6 spark 存储体系
6.1 block存储体系

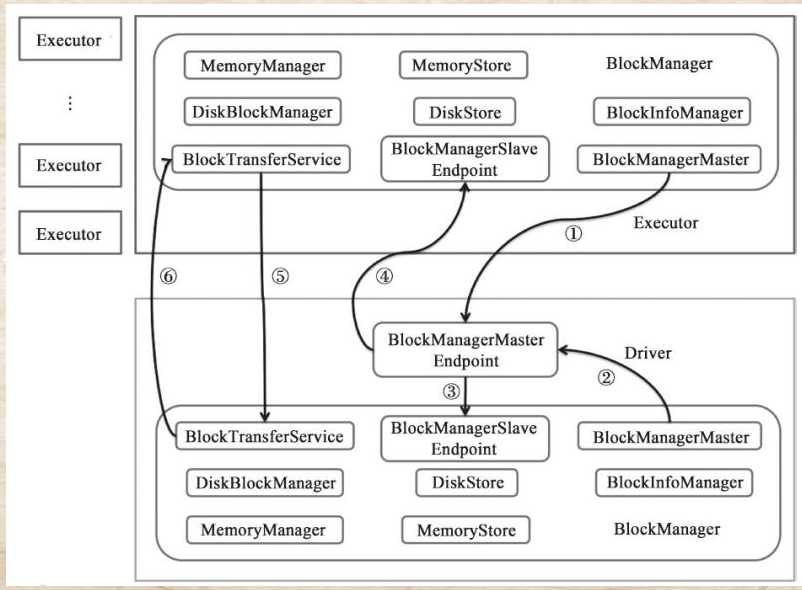
存储体系架构图

6.2 block 信息信息管理器
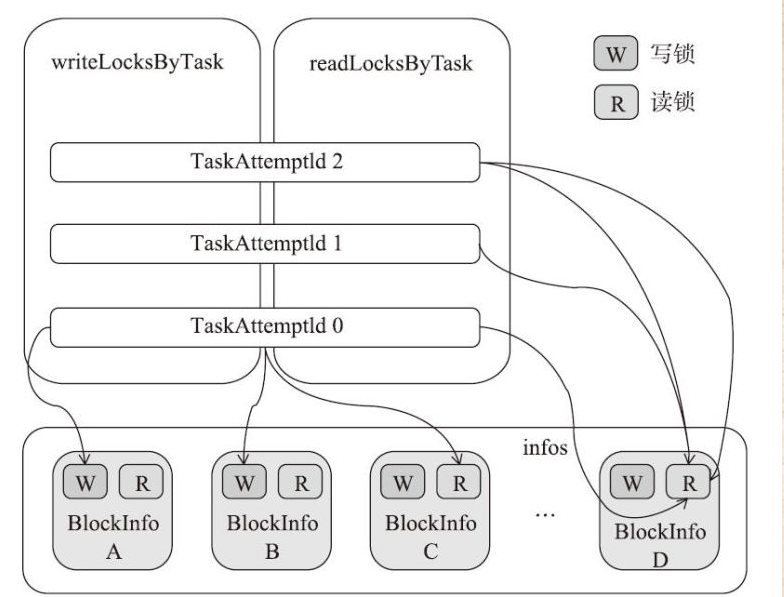

6.2.2 bock锁的实现
6.3 磁盘block管理
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.spark.storage import javax.annotation.concurrent.GuardedBy import scala.collection.JavaConverters._
import scala.collection.mutable
import scala.reflect.ClassTag import com.google.common.collect.{ConcurrentHashMultiset, ImmutableMultiset} import org.apache.spark.{SparkException, TaskContext}
import org.apache.spark.internal.Logging /**
* Tracks metadata for an individual block.
*
* Instances of this class are _not_ thread-safe and are protected by locks in the
* [[BlockInfoManager]].
*
* @param level the block's storage level. This is the requested persistence level, not the
* effective storage level of the block (i.e. if this is MEMORY_AND_DISK, then this
* does not imply that the block is actually resident in memory).
* @param classTag the block's [[ClassTag]], used to select the serializer
* @param tellMaster whether state changes for this block should be reported to the master. This
* is true for most blocks, but is false for broadcast blocks.
