Learning Query and Document Similarities from Click-through Bipartite Graph with Metadata
读了一篇paper,MSRA的Wei Wu的一篇《Learning Query and Document Similarities from Click-through Bipartite Graph with Metadata》。是关于Ranking Relevence方面的文章。下面简单讲下我对这篇文章的理解,对这方面感兴趣的小伙伴们可以交流一下。
1. Abstract
这篇文章的重点在于使用query-doc的点击二部图,结合query/doc的meta数据(组织成multiple types of features),来学习出query-doc(顺带介绍了query-query,doc-doc)的similarity。
为了计算上述的similarity,作者采用了两个不同的linear mappings,用来把query从query feature space,把doc从doc feature space映射到相同的latent space上,然后便可通过计算这个latent space上两者的vector的dot product来获得两者的similarity。于是,便把对similarity的learning形式化为对mapping的learning,而这个mapping的learning的目标是为了maximize从enriched click-through bipartite gragh上观察到的query-doc的similarity(可以通过query-doc pair的点击数来衡量)。另外,这个linear mapping是针对一种类型的features,获得一种类型features的similarity function,如果有multiple types of features的话,则最终的similarity function是每个type的similarity function的线性组合。
learning过程用到的算法包括Singular Value Decomposition(SVD)和Multi-view Partial Least Squares(M-PLS)。
2. Introduction
作者提到了先前的关于计算query-doc similarity的几种方法。
1)feature based methods:Vector Space Model(VSM),BM25,Language Models for Information Retrieval(LMIR)等。
2)gragh based methods:mining query-doc similarity from a click-through bipartite gragh等。
而这篇文章是将两者结合起来:
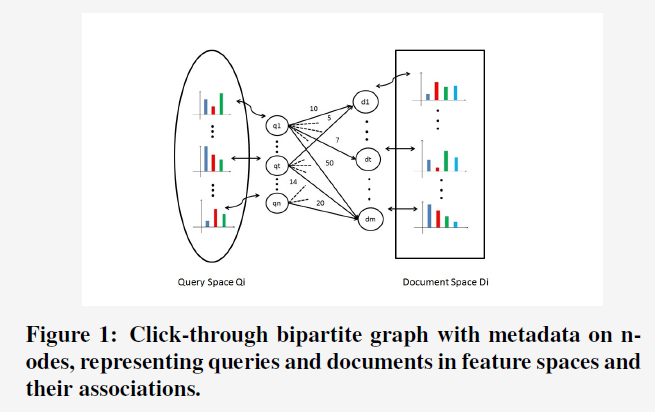
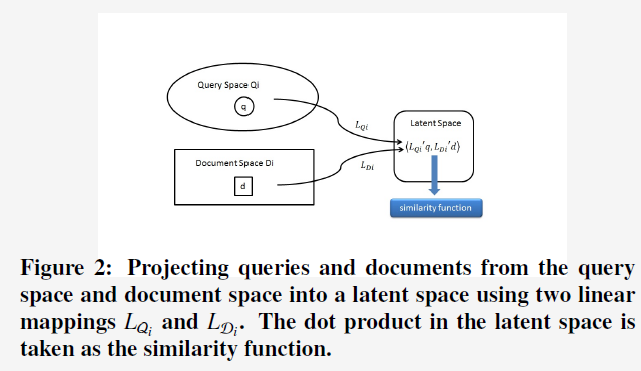
3. Problem Formulation
将每种type的features的query或者document用一个向量的形式来表示,,则linear mapping可以看做是维度为 和
和 的两种形式的矩阵(
的两种形式的矩阵(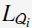 和
和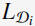 ),通过这两种变换矩阵,query或者doc在原始空间上的向量被变换成latent space上的维度为
),通过这两种变换矩阵,query或者doc在原始空间上的向量被变换成latent space上的维度为 的向量
的向量 和
和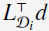 。于是,对于这种type的faetures,simialrity function表示为
。于是,对于这种type的faetures,simialrity function表示为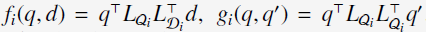 。我们可以将点击二部图中query-doc的点击数看作是query-doc similarity的大小,而通过maximize观察到的query-doc的similarity来学习linear mapping
。我们可以将点击二部图中query-doc的点击数看作是query-doc similarity的大小,而通过maximize观察到的query-doc的similarity来学习linear mapping 和线性加权的权重
和线性加权的权重 。
。
最终的learning problem可以表示为:
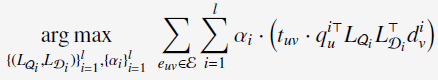
这时候有个问题,就是需要最大化的公式的值是可以无限大的,因为没有系数的限制,下面会介绍如何在系数上加上constraints。
4. Multi-view Partial Least Squares
4.1 Constrained Optimization Problem
1)对feature vectors进行归一化: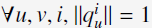 ,
,
2)对mapping matrices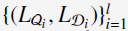 进行正交化限制。
进行正交化限制。
3)对线性加权权重 进行L2 正则化限制。
进行L2 正则化限制。
于是,learning method重新形式化为:
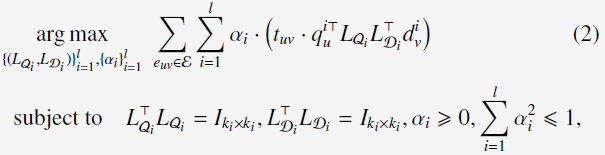
4.2 Globally Optimal Solution
为了获得全局最优解,两步走。第一步,对每种type的features,通过SVD求解得到optimal linear mapping;第二步,求解optimal combination weights。
上述的公式(2)可以重写为:
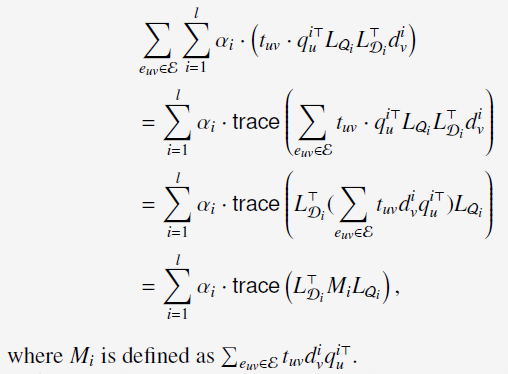
optimization problem为:
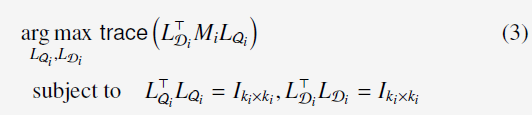
通过SVD求得global optimal solution。

于是,公式(2)可以写成:
而combination weights求解为:
4.3 Learning Algorithm
1)for each type of feature,solves SVD of Mi to learn the linear mapping。
2)calculates the combination weights using (5)。

版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
Learning Query and Document Similarities from Click-through Bipartite Graph with Metadata的更多相关文章
- 关于IOS浏览器:document,body的click事件触发规则
今天做了个手机页面,点击某个按钮->弹出菜单,再点击菜单以外的任意位置->关闭菜单,在其他浏览器里面没有问题,但是在IOS浏览器中并不会关闭. 网上解决这个bug的帖子很多,这篇帖子主要是 ...
