20162314 《Program Design & Data Structures》Learning Summary Of The Eleventh Week
20162314 2017-2018-1 《Program Design & Data Structures》Learning Summary Of The Eleventh Week
Summary of Key Concepts
In hashing, elements are stored in a hash table, with their location in thetable determined by a hashing function.
The situation where two elements or keys map to the same location in the table is called a collision.
A hashing function that maps each element to a unique position in the table is said to be a perfect hashing function.
Extraction involves using only a part of the element’s value or key to compute the location at which to store the element.
The division method is very effective when dealing with an unknown set of key values.
In the shift folding method, the parts of the key are added together to create the index.
The length-dependent method and the mid-square method may also be effectively used with strings by manipulating the binary representations of the characters in the string.
Although Java provides a hashcode method for all objects, it is often preferable to define a specific hashing function for any particular class.
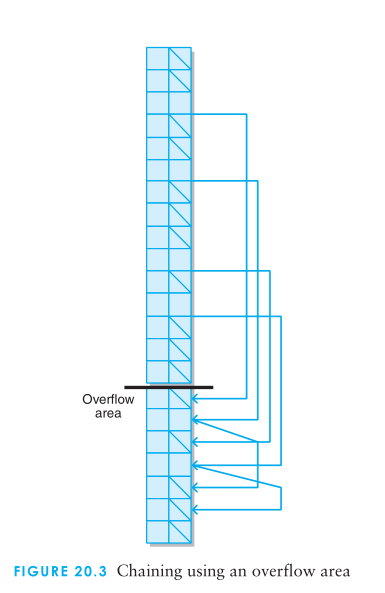
The chaining method for handling collisions simply treats the hash table conceptually as a table of collections rather than as a table of individual cells.
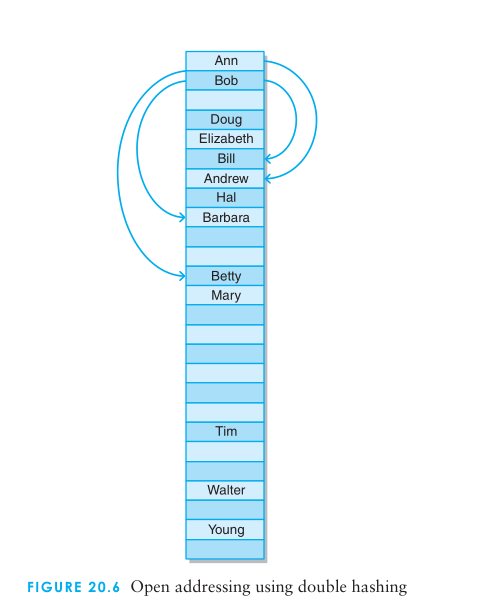
The open addressing method for handling collisions looks for another open position in the table other than the one to which the element is originally hashed.
The load factor is the maximum percentage occupancy allowed in the hash table before it is resized.
Problem and solution in teaching materials.
What is the difference between a hash table and the other collections we have discussed?

- Elements are placed into a hash table at an index produced by a function of the value of the element or a key of the element.
- This is unique from other collections where the position/locationof an element in the collection is determined either by comparison
- with the other values in the collection or by the order in which the elements were added or removed from the collection.
What is our goal for a hashing function?
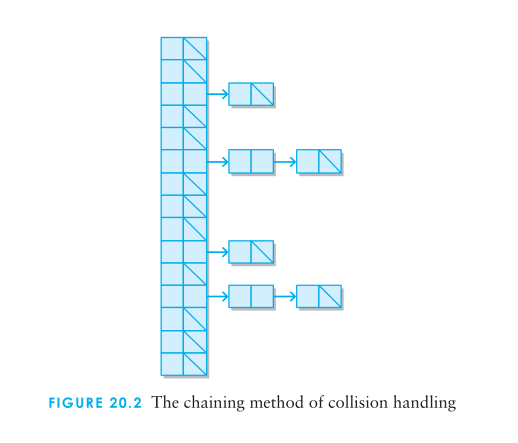
- We need a hashing function that will do a good job of distributing elements into positions in the table.
What is the consequence of not having a good hashing function?
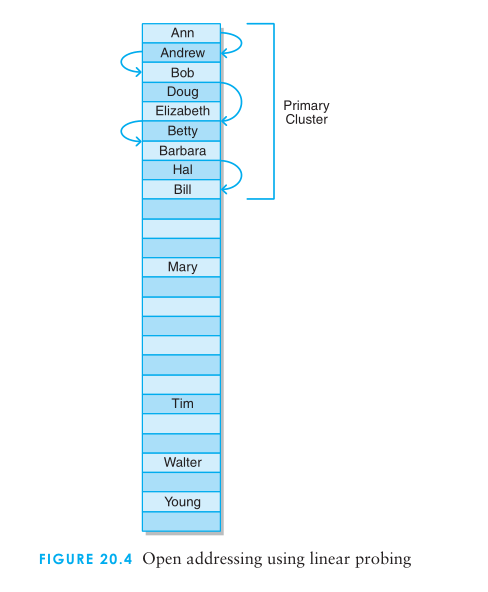
- If we do not have a good hashing function, the result will be too many elements mapped to the same location in the table. This will result in poor performance.
Why is deletion from an open addressing implementation a problem?
- Because of the way that a path is formed in open addressing,deleting an element from the middle of that path can cause elements beyond that on the path to be unreachable.
