字符串
print (name) #输出utf-8格式字符椽
print (bytes(name,encoding="utf-8")) #将utf-8格式字符串类型转换成bytes类型并输出
name_gbk = name.encode("gbk") #将utf-8格式字符串类型数据转换成gbk格式bytes类型数据
print (type(name_gbk)) #输出查看转码后的数据类型
print (name_gbk) #输出转码后的gbk格式,bytes类型数据
print (str(name_gbk,encoding="gbk")) #将bytes类型数据转换成str类型数据并输出。
#输出结果
utf-8 #默认字符集
你好吗?
b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x90\x97\xef\xbc\x9f' #utf-8格式bytes类型
<class 'bytes'>
b'\xc4\xe3\xba\xc3\xc2\xf0\xa3\xbf' #gbk格式bytes类型
你好吗?
通过上述实验,我们发现Python3.X里的转码由于都转成了默认bytes类型的数据,而在进行字符串转换时,又必须指明数据的编码格式,因此在输出时不会再出现乱码。
五,作业
程序:
实现简单的shell命令sed的替换功能
最低要求:
- 能够正确识别类似
sed -i '条件' 文件名的格式,并排除可能的错误 - 能够正确别条件为类似
s#旧内容#新内容#g的格式,并排除可能的错误 - 能够正确识别有g和无g的模式,并排除可能的错误
进阶实现:
1.能够识别限定行的替换功能类似1,3s#旧内容#新内容#g,并排除可能的错误。
Python运维开发基础08-文件基础的更多相关文章
- python运维开发(二十一)----文件上传和验证码+session
内容目录: 文件上传 验证码+session 文件和图片的上传功能 HTML Form表单提交,实例展示 views 代码 HTML ajax提交 原生ajax提交,XMLHttpRequest方式上 ...
- Python运维开发基础09-函数基础【转】
上节作业回顾 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 实现简单的shell命令sed的替换功能 import ...
- Python运维开发基础08-文件基础【转】
一,文件的其他打开模式 "+"表示可以同时读写某个文件: r+,可读写文件(可读:可写:可追加) w+,写读(不常用) a+,同a(不常用 "U"表示在读取时, ...
- Python运维开发基础07-文件基础【转】
一,文件的基础操作 对文件操作的流程 [x] :打开文件,得到文件句柄并赋值给一个变量 [x] :通过句柄对文件进行操作 [x] :关闭文件 创建初始操作模板文件 [root@localhost sc ...
- Python运维开发基础06-语法基础【转】
上节作业回顾 (讲解+温习120分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 添加商家入口和用户入口并实现物 ...
- Python运维开发基础03-语法基础 【转】
上节作业回顾(讲解+温习60分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen #只用变量和字符串+循环实现“用户登陆 ...
- Python运维开发基础02-语法基础【转】
上节作业回顾(讲解+温习60分钟) #!/bin/bash #user login User="yunjisuan" Passwd="666666" User2 ...
- Python运维开发基础01-语法基础【转】
开篇导语 整个Python运维开发教学采用的是最新的3.5.2版,当遇到2.x和3.x版本的不同点时,会采取演示的方式,让同学们了解. 教学预计分为四大部分,Python开发基础,Python开发进阶 ...
- Python运维开发基础01-语法基础
标签(空格分隔): Mr.chen之Python3.0执教笔记(QQ:215379068) --仅供北大青鸟内部学习交流使用 开发不是看出来的,开发一定是练出来的: 想学好开发,没有捷径可走,只有不断 ...
- Python运维开发基础10-函数基础【转】
一,函数的非固定参数 1.1 默认参数 在定义形参的时候,提前给形参赋一个固定的值. #代码演示: def test(x,y=2): #形参里有一个默认参数 print (x) print (y) t ...
随机推荐
- UVALive 5903 Piece it together 二分匹配,拆点 难度:1
https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_probl ...
- bzoj1449&&bzoj2895
题解: S连每场比赛流量1费用0 每场比赛连参赛队流量1费用0 我们发现调整一次 由win,lose变为 win+1,lose-1的费用为 (C*(win+1)^2+D*(lose-1)^2) - ( ...
- Halcon12新特性之VS可视化调试插件
当我们用VC\C#调试halcon代码的时候,通常会遇到一个头痛的问题,我们无法看到halcon变量的调试信息 如下图:什么鬼...什么鬼 比如我们想看一个double数值变量,我们需要 doub ...
- maven编译报错 -source 1.5 中不支持 lambda 表达式(转)
原文链接:http://blog.csdn.net/kai161/article/details/50379418 在用maven编译项目是由于项目中用了jdk 1.8, 编译是报错 -source ...
- 简单使用dom4j
package com.dom4j; import java.io.FileWriter; import java.io.IOException; import java.io.Unsupported ...
- STL标准库-容器-vector
技术在于交流.沟通,本文为博主原创文章转载请注明出处并保持作品的完整性. 向量容器vector是一个动态数组,内存连续,它是动态分配内存,且每次扩张的原来的二倍. 他的结构如下 一 定义 vector ...
- Memcached工作原理及常见问题
memcached是怎么工作的? Memcached的神奇来自两阶段哈希(two-stage hash).Memcached就像一个巨大的.存储了很多<key,value>对的哈希表.通过 ...
- VMware 虚拟机快照、克隆、磁盘扩容
1. 快照 快照是虚拟机某个时间点上完整系统的镜像,可以在虚拟机内部通过快照文件恢复系统到之前的节点. 拍摄快照: 恢复快照: 2. 克隆 克隆是原始虚拟机全部状态的一个拷贝,是脱离原始虚拟机独立存在 ...
- Python 高性能并行计算之 mpi4py
MPI 和 MPI4PY 的搭建上一篇文章已经介绍,这里面介绍一些基本用法. mpi4py 的 helloworld from mpi4py import MPI print(&quo ...
- Git 学习记录一
主要来源参考http://www.runoob.com/git/git-install-setup.html Windows 平台上安装 在 Windows 平台上安装 Git 同样轻松,有个叫做 m ...