*/
private[storage] class BlockInfo(
val level: StorageLevel,
val classTag: ClassTag[_],
val tellMaster: Boolean) { /**
* The size of the block (in bytes)
*/
def size: Long = _size
def size_=(s: Long): Unit = {
_size = s
checkInvariants()
}
private[this] var _size: Long = /**
* The number of times that this block has been locked for reading.
*/
def readerCount: Int = _readerCount
def readerCount_=(c: Int): Unit = {
_readerCount = c
checkInvariants()
}
private[this] var _readerCount: Int = /**
* The task attempt id of the task which currently holds the write lock for this block, or
* [[BlockInfo.NON_TASK_WRITER]] if the write lock is held by non-task code, or
* [[BlockInfo.NO_WRITER]] if this block is not locked for writing.
*/
def writerTask: Long = _writerTask
def writerTask_=(t: Long): Unit = {
_writerTask = t
checkInvariants()
}
private[this] var _writerTask: Long = BlockInfo.NO_WRITER private def checkInvariants(): Unit = {
// A block's reader count must be non-negative:
assert(_readerCount >= )
// A block is either locked for reading or for writing, but not for both at the same time:
assert(_readerCount == || _writerTask == BlockInfo.NO_WRITER)
} checkInvariants()
} private[storage] object BlockInfo { /**
* Special task attempt id constant used to mark a block's write lock as being unlocked.
*/
val NO_WRITER: Long = - /**
* Special task attempt id constant used to mark a block's write lock as being held by
* a non-task thread (e.g. by a driver thread or by unit test code).
*/
val NON_TASK_WRITER: Long = -
} /**
* Component of the [[BlockManager]] which tracks metadata for blocks and manages block locking.
*
* The locking interface exposed by this class is readers-writer lock. Every lock acquisition is
* automatically associated with a running task and locks are automatically released upon task
* completion or failure.
*
* This class is thread-safe.
*/
private[storage] class BlockInfoManager extends Logging { private type TaskAttemptId = Long /**
* Used to look up metadata for individual blocks. Entries are added to this map via an atomic
* set-if-not-exists operation ([[lockNewBlockForWriting()]]) and are removed
* by [[removeBlock()]].
*/
@GuardedBy("this")
private[this] val infos = new mutable.HashMap[BlockId, BlockInfo] /**
* Tracks the set of blocks that each task has locked for writing.
*/
@GuardedBy("this")
private[this] val writeLocksByTask =
new mutable.HashMap[TaskAttemptId, mutable.Set[BlockId]]
with mutable.MultiMap[TaskAttemptId, BlockId] /**
* Tracks the set of blocks that each task has locked for reading, along with the number of times
* that a block has been locked (since our read locks are re-entrant).
*/
@GuardedBy("this")
private[this] val readLocksByTask =
new mutable.HashMap[TaskAttemptId, ConcurrentHashMultiset[BlockId]] // ---------------------------------------------------------------------------------------------- // Initialization for special task attempt ids:
registerTask(BlockInfo.NON_TASK_WRITER) // ---------------------------------------------------------------------------------------------- /**
* Called at the start of a task in order to register that task with this [[BlockInfoManager]].
* This must be called prior to calling any other BlockInfoManager methods from that task.
*/
def registerTask(taskAttemptId: TaskAttemptId): Unit = synchronized {
require(!readLocksByTask.contains(taskAttemptId),
s"Task attempt $taskAttemptId is already registered")
readLocksByTask(taskAttemptId) = ConcurrentHashMultiset.create()
} /**
* Returns the current task's task attempt id (which uniquely identifies the task), or
* [[BlockInfo.NON_TASK_WRITER]] if called by a non-task thread.
*/
private def currentTaskAttemptId: TaskAttemptId = {
Option(TaskContext.get()).map(_.taskAttemptId()).getOrElse(BlockInfo.NON_TASK_WRITER)
} /**
* Lock a block for reading and return its metadata.
*
* If another task has already locked this block for reading, then the read lock will be
* immediately granted to the calling task and its lock count will be incremented.
*
* If another task has locked this block for writing, then this call will block until the write
* lock is released or will return immediately if `blocking = false`.
*
* A single task can lock a block multiple times for reading, in which case each lock will need
* to be released separately.
*
* @param blockId the block to lock.
* @param blocking if true (default), this call will block until the lock is acquired. If false,
* this call will return immediately if the lock acquisition fails.