What is the load factor and how does it affect table size?
- The load factor is the maximum percentage occupancy allowed in the hash table before it is resized. Once the load factor has
- been reached, a new table is created that is twice the size of the current table, and then all of the elements in the current table
- are inserted into the new table.
Code hosting
What is the maximum number of edges for an undirected graph? A directed graph?
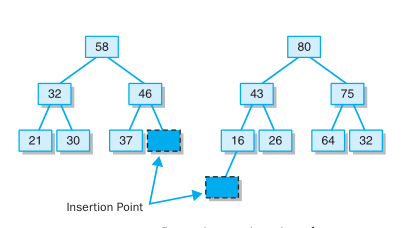
- The maximum element is removed from a heap (maxheap) by replacing the root with the last leaf of the tree, then moving that
- element down the tree as appropriate to reassert the proper relationships among the elements.
Summary of error for last week.
Linear search is always more effective than binary search.The answer should be false, for the situation of "n = 2".
Evaluate for my partner
- Advantage and problem in the blog:
- Concise and comprehensie
- Uncleary to the content
- Mould is amazing
- Advantage and problem in the code:
- Serious writing.
- Wonderful idea
- Too less
Learning situation of partner
- Learning content of partner:
- Algorithm
- Recursion
- HanoiTowers and maze
Anything else that want to say
- It's not easy to persere on utizing English to write a blog.But I'm getting used to doing this because of the benefit.
Academic progress check
| Code line number(increasing/accumulative) | Blog number(inc/acc) | studying time(inc/acc) | progress | |
|---|---|---|---|---|
| target | 5000lines | 30articles | 400hours | |
| First week | 180/180 | 1/1 | 20/20 | |
| Second week | 1049/1229 | 1/2 | 18/38 | |
| Third week | 1037/2266 | 3/7 | 22/60 | |
| Fourth week | 1120/3386 | 2/9 | 30/90 |
20162314 《Program Design & Data Structures》Learning Summary Of The Eleventh Week的更多相关文章
- 20162314 《Program Design & Data Structures》Learning Summary Of The Ninth Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The Ninth Week ...
- 20162314 《Program Design & Data Structures》Learning Summary Of The Seventh Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The Seventh Wee ...
- 20162314 《Program Design & Data Structures》Learning Summary Of The Fifth Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The Fifth Week ...
- 20162314 《Program Design & Data Structures》Learning Summary Of The Second Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The Second Week ...
- 20162314 《Program Design & Data Structures》Learning Summary Of The First Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The First Week ...
- 20162314 《Program Design & Data Structures》Learning Summary Of The Tenth Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The Tenth Week ...
- 20162314 《Program Design & Data Structures》Learning Summary Of The Eighth Week
20162314 2017-2018-1 <Program Design & Data Structures>Learning Summary Of The Eighth Week ...
- 20182320《Program Design and Data Structures》Learning Summary Week9
20182320<Program Design and Data Structures>Learning Summary Week9 1.Summary of Textbook's Con ...
- 【Python学习笔记】Coursera课程《Python Data Structures》 密歇根大学 Charles Severance——Week6 Tuple课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week6 Tuple 10 Tuples 10.1 Tuples A ...
随机推荐
- C++虚继承的概念[转]
C++中虚拟继承的概念 为了解决从不同途径继承来的同名的数据成员在内存中有不同的拷贝造成数据不一致问题,将共同基类设置为虚基类.这时从不同的路径继承过来的同名数据成员在内存中就只有一个拷贝,同一个函数 ...
- Android Runtime.getRuntime().exec
try { // Executes the command. Process process = Runtime.getRuntime().exec(cmd); // NOTE: You can wr ...
- html5实现的一些效果
一.网页换肤 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <ti ...
- HUB、SPAN、TAP比较
在获取数据包进行网络分析时,常用的方法有三种:HUB.SPAN和TAP. 一 HUB HUB 很“弱智”,但这种方法却是最早的数据包获取方法.HUB是半双工的以太网设备,在广播数据包时,无法同时 ...
- 【BZOJ4101】[Usaco2015 Open]Trapped in the Haybales Silver 二分
[BZOJ4101][Usaco2015 Open]Trapped in the Haybales (Silver) Description Farmer John has received a sh ...
- js对字符串进行加密和解密方法!
在做一些微信小程序,或混合 app 的时候,或者是考虑到一些 JS 数据安全的问题.可能会使用到 JS 对用户信息进行缓存. 例如在开发:微信小程序对用户进行加密缓存,开发混合APP对用户信息进行加密 ...
- kafka简介【转】
一.为什么需要消息系统 () 解耦 在项目启动之初来预测将来项目会碰到什么需求,是极其困难的.消息系统在处理过程中间插入了一个隐含的.基于数据的接口层,两边的处理过程都要实现这一接口.这允许你独立的扩 ...
- StartUML-类图
- Redis 缓存穿透,缓存击穿,缓存雪崩的解决方案分析
设计一个缓存系统,不得不要考虑的问题就是:缓存穿透.缓存击穿与失效时的雪崩效应. 一.什么样的数据适合缓存? 分析一个数据是否适合缓存,我们要从访问频率.读写比例.数据一致性等要求去分析. 二.什么 ...
- JavaWeb404排错的小技巧
报这种错误,404后面什么都没有的话,就证明处理器映射器根据url找不到handler. 报这种错误,证明处理器映射器根据url找到了handler,转发的jsp页面找不到,说明jsp页面错了.