Hadoop学习笔记---HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
前提和设计目标
硬件错误
硬件错误是常态而不是异常。HDFS可能由成百上千的服务器所构成,每个服务器上存储着文件系统的部分数据。我们面对的现实是构成系统的组件数目是巨大的,而且任一组件都有可能失效,这意味着总是有一部分HDFS的组件是不工作的。因此错误检测和快速、自动的恢复是HDFS最核心的架构目标。
流式数据访问
运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。POSIX标准设置的很多硬性约束对HDFS应用系统不是必需的。为了提高数据的吞吐量,在一些关键方面对POSIX的语义做了一些修改。
大规模数据集
运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
简单的一致性模型
HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
“移动计算比移动数据更划算”
一个应用请求的计算,离它操作的数据越近就越高效,在数据达到海量级别的时候更是如此。因为这样就能降低网络阻塞的影响,提高系统数据的吞吐量。将计算移动到数据附近,比之将数据移动到应用所在显然更好。HDFS为应用提供了将它们自己移动到数据附近的接口。
异构软硬件平台间的可移植性
HDFS在设计的时候就考虑到平台的可移植性。这种特性方便了HDFS作为大规模数据应用平台的推广。
Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
体系结构:
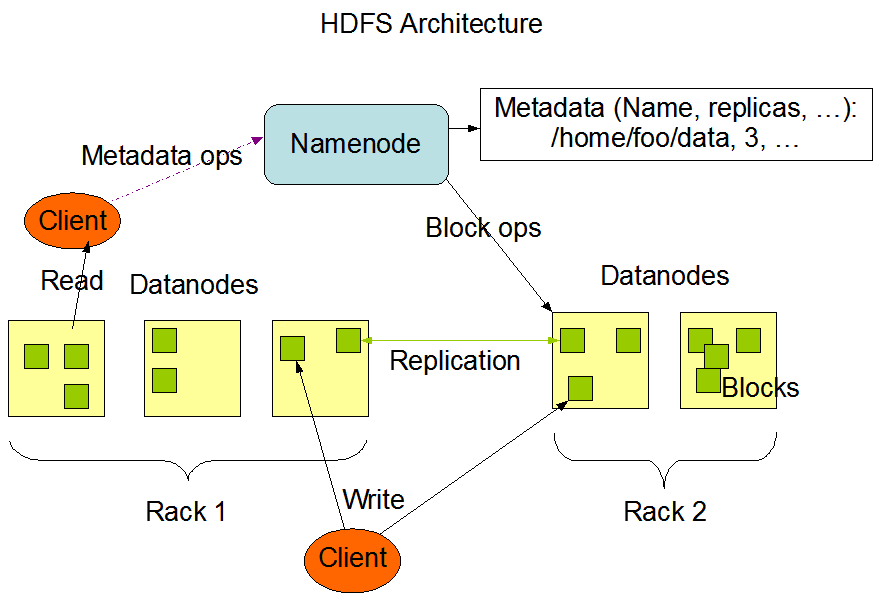
NameNode:管理文件系统的命名空间;记录每个文件数据块在各个DataNode上的位置和副本信息;处理客户端请求;配置副本策略;
DataNode:负责所在物理节点的存储管理;一次写入,多次读取;数据尽量分散到各个节点;文件由数据库组成,一般情况下,数据块的大小为64MB;
SecondaryNameNode:是NameNode的冷备份;合并fsimage和fsedits然后再发给NameNode;
simage:元数据镜像文件(文件系统的目录树),存储某一时段NameNode内存 元数据信息。
edits:元数据的操作日志(针对文件系统做的修改操作记录)
fstime: 保存最近一次checkpoint的时间
文件系统的名字空间 (namespace)
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。当前,HDFS不支持用户磁盘配额和访问权限控制,也不支持硬链接和软链接。但是HDFS架构并不妨碍实现这些特性。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来。应用程序可以设置HDFS保存的文件的副本数目。文件副本的数目称为文件的副本系数,这个信息也是由Namenode保存的。
数据复制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,除了最后一个,所有的数据块都是同样大小的。为了容错,文件的所有数据块都会有副本。每个文件的数据块大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
Hadoop学习笔记---HDFS的更多相关文章
- Hadoop学习笔记—HDFS
目录 搭建安装 三个核心组件 安装 配置环境变量 配置各上述三组件守护进程的相关属性 启停 监控和性能 Hadoop Rack Awareness yarn的NodeManagers监控 命令 hdf ...
- Hadoop学习笔记-HDFS命令
进入 $HADOOP/bin 一.文件操作 文件操作 类似于正常的linux操作前面加上“hdfs dfs -” 前缀也可以写成hadoop而不用hdfs,但终端中显示 Use of this scr ...
- Hadoop学习笔记——HDFS
1.查看hdfs文件的block信息 不正常的文件 hdfs fsck /logs/xxx/xxxx.gz.gz -files -blocks -locations Connecting to nam ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
随机推荐
- ASP.NET之Jquery入门级别
1.Jquery的简单介绍 1)Jquery由美国人John Resig创建.是继prototype之后又一个优秀的JavaScript框架. 2)JQuery能做什么?JQuery能做的普通的Dom ...
- Spring Boot学习笔记(二)全局捕获异常处理
非常简单只需要创建自己的异常处理类,加上两个注解,就可以了
- 阿里巴巴的数据池DRUID
使用了阿里巴巴的数据池管理: 监控DB池连接和SQL的执行情况 https://github.com/alibaba/druid/wiki/常见问题 https://www.cnblogs.com ...
- poj 3104 dring 二分
Drying Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 7684 Accepted: 1967 Descriptio ...
- K:大数加法
相关介绍: 在java中,整数是有最大上限的.所谓大数是指超过整数最大上限的数,例如18 452 543 389 943 209 789 324 233和8 123 534 323 432 323 ...
- K:栈相关的算法
本博文总结了常见的应用栈来进行实现的相关算法 ps:点击相关问题的标题,即可进入相关的博文进行查看其算法的思想及其实现,这篇博文更多的是作为目录使用 大数加法:在java中,整数是有最大上限的.所谓大 ...
- Oracle数据库基本操作(四) —— PLSQL编程
Procedure Language 实际上是Oracle对SQL语言的能力扩展,让SQL语言拥有了if条件判断,for循环等处理. 一.PLSQL基本语法 DECLARE -- 声明部分 变量名 变 ...
- 【零基础学习FreeRTOS嵌入式系统】之一:FreeRTOS环境搭建
[零基础学习FreeRTOS嵌入式系统]之一:FreeRTOS环境搭建 一:FreeRTOS系统下载 在官网上https://www.freertos.org/,找到下载入口. 或直接进入下载地址ht ...
- BZOJ P4720[Noip2016]换教室____solution
题目太长不表 <--无形传送,最为致命 学习一点数学期望的基础,预处理最短路,然后加上DP即可.(废话) 理解决策和结果的差别: 在这里每阶段的决策有两个:申请|不申请 结果有两个:换|不换 然 ...
- 验证两台机器已经建立的ssh互信
1.expect方法 #!/bin/bash checkTrust() { expect -c ' set timeout 2; spawn ssh $1 "expr 12345678 + ...