* @return None if the block did not exist or was removed (in which case no lock is held), or
* Some(BlockInfo) (in which case the block is locked for reading).
*/
def lockForReading(
blockId: BlockId,
blocking: Boolean = true): Option[BlockInfo] = synchronized {
logTrace(s"Task $currentTaskAttemptId trying to acquire read lock for $blockId")
do {
infos.get(blockId) match {
case None => return None
case Some(info) =>
if (info.writerTask == BlockInfo.NO_WRITER) {
info.readerCount +=
readLocksByTask(currentTaskAttemptId).add(blockId)
logTrace(s"Task $currentTaskAttemptId acquired read lock for $blockId")
return Some(info)
}
}
if (blocking) {
wait()
}
} while (blocking)
None
} /**
* Lock a block for writing and return its metadata.
*
* If another task has already locked this block for either reading or writing, then this call
* will block until the other locks are released or will return immediately if `blocking = false`.
*
* @param blockId the block to lock.
* @param blocking if true (default), this call will block until the lock is acquired. If false,
* this call will return immediately if the lock acquisition fails.
* @return None if the block did not exist or was removed (in which case no lock is held), or
* Some(BlockInfo) (in which case the block is locked for writing).
*/
def lockForWriting(
blockId: BlockId,
blocking: Boolean = true): Option[BlockInfo] = synchronized {
logTrace(s"Task $currentTaskAttemptId trying to acquire write lock for $blockId")
do {
infos.get(blockId) match {
case None => return None
case Some(info) =>
if (info.writerTask == BlockInfo.NO_WRITER && info.readerCount == ) {
info.writerTask = currentTaskAttemptId
writeLocksByTask.addBinding(currentTaskAttemptId, blockId)
logTrace(s"Task $currentTaskAttemptId acquired write lock for $blockId")
return Some(info)
}
}
if (blocking) {
wait()
}
} while (blocking)
None
} /**
* Throws an exception if the current task does not hold a write lock on the given block.
* Otherwise, returns the block's BlockInfo.
*/
def assertBlockIsLockedForWriting(blockId: BlockId): BlockInfo = synchronized {
infos.get(blockId) match {
case Some(info) =>
if (info.writerTask != currentTaskAttemptId) {
throw new SparkException(
s"Task $currentTaskAttemptId has not locked block $blockId for writing")
} else {
info
}
case None =>
throw new SparkException(s"Block $blockId does not exist")
}
} /**
* Get a block's metadata without acquiring any locks. This method is only exposed for use by
* [[BlockManager.getStatus()]] and should not be called by other code outside of this class.
*/
private[storage] def get(blockId: BlockId): Option[BlockInfo] = synchronized {
infos.get(blockId)
} /**
* Downgrades an exclusive write lock to a shared read lock.
*/
def downgradeLock(blockId: BlockId): Unit = synchronized {
logTrace(s"Task $currentTaskAttemptId downgrading write lock for $blockId")
val info = get(blockId).get
require(info.writerTask == currentTaskAttemptId,
s"Task $currentTaskAttemptId tried to downgrade a write lock that it does not hold on" +
s" block $blockId")
unlock(blockId)
val lockOutcome = lockForReading(blockId, blocking = false)
assert(lockOutcome.isDefined)
} /**
* Release a lock on the given block.
* In case a TaskContext is not propagated properly to all child threads for the task, we fail to
* get the TID from TaskContext, so we have to explicitly pass the TID value to release the lock.
*
* See SPARK-18406 for more discussion of this issue.
*/
def unlock(blockId: BlockId, taskAttemptId: Option[TaskAttemptId] = None): Unit = synchronized {
val taskId = taskAttemptId.getOrElse(currentTaskAttemptId)
logTrace(s"Task $taskId releasing lock for $blockId")
val info = get(blockId).getOrElse {
throw new IllegalStateException(s"Block $blockId not found")
}
if (info.writerTask != BlockInfo.NO_WRITER) {
info.writerTask = BlockInfo.NO_WRITER
writeLocksByTask.removeBinding(taskId, blockId)
} else {
assert(info.readerCount > , s"Block $blockId is not locked for reading")
info.readerCount -=
val countsForTask = readLocksByTask(taskId)
val newPinCountForTask: Int = countsForTask.remove(blockId, ) -
assert(newPinCountForTask >= ,
s"Task $taskId release lock on block $blockId more times than it acquired it")
}
notifyAll()
} /**
* Attempt to acquire the appropriate lock for writing a new block.
