mysql分表,批量生成数据
一、mysql的分表策略
根据经验,Mysql表数据一般达到百万级别,查询效率会很低,容易造成表锁,甚至堆积很多连接,直接挂掉;
1,水平分割:
水平(横向)拆分:将同一个表的数据进行分块保存到不同的数据库中,来解决单表中数据量增长出现的压力。
表结构设计水平切分。常见的一些场景包括
a). 比如在线电子商务网站,订单表数据量过大,按照年度、月度水平切分
b). Web 2.0网站注册用户、在线活跃用户过多,按照用户ID范围等方式,将相关用户以及该用户紧密关联的表做水平切分
c). 例如论坛的置顶帖子,因为涉及到分页问题,每页都需要显示置顶贴,这种情况可以把置顶贴水平切分开来,避免取置顶帖子时从所有帖子的表中读取
例:QQ的登录表。假设QQ的用户有100亿,如果只有一张表,每个用户登录的时候数据库都要从这100亿中查找,会很慢很慢。如果将这一张表分成100份,每张表有1亿条,就小了很多,比如qq0,qq1,qq1...qq99表。
用户登录的时候,可以将用户的id%100,那么会得到0-99的数,查询表的时候,将表名qq跟取模的数连接起来,就构建了表名。比如123456789用户,取模的89,那么就到qq89表查询,查询的时间将会大大缩短。
这就是水平分割。
2,垂直分割:
垂直分割指的是:表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
表结构设计垂直切分。常见的一些场景包括
a). 大字段的垂直切分。单独将大字段建在另外的表中,提高基础表的访问性能,原则上在性能关键的应用中应当避免数据库的大字段
b). 按照使用用途垂直切分。例如企业物料属性,可以按照基本属性、销售属性、采购属性、生产制造属性、财务会计属性等用途垂直切分
c). 按照访问频率垂直切分。例如电子商务、Web 2.0系统中,如果用户属性设置非常多,可以将基本、使用频繁的属性和不常用的属性垂直切分开
例如学生答题表tt:有如下字段:
Id name 分数 题目 回答
其中题目和回答是比较大的字段,id name 分数比较小。
如果我们只想查询id为8的学生的分数:select 分数 from tt where id = 8;虽然知识查询分数,但是题目和回答这两个大字段也是要被扫描的,很消耗性能。但是我们只关心分数,并不想查询题目和回答。这就可以使用垂直分割。我们可以把题目单独放到一张表中,通过id与tt表建立一对一的关系,同样将回答单独放到一张表中。这样我们插叙tt中的分数的时候就不会扫描题目和回答了。
3,其他要点:
1)存放图片、文件等大文件用文件系统存储。数据库只存储路径,图片和文件存放在文件系统,甚至单独存放在一台服务器
二、Spring事务的隔离级别
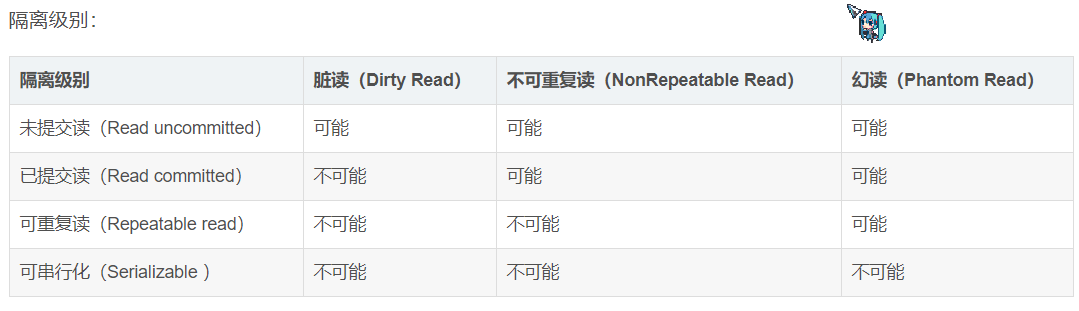
1. ISOLATION_DEFAULT: 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应
2. ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它允许另一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻读。
3. ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
4. ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
5. ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻读。
其中的一些概念的说明:
脏读: 指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,
那么另外一 个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。(指一个线程中的事务读取到了另外一个线程中未提交的数据。)
不可重复读: 指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。 那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
幻读: 指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及
到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
三、jdbc批量插入几百万数据怎么实现?
