c++builder 字节 编码 转换大全 String TBytes byte
System.SysUtils
System::DynamicArray<System::WideChar> TCharArray
System::TArray__1<System::WideChar> TCharArray;
TCharArray
String TBytes byte
编码类型有:ASCII、8BIT、7BIT、UCS2-BIG、UCS2-LIT、UCS2-80、UCS2-81、UCS2-82、UTF-8、UTF-16(Unicode)
RawToBytes
BytesToRaw
Byte一个字节,能存放0..255,就是unsigned char,小写的byte等价于大写的Byte。
array
TByteDynArray= array of Byte;
TIdBytes= array of Byte;
typedef System::DynamicArray<System::Byte> TIdBytes;
typedef System::DynamicArray<System::Byte> TBytes;
动态数组的写法
DynamicArray<Byte> TBytes;
DynamicArray<int> TInts;
TBytes = TArray<Byte>;
String> TBytes/TByteDynArray
Text.BytesOf()
BytesOf
WideBytesOf()
TBytes bv;
bv.set_length(8);
bytes=System::Sysutils::BytesOf(Caption);
bytes=System::Sysutils::WideBytesOf(Caption);//value is spec wide
bytes=Caption.BytesOf();
TBytes/TByteDynArray > String
Caption = System::Sysutils::StringOf(barr);
Caption = System::Sysutils::WideStringOf(barr);
String > <Utf8Bytes
TBytes bytes;
bytes = TEncoding::UTF8->GetBytes(Memo1->Text);
Memo1->Text = TEncoding::UTF8->GetString(bytes);
delphi
TEncoding.UTF8.GetBytes
TBytes/TByteDynArray > Byte *
TBytes bytes;
Byte * bt = &bytes[0];
byte bb[255];
或者
bt = new Byte[bytes.Length];
memcpy(bt,&bytes[0],bytes.Length);
TBytes初始化memset
TBytes bv;
bv.set_length(5000);
memset( &bv[0], 0,bv.Length );
Byte * >TBytes/TByteDynArray
Byte * bt;
TBytes bytes;
bytes = BytesOf(bt, sizeof(bt));
UnicodeString s1;
s1 = "Hello World!";
s1.Length(), ByteLength(s1)
ByteLength
TIdBytes
TIdBytes = array of Byte;
TBytes = TArray<Byte>;
uses IdGlobal;//head file
TIdBytes>String
String str=BytesToString( AValue: TIdBytes);
TIdBytes>TBytes
BytesToRaw(Buffer,abuffer,Length(Buffer));
SetLength(bs,0);
SetLength(bs,Length(idbs));
BytesToRaw(idbs,bs,Length(idbs));//error
BytesToRaw(idbs,bs[0],Length(idbs));//ok
buf :=TBytes( idbus);//ok
TBytes>TIdBytes
function RawToBytes(const AValue; const ASize: Integer): TIdBytes;
idbs := RawToBytes(bs[0], Length(bs));//必须加下标0,否则就是错是
idbs := RawToBytes(bs, Length(bs));//没有下标0是错的
结构体>TIdBytes
RawToBytes(SendData,SizeOf(SendData));//SendData是结构体变量,不要下标0
UTF8String Bytes>UnicodeString
字节转换为16进制
idbytes to hexString
String hexstr;
for (int i = idbytes.Low; i <= idbytes.High; i++)
{
hexstr += IntToHex(idbytes[i], );
}
delphi
PAnsiChar数组转为字符串
R: array[0..19] of AnsiChar;
sss:ansistring;
astr := AnsiString(r);
StrPCopy(r,astr);
Delphi7升级
AnsiChar(DelphiXE10)= Char(Delpih7)
Delphi7:
Object: array[1..6] of Char;
DelphiXE10,Berlin
Object: array[1..6] of AnsiChar;
sbytes := VarArrayOf([$AA, $EE, $81, $0, $0, $0, $0, $0, $0, $0, $0, $0, $0, $0, $0, $0]);
AnsiString>Bytes>AnsiString
bsa := TEncoding.ANSI.GetBytes(as1);
as1:= TEncoding.ANSI.GetString(bsa);
假UTF8Sring转换为汉字
UTF8String s8="闫换珍";
AnsiString s8a="闫换珍";
都是6个字节,一个汉字2个字节。
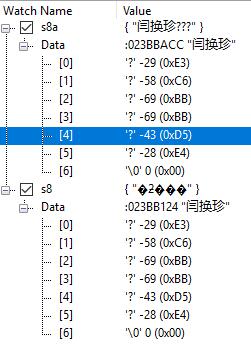
此时,想还原汉字this->Caption=???如何才能显示汉字
AnsiString as21 = s8;//err
AnsiString as22 = AnsiString(s8);//err
AnsiString as2 = s8.c_str();//ok String s991 = s8;//err
String s992 = String(s8);//err
String s99 = s8.c_str();//ok 最可靠
as1:= TEncoding.ANSI.GetString(bs8);//ok
真UTF8String
UTF8String s8=L"闫换珍";//加上L标识才是真正的UTF8,一个汉字3个字节,UnicodeString函数是2个字节。
AnsiString s8a="闫换珍";
TBytes bs81 =TEncoding::UTF8->GetBytes(s8);
TBytes bs82 =TEncoding::UTF8->GetBytes(s8a);
两个bytes里是相等的,正确的。
char dest[256] = {0}; // room for 256 characters
UnicodeString src = L"闫换珍";
UnicodeToUtf8(dest, src.c_str(), 256);
//或者 UnicodeToUtf8(dest,256, src.c_str(), src.Length*();
dest与bs81,bs82值相等。
RawByteString srbRaw;
srbRaw = UTF8Encode(ss);
//ss = UTF8Decode(srb);
char Buf[512] = {0 };
strcpy(Buf, srbRaw.c_str());
Buf这个也是正确的utf8字节
UTF8String>String
String s=s8;
UnicodeString us1 =s8;