*
* This enforces the first-writer-wins semantics. If we are the first to write the block,
* then just go ahead and acquire the write lock. Otherwise, if another thread is already
* writing the block, then we wait for the write to finish before acquiring the read lock.
*
* @return true if the block did not already exist, false otherwise. If this returns false, then
* a read lock on the existing block will be held. If this returns true, a write lock on
* the new block will be held.
*/
def lockNewBlockForWriting(
blockId: BlockId,
newBlockInfo: BlockInfo): Boolean = synchronized {
logTrace(s"Task $currentTaskAttemptId trying to put $blockId")
lockForReading(blockId) match {
case Some(info) =>
// Block already exists. This could happen if another thread races with us to compute
// the same block. In this case, just keep the read lock and return.
false
case None =>
// Block does not yet exist or is removed, so we are free to acquire the write lock
infos(blockId) = newBlockInfo
lockForWriting(blockId)
true
}
} /**
* Release all lock held by the given task, clearing that task's pin bookkeeping
* structures and updating the global pin counts. This method should be called at the
* end of a task (either by a task completion handler or in `TaskRunner.run()`).
*
* @return the ids of blocks whose pins were released
*/
def releaseAllLocksForTask(taskAttemptId: TaskAttemptId): Seq[BlockId] = synchronized {
val blocksWithReleasedLocks = mutable.ArrayBuffer[BlockId]() val readLocks = readLocksByTask.remove(taskAttemptId).getOrElse(ImmutableMultiset.of[BlockId]())
val writeLocks = writeLocksByTask.remove(taskAttemptId).getOrElse(Seq.empty) for (blockId <- writeLocks) {
infos.get(blockId).foreach { info =>
assert(info.writerTask == taskAttemptId)
info.writerTask = BlockInfo.NO_WRITER
}
blocksWithReleasedLocks += blockId
} readLocks.entrySet().iterator().asScala.foreach { entry =>
val blockId = entry.getElement
val lockCount = entry.getCount
blocksWithReleasedLocks += blockId
get(blockId).foreach { info =>
info.readerCount -= lockCount
assert(info.readerCount >= )
}
} notifyAll() blocksWithReleasedLocks
} /** Returns the number of locks held by the given task. Used only for testing. */
private[storage] def getTaskLockCount(taskAttemptId: TaskAttemptId): Int = {
readLocksByTask.get(taskAttemptId).map(_.size()).getOrElse() +
writeLocksByTask.get(taskAttemptId).map(_.size).getOrElse()
} /**
* Returns the number of blocks tracked.
*/
def size: Int = synchronized {
infos.size
} /**
* Return the number of map entries in this pin counter's internal data structures.
* This is used in unit tests in order to detect memory leaks.
*/
private[storage] def getNumberOfMapEntries: Long = synchronized {
size +
readLocksByTask.size +
readLocksByTask.map(_._2.size()).sum +
writeLocksByTask.size +
writeLocksByTask.map(_._2.size).sum
} /**
* Returns an iterator over a snapshot of all blocks' metadata. Note that the individual entries
* in this iterator are mutable and thus may reflect blocks that are deleted while the iterator
* is being traversed.
*/
def entries: Iterator[(BlockId, BlockInfo)] = synchronized {
infos.toArray.toIterator
} /**
* Removes the given block and releases the write lock on it.
*
* This can only be called while holding a write lock on the given block.
*/
def removeBlock(blockId: BlockId): Unit = synchronized {
logTrace(s"Task $currentTaskAttemptId trying to remove block $blockId")
infos.get(blockId) match {
case Some(blockInfo) =>
if (blockInfo.writerTask != currentTaskAttemptId) {
throw new IllegalStateException(
s"Task $currentTaskAttemptId called remove() on block $blockId without a write lock")
} else {
infos.remove(blockId)
blockInfo.readerCount =
blockInfo.writerTask = BlockInfo.NO_WRITER
writeLocksByTask.removeBinding(currentTaskAttemptId, blockId)
}
case None =>
throw new IllegalArgumentException(
s"Task $currentTaskAttemptId called remove() on non-existent block $blockId")
}
notifyAll()
} /**
* Delete all state. Called during shutdown.