1. 使用mysql的存储过程来实现插入万条记录
DROP PROCEDURE IF EXISTS proc_initData;--如果存在此存储过程则删掉
DELIMITER $
CREATE PROCEDURE proc_initData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=100000 DO
INSERT INTO text VALUES(i,CONCAT('姓名',i),'XXXXXXXXX');
SET i = i+1;
END WHILE;
END $
CALL proc_initData();
花费时间很长:

2. JDBC往数据库中普通插入方式
先来说说JDBC往数据库中普通插入方式,简单的代码大致如下,循环了1000条,中间加点随机的数值,毕竟自己要拿数据测试,数据全都一样也不好区分
private String url = "jdbc:mysql://localhost:3306/test01";
private String user = "root";
private String password = "root";
@Test
public void Test(){
Connection conn = null;
PreparedStatement pstm =null;
ResultSet rt = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url, user, password);
String sql = "INSERT INTO userinfo(uid,uname,uphone,uaddress) VALUES(?,CONCAT('姓名',?),?,?)";
pstm = conn.prepareStatement(sql);
Long startTime = System.currentTimeMillis();
Random rand = new Random();
int a,b,c,d;
for (int i = 1; i <= 1000; i++) {
pstm.setInt(1, i);
pstm.setInt(2, i);
a = rand.nextInt(10);
b = rand.nextInt(10);
c = rand.nextInt(10);
d = rand.nextInt(10);
pstm.setString(3, "188"+a+"88"+b+c+"66"+d);
pstm.setString(4, "xxxxxxxxxx_"+"188"+a+"88"+b+c+"66"+d);27 pstm.executeUpdate();
}
Long endTime = System.currentTimeMillis();
System.out.println("OK,用时:" + (endTime - startTime));
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}finally{
if(pstm!=null){
try {
pstm.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
输出结果:OK,用时:738199,单位毫秒,也就是说这种方式与直接数据库中循环是差不多的。
在讨论批量处理之前,先说说遇到的坑,首先,JDBC连接的url中要加rewriteBatchedStatements参数设为true是批量操作的前提,其次就是检查mysql驱动包时候是5.1.13以上版本(低于该版本不支持),因网上随便下载了5.1.7版本的,然后执行批量操作(100W条插入),结果因为驱动器版本太低缘故并不支持,导致停止掉java程序后,mysql还在不断的往数据库中插入数据,最后不得不停止掉数据库服务才停下来...
那么低版本的驱动包是否对100W+数据插入就无力了呢?实际还有另外一种方式,效率相比来说还是可以接受的。
3. 使用事务提交方式
先将命令的提交方式设为false,即手动提交conn.setAutoCommit(false);最后在所有命令执行完之后再提交事务conn.commit();
private String url = "jdbc:mysql://localhost:3306/test01";
private String user = "root";
private String password = "123456";
@Test
public void Test(){
Connection conn = null;
PreparedStatement pstm =null;
ResultSet rt = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url, user, password);
String sql = "INSERT INTO userinfo(uid,uname,uphone,uaddress) VALUES(?,CONCAT('姓名',?),?,?)";
pstm = conn.prepareStatement(sql);
conn.setAutoCommit(false);
Long startTime = System.currentTimeMillis();
Random rand = new Random();
int a,b,c,d;
for (int i = 1; i <= 100000; i++) {
pstm.setInt(1, i);
pstm.setInt(2, i);
a = rand.nextInt(10);
b = rand.nextInt(10);
c = rand.nextInt(10);
d = rand.nextInt(10);
pstm.setString(3, "188"+a+"88"+b+c+"66"+d);
pstm.setString(4, "xxxxxxxxxx_"+"188"+a+"88"+b+c+"66"+d);
pstm.executeUpdate();
}
conn.commit();
Long endTime = System.currentTimeMillis();
System.out.println("OK,用时:" + (endTime - startTime));
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}finally{
if(pstm!=null){
try {
pstm.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
以上代码插入10W条数据,输出结果:OK,用时:18086,也就十八秒左右的时间,理论上100W也就是3分钟这样,勉强还可以接受。
4. 批量处理
接下来就是批量处理了,注意,一定要5.1.13以上版本的驱动包。
private String url = "jdbc:mysql://localhost:3306/test01?rewriteBatchedStatements=true";//注意url地址要加上rewriteBatchedStatements=true
private String user = "root";
private String password = "123456";
@Test
public void Test(){
Connection conn = null;
PreparedStatement pstm =null;
ResultSet rt = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url, user, password);
String sql = "INSERT INTO userinfo(uid,uname,uphone,uaddress) VALUES(?,CONCAT('姓名',?),?,?)";
pstm = conn.prepareStatement(sql);
conn.setAutoCommit(false);
Long startTime = System.currentTimeMillis();
Random rand = new Random();
int a,b,c,d;
for (int i = 1; i <= 100000; i++) {
pstm.setInt(1, i);
pstm.setInt(2, i);
a = rand.nextInt(10);
b = rand.nextInt(10);
c = rand.nextInt(10);
d = rand.nextInt(10);
pstm.setString(3, "188"+a+"88"+b+c+"66"+d);
pstm.setString(4, "xxxxxxxxxx_"+"188"+a+"88"+b+c+"66"+d);
pstm.addBatch();
}
pstm.executeBatch();
conn.commit();
Long endTime = System.currentTimeMillis();
System.out.println("OK,用时:" + (endTime - startTime));
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}finally{
if(pstm!=null){
try {
pstm.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
10W输出结果:OK,用时:3386,才3秒钟.
参考博客:https://www.cnblogs.com/fnz0/p/5713102.html
mysql分表,批量生成数据的更多相关文章
- mysql 分表与分区
一.操作环境 数据达到百w甚于更多的时候,我们的mysql查询将会变得比较慢, 如果再加上连表查询,程序可能会卡死.即使你设置了索引并在查询中使用到了索引,查询还是会慢.这时候你就要考虑怎么样来提高查 ...