UnicodeString us11 = UTF8ToUnicodeString(s8.c_str());
UnicodeString us13 = UTF8ToString(s8.c_str());
UnicodeString us14 = Utf8ToAnsi(s8);
RawByteString rbs1 = AnsiToUtf8(s8);
word/short/int 简单类型转换为bytes
var Buf:TBytes; w:Word;begin w:=10; Buf:=RawToBytes(w);end;var Buf:Array[0..1] of Byte; w:Word;begin w:=10; Move(w,Buf[0],2);end;
doule>Byte[]
byte bt[8];
double ad;
memcpy(&bt[0], (byte*)&ad, 8);
memcpy(&bt[0], (byte*)&ajava, sizeof(double));
#if defined(USE_ENCODING)
TBytes FirstLine; // A dynamic array of bytes
FirstLine.Length = ;
stream = _wfopen(OpenDialog1->Files->Strings[I].c_str(), L"r");
fgets(&FirstLine[], FirstLine.Length, stream);
Memo1->Lines->Append(TEncoding::UTF8->GetString(FirstLine));
fclose(stream);
#else
char FirstLine[];
stream = _wfopen(OpenDialog1->Files->Strings[I].c_str(), L"r");
fgets(FirstLine, sizeof(FirstLine), stream);
Memo1->Lines->Append(UTF8String(FirstLine));
fclose(stream);
#endif
delphi
LBuffer: TBytes;
SetLength(LBuffer, LFileStream.Size);
LFileStream.ReadBuffer(Pointer(LBuffer)^, Length(LBuffer));
C++builder VCL String
String astr="hello";
astr[0]//error,下标正确的是从1开始
StringToOleStr
字符串函数
String ss;
ss.LastDelimiter(" ");
最后一个空格出现的位置,这样就不用循环了
BSTR bs1;
fun(BSTR *name);
fun(&bs1);
Delphi Berlin 有此函数,int转换为16进制
ai:Integer;
ai:=17;
self.Caption:=ai.ToHexString;
StringList>字符数组
arr:TArray<string>;
list:TStringList;
arr := list.ToStringArray;
TStringDynArray
TMemoryStream>TBytes
LResponse: TMemoryStream;
unsigned char *>AnsiString
AnsiString str1= (char *)buff;
AnsiString str2((const char *)buff);
AnsiString>unsigned char*
strcpy(uchar,AnsiString(str).c.str());
ascii码转16进制
String Asc2Hex(String astr)
{
TBytes bytes;
bytes = TEncoding::ASCII->GetBytes(astr);
String hexstr;
for (int i = bytes.Low; i <= bytes.High; i++)
{
hexstr += IntToHex(bytes[i], );
} return hexstr;
}
String Hex2Asc(String hexStr)
{
int nLen = hexStr.Length();
int j = ;
String ahex;
char achar;
String retstr;
if ( != (nLen % ))
{
return -;
}
for (int i = ; i < nLen; i = i + , j++)
{
ahex = hexStr.SubString(i, );
ahex = "0x" + ahex;
achar = char(ahex.ToInt());
retstr = retstr + achar; }
return retstr;
}
UnicodeString>std:string
String at="abc";
std:string sstr = AnsiString(at).c_str();
字符串数组
var arr:TArray<string>;
TStringDynArray ArrayOfString2 = array of string; string2Bytes
String astr = "中国";
TBytes b1,b2,b3,b4;
b1 = TEncoding::UTF8->GetBytes(astr);
b2 = TEncoding::ANSI->GetBytes(astr);
b3 = TEncoding::Default->GetBytes(astr);
b4 = TEncoding::Unicode->GetBytes(astr);
E4B8ADE59BBD
D6D0B9FA
D6D0B9FA
2D4EFD56 高地位修正后:4E2D 56FD ,也有这样表单\u4e23 \u56fd String s1,s2,s3,s4; s1 = TEncoding::UTF8->GetString(b1);//中国
s2 = TEncoding::ANSI->GetString(b2);//中国
s3 = TEncoding::Default->GetString(b3);//中国
s4 = TEncoding::Unicode->GetString(b4);//中国 bytes数组转换成HexString
String bytesToHex(TBytes data)
{
String hexstr;
for (int i = 0; i < data.Length; i++)
hexstr+= IntToHex( data[i],2);
return hexstr;
} 特殊汉字
char=13,keypress,
包含key=13:复 包含tab
delphiAnsiChar array 转换为 tbytes
bts:tbytes;
outbuf: array[0..1000] of AnsiChar; setlength(bts,200);
Move(bts[0[, outbuf[0], 200);
https://www.cnblogs.com/del88/p/5448317.html
bytesof(str)
stringof(bytes) T
strAnsi:= PAnsiChar(AnsiString(str));
TBytes -> PChar : LPChar := PChar(LTBytes);
PChar -> TBytes:LTBytes := BytesOf(LPChar);
TBytes -> Array of AnsiChar:move(LTBytes[i],LArrayOfAnsiChar[k]);
Array of AnsiChar -> string:LString := StringOf(BytesOf(LArrayOfAnsiChar));
https://www.cnblogs.com/keynexy/p/5919962.html
c++builder 字节 编码 转换大全 String TBytes byte的更多相关文章
- 前端中常见字节编码(base64、hex、utf8)及其转换
/* * 字节编码转换 * 首先都需要转为二级制数组 (ArrayBuffer) * 然后才能转换对应的编码字符 * 前端常见编码: * base64:就是将二进制转为字符串,将每6个字节转为一个特定 ...