- (八)Index and Query a Document
Let’s now put something into our customer index. We’ll index a simple customer document into the cus ...
- 深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition
作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner 这篇论文内容较多,这里只对部分内容进行记录: 以下是对论文原文的翻译: 在传统 ...
- Gradient-Based Learning Applied to Document Recognition 部分阅读
卷积网络 卷积网络用三种结构来确保移位.尺度和旋转不变:局部感知野.权值共享和时间或空间降采样.典型的leNet-5如下图所示: C1中每个特征图的每个单元和输入的25个点相连,这个5* ...
- 计算广告(5)----query意图识别
目录: 一.简介: 1.用户意图识别概念 2.用户意图识别难点 3.用户意图识别分类 4.意图识别方法: (1)基于规则 (2)基于穷举 (3)基于分类模型 二.意图识别具体做法: 1.数据集 2.数 ...
- 使用点击二分图计算query-document的相关性
之前的博客中已经介绍了Ranking Relevance的一些基本情况(Click Behavior,和Text Match):http://www.cnblogs.com/bentuwuying/p ...
- 使用点击二分图传导计算query-document的相关性
之前的博客中已经介绍了Ranking Relevance的一些基本情况(Click Behavior,和Text Match):http://www.cnblogs.com/bentuwuying/p ...
- Awesome Deep Vision
Awesome Deep Vision A curated list of deep learning resources for computer vision, inspired by awes ...
- learning to rank
Learning to Rank入门小结 + 漫谈 Learning to Rank入门小结 Table of Contents 1 前言 2 LTR流程 3 训练数据的获取4 特征抽取 3.1 人工 ...
随机推荐
- storm中的基本概念
Storm是一个流计算框架,处理的数据是实时消息队列中的,所以需要我们写好一个topology逻辑放在那,接收进来的数据来处理,所以是通过移动数据平均分配到机器资源来获得高效率. Storm的优点是全 ...
- round()
round() 用于对一个数值进行四舍五入,如果接收两个参数,则第二个参数表示保留多少位小数 In [1]: round(1.5324) Out[1]: 2.0 In [2]: round(1.532 ...
- 第六篇:GPU 并行优化的几种典型策略
前言 如何对现有的程序进行并行优化,是 GPU 并行编程技术最为关注的实际问题.本文将提供几种优化的思路,为程序并行优化指明道路方向. 优化前准备 首先,要明确优化的目标 - 是要将程序提速 2 倍? ...
- PHP之命名空间
前面的话 从广义上来说,命名空间是一种封装事物的方法.在很多地方都可以见到这种抽象概念.例如,在操作系统中目录用来将相关文件分组,对于目录中的文件来说,它就扮演了命名空间的角色.这个原理应用到程序设计 ...
- vue中npm install 报错之一
报错原因: 这是因为文件phantomjs-2.1.1-windows.zip过大,网络不好,容易下载失败 PhantomJS not found on PATH 解决方案一: 选择用cnpm ins ...
- 删除编辑文件警告Swap file “…” already exists!
Linux下多个用户同时编辑一个文件,或编辑时非正常关闭,再下次编辑打开文件时均为显示如下警告信息: Swap file "test.xml.swp" already exists ...
- IPMI相关漏洞利用及WEB端默认口令登录漏洞
IPMI相关漏洞 0套件漏洞 使用0套件时,只需要Username,口令任意即可绕过身份鉴别执行指令.而且一般还有一个默认的账户admin或者ADMIN. 备注:IPMI是一套主机远程管理系统,可以远 ...
- 代码片段,lucene基本操作(基于lucene4.10.2)
1.最基本的创建索引: @Test public void testIndex(){ try { Directory directory = FSDirectory.open(new File(LUC ...
- 微信小程序 --- page.json文件
page.json 文件用于配置当前目录.page.json文件里的配置可以修改 app.json 配置里面的 window:不能覆盖app.json文件里面的 tabBar / 网络超时/ debu ...
- java使用poi解析或处理excel的时候,如何防止数字变成科学计数法的形式和其他常见Excel中数据转换问题
当使用POI处理excel的时候,遇到了比较长的数字,虽然excel里面设置该单元格是文本类型的,但是POI的cell的类型就会变成数字类型. 而且无论数字是否小数,使用cell.getNumberi ...