*/
def clear(): Unit = synchronized {
infos.valuesIterator.foreach { blockInfo =>
blockInfo.readerCount =
blockInfo.writerTask = BlockInfo.NO_WRITER
}
infos.clear()
readLocksByTask.clear()
writeLocksByTask.clear()
notifyAll()
} }
6 spark 存储体系的更多相关文章
- Spark存储体系
作为分布式应用,Spark的数据存储在不同机器上.这就涉及到数据的传输,元数据的管理等内容.而且由于Spark可以利用内存和磁盘作为存储介质,这还涉及到了内存和磁盘的数据管理. Spark存储体系架构 ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- 6 spark 存储体系 --内存管理
6.5 memoryMode
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- 《深入理解Spark-核心思想与源码分析》(四)第四章存储体系
天行健,君子以自强不息:地势坤,君子以厚德载物.——<易经> 本章导读 Spark的初始化阶段.任务提交阶段.执行阶段,始终离不开存储体系. Spark为了避免Hadoop读写磁盘的I/O ...
- hbase的存储体系
一.了解hbase的存储体系. hbase的存储体系核心的有Split机制,Flush机制和Compact机制. 1.split机制 每一个hbase的table表在刚刚开始的时候,只有一个regio ...
- Spark存储介绍
目录 整体架构 存储相关类 应用启动时 增删改后更新元数据 获取数据存放位置 数据块的删除 RDD存储调用 数据读取 数据写入 cache & checkpoint Reference 记录一 ...
- GPU体系架构(二):GPU存储体系
GPU是一个外围设备,本来是专门作为图形渲染使用的,但是随着其功能的越来越强大,GPU也逐渐成为继CPU之后的又一计算核心.但不同于CPU的架构设计,GPU的架构从一开始就更倾向于图形渲染和大规模数据 ...
- Spark存储Parquet数据到Hive,对map、array、struct字段类型的处理
利用Spark往Hive中存储parquet数据,针对一些复杂数据类型如map.array.struct的处理遇到的问题? 为了更好的说明导致问题的原因.现象以及解决方案,首先看下述示例: -- 创建 ...
随机推荐
- 关于容器、虚拟机以及 Docker 的一个入门教程
Yves yao · 2017-09-05翻译 · 1315阅读 原文链接 huangxiaolu审校 源地址:http://zcfy.cc/article/a-beginner-friendly ...
- csharp: Gets a files formatted size.
/* ASP.NET 默认上传文件是4M ,可以修改服务配置.. <system.web> <!-- 指示 ASP.NET 支持的最大文件上载大小. 该限制可用于防止因用户将大量文件 ...
- 普通平衡树Tyvj1728、luogu P3369 (splay)
存个模板,这次是splay的: 题目见这个题解: <--(鼠标移到这儿) 代码如下: #include<cstdio> #define INF 2147483647 using na ...
- js 中concat()和slice()方法介绍
1.concat() concat() 方法用于连接两个或多个数组. 该方法不会改变现有的数组,而仅仅会返回被连接数组的一个副本. <script type="text/javascr ...
- TensorFlow-卷积
卷积: conv2d ( input, filter, strides, padding, use_cudnn_on_gpu=True, data_format='NHWC', name=No ...
- Remove Duplicates from Sorted List 去除链表中重复值节点
Given a sorted linked list, delete all duplicates such that each element appear only once. For examp ...
- How do I use the API correctly
1:打开帮助文档2:点击显示,找到索引,看到输入框3:你要学习什么内容,你就在框框里面输入什么内容 举例:Random4:看包 java.lang包下的类在使用的时候是不需要导包的5:看类的描述 Ra ...
- 了解 Azure VM 的系统重启
有时 Azure 虚拟机 (VM) 可能重启,即使没有明显原因,也没有证据表明用户发起重启操作. 本文列出了可导致 VM 重启的操作和事件,并针对如何避免意外重启问题或减少该问题影响提供见解. 配置 ...
- SparkRDD函数详解
1.RDD操作详解 启动spark-shell spark-shell --master spark://hdp-node-01:7077 1.1 基本转换 1) map map是对RDD中的每个元素 ...
- JDBC连接数据库反射实现O/R映射
测试preparedStatement public void testPreparedStatement(){ Connection connection=null; PreparedStateme ...