- java String与Byte[]和String 与InputStream转换时注意编码问题。。。
前一段日子,我在做rsa加密和通过http get方式获取验证码图片通过BitmapFactory创建bitmap 出现了一系列的问题. 通过一系列的调试,发现有些问题原来是在进行String 与By ...
- String和bytes的编码转换
import java.io.UnsupportedEncodingException; import java.nio.charset.Charset; /** * @author 作者 E-mai ...
- java String编码转换
/** * Get XML String of utf-8 * * @return XML-Formed string */ public static String getUTF8XMLString ...
- Python3中内置类型bytes和str用法及byte和string之间各种编码转换,python--列表,元组,字符串互相转换
Python3中内置类型bytes和str用法及byte和string之间各种编码转换 python--列表,元组,字符串互相转换 列表,元组和字符串python中有三个内建函数:,他们之间的互相转换 ...
- C# string字节数组转换
string转byte[]:byte[] byteArray = System.Text.Encoding.Default.GetBytes ( str ); byte[]转string:string ...
- C#字节数组转换成字符串
C#字节数组转换成字符串 如果还想从 System.String 类中找到方法进行字符串和字节数组之间的转换,恐怕你会失望了.为了进行这样的转换,我们不得不借助另一个类:System.Text.Enc ...
- PHP 支持中文目录和文件的的遍历:文件编码转换
在使用 readdir() 遍历指定目录时,使中文目录和文件名都正常显示需要使用 iconv() 进行文件编码转换: <?php header("Content-type:text/h ...
- java中string与byte[]的转换
1.string 转 byte[] byte[] midbytes=isoString.getBytes("UTF8"); //为UTF8编码 byte[] isoret = sr ...
随机推荐
- hdu1564博弈+找规律
#include<map> #include<set> #include<cmath> #include<queue> #include<stac ...
- 向多页TABLE中插入数据时,新增行总是在当前页的最后一行
CODE IN CO OATableBean table = (OATableBean)webBean.findChildRecursive("LineTable"); int n ...
- ViewPager + Fragment 实现主界面底部导航栏
1. 四个类似的Frament布局 tab_main_fragment.xml <LinearLayout xmlns:android="http://schemas.android. ...
- Pale Moon 苍月浏览器 24.0.1 发布
火狐浏览器知名修改版—苍月浏览器Pale Moon今天发布24.0.1版本,该版本基于Firefox 最近更新的24.0.1正式版. 下载地址: 32位下载:http://relmirror.pale ...
- 《Java程序设计》十四次作业
<Java程序设计>十四次作业实验总结 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结与数据库相关内容. 3. 代码量统计 周次 总代码量 新增代码量 总文件数 新增 ...
- Shell 命令行,写一个自动整理 ~/Downloads/ 文件夹下文件的脚本
Shell 命令行,写一个自动整理 ~/Downloads/ 文件夹下文件的脚本 在 mac 或者 linux 系统中,我们的浏览器或者其他下载软件下载的文件全部都下载再 ~/Downloads/ 文 ...
- Ubuntu tar方式安装mysql5.7.21 时报错 [ERROR] Can't locate the language directory. 以及 ------ libaio.so.1: cannot open shared object file
参考帖子: http://blog.csdn.net/ty0415/article/details/22958133 首先,在 MySQL 官方网站上下载安装包, 如图: 然后,执行安装命令 bin/ ...
- BZOJ3123: [Sdoi2013]森林(启发式合并&主席树)
3123: [Sdoi2013]森林 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 4813 Solved: 1420[Submit][Status ...
- [CF995F]Cowmpany Cowmpensation
codeforces description 一棵\(n\)个节点的树,给每个节点标一个\([1,m]\)之间的编号,要求儿子的权值不大于父亲权值.求方案数.\(n\le3000,n\le10^9\) ...
- JDBC的操作步骤
JDBC的操作步骤 一.什么是JDBC JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问 ...