- Java互联网架构-Mysql分库分表订单生成系统实战分析
概述 分库分表的必要性 首先我们来了解一下为什么要做分库分表.在我们的业务(web应用)中,关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量.连接数.处理能力等都很有限,数据库本身的“有状态性” ...
- Laravel 安装mysql、表增加模拟数据、生成控制器
参考中文网教程: 安装mysql.表增加模拟数据 http://www.golaravel.com/post/2016-ban-laravel-xi-lie-ru-men-jiao-cheng-yi/ ...
- 自由导入你的增量数据-根据条件将sqlserver表批量生成INSERT语句的存储过程实施笔记
文章标题: 自由导入你的增量数据-根据条件将sqlserver表批量生成INSERT语句的存储过程增强版 关键字 : mssql-scripter,SQL Server 文章分类: 技术分享 创建时间 ...
- 浅谈MySQL分表
关于分表:顾名思义就是一张数据量很大的表拆分成几个表分别进行存储. 我们先来大概了解以下一个数据库执行SQL的过程: 接收到SQL --> 放入SQL执行队列 --> 使用分析器分解SQL ...
- mysql分表操作
一般分表操作有垂直拆分和水平拆分.顾名思义. 1. 垂直拆分是指,这个表的列,即字段,要拆分成两个或多个表. 这个应用场景比如:这个表字段,几个都是int.datetime等,有那么一个是text类 ...
- mysql分表详解
经常听到有人说“数据表太大了,需要分表”,“xxxx了,要分表”的言论,那么,到底为什么要分表? 难道数据量大就要分表? mysql数据量对索引的影响 本人mysql版本为5.7 新增数据测试 为了测 ...
- mysql分表和表分区详解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- MySQL分表(Partition)学习研究报告
最近在开发一个新的项目,可能会产生大数据量,需要对部分表进行分表操作,故来研究学习MySQL的分表功能. 由于实验报告已经写成Exlce文件了,各位看过就直接下载吧:MySQL分表分析报告.xls 以 ...
- Mysql分表和分区的区别、分库分表介绍与区别
分表和分区的区别: 一,什么是mysql分表,分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表,具体请看:mysql分表的3种方法 什么是分区,分区呢就是把一张表的数据分成N多个区块,这 ...
随机推荐
- GO学习笔记 - map
map是GO语言中的一种高级数据类型,特点是key和value对应,这和Delphi中的Dictionary一样!map的声明格式:map[key数据类型]value数据类型.使用map前,必须用ma ...
- 利用jaxb实现xml和bean的相互转换
1.使用jar包生成xsd文件 java -jar trang.jar a.xml a.xsd xml格式 生成的xsd文件 2.使用xjc命令生成bean文件 xjc a.xsd 生成的相关bean ...
- jdk1.6 支持 tls1.2协议 并忽略身份验证
jdk1.6不支持tls1.2协议,jdk1.8默认支持,比较好的解决方案是升级jdk,但是升级jdk风险极大.不能升级jdk的情况下,可以使用如下方式. 引入依赖 <dependency> ...
- jquery源码解析:jQuery队列操作queue方法实现的原理
我们先来看一下jQuery中有关队列操作的方法集: 从上图可以看出,既有静态方法,又有实例方法.queue方法,相当于数组中的push操作.dequeue相当于数组的shift操作.举个例子: fun ...
- Nginx+Tomcat负载均衡群集
一.Nginx负载均衡原理 目前很多大型网站都应用Nginx服务器作为后端网站程序的反向代理及负载均衡器,提升整个站点的负载并发能力 Nginx负载均衡是通过反向代理实现的 二.部署Tomcat 本案 ...
- python+selenium 定位隐藏元素
定位隐藏要素的原理:页面主要通过“display:none”来控制元素不可见.所以我们需要通过javaScript修改display的值得值为display="block,来实现元素定位的. ...
- HDU-1087-Super Jumping! Jumping! Jumping!(线性DP, 最大上升子列和)
Super Jumping! Jumping! Jumping! Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 ...
- 队列的理解和实现(二) ----- 链队列(java实现)
什么是链队列 链队是指采用链式存储结构实现的队列,通常链队用单链表俩表示.一个链队显然需要两个分别指示队头和队尾的指针,也称为头指针和尾指针,有了这两个指针才能唯一的确定. package 链队列; ...
- 架构师养成记--16.disruptor并发框架中RingBuffer的使用
很多时候我们只需要消息中间件这样的功能,那么直需要RinBuffer就可以了. 入口: import java.util.concurrent.Callable; import java.util.c ...
- WampServer访问出现403forbidden的问题解决
1,软件装上以后出现所有服务运行,80端口未被占用的情况下服务器一直处于离线状态 解决方案如下: 网络上面很多教程多说切换服务器为在线状态即可,但是我发现我的菜单里面并没有,用命令又嫌麻烦 在图表上面 ...