Django - ORM - 进阶
一、多表操作
创建模型
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:
from django.db import models # Create your models here. class Author(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField() # 与AuthorDetail建立一对一的关系
authorDetail=models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64) class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField() class Book(models.Model): nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2) # 与Publish建立一对多的关系,外键字段建立在多的一方
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE)
# 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表
authors=models.ManyToManyField(to='Author',)
生成表如下:
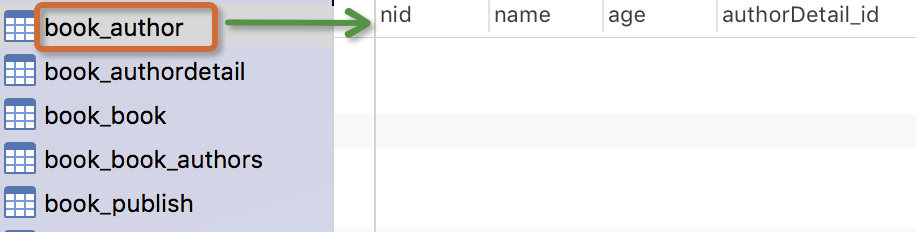

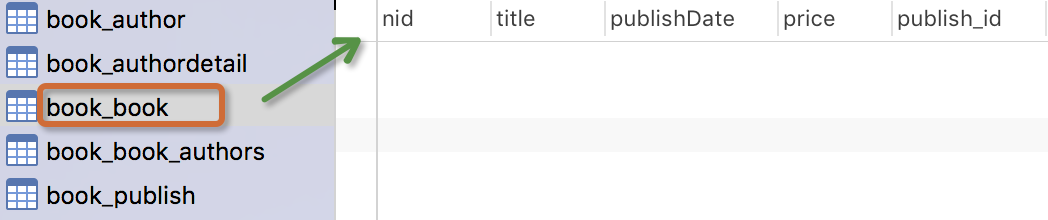
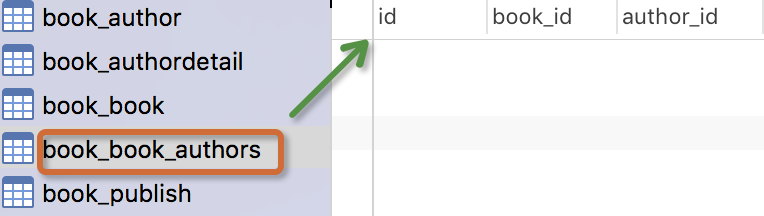
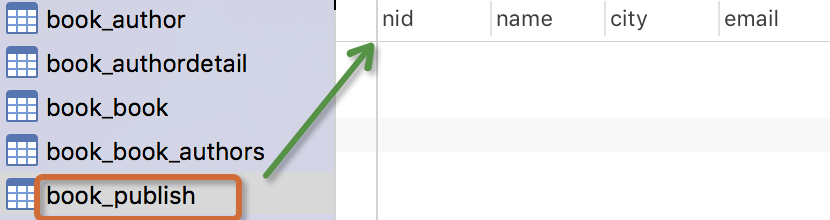
注意事项:
- 表的名称
myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称 id字段是自动添加的- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的
CREATE TABLESQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
添加表记录
操作前先简单的录入一些数据:
publish表:

author表:
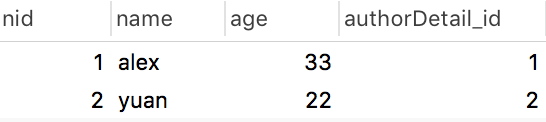
authordetail表:
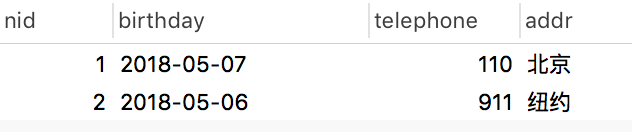
一对多
|
1
2
3
4
5
6
|
方式1: publish_obj=Publish.objects.get(nid=1) book_obj=Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=100,publish=publish_obj) 方式2: book_obj=Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=100,publish_id=1) |

核心:book_obj.publish与book_obj.publish_id是什么?
多对多

# 当前生成的书籍对象
book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)
# 为书籍绑定的做作者对象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录
egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录 # 绑定多对多关系,即向关系表book_authors中添加纪录
book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
数据库表纪录生成如下:
book表

book_authors表

核心:book_obj.authors.all()是什么?
多对多关系其它常用API:
|
1
2
3
|
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])book_obj.authors.clear() #清空被关联对象集合book_obj.authors.set() #先清空再设置 |
二、基于对象的跨表查询
一对多查询(Publish与Book)
正向查询(按字段:publish):
|
1
2
3
4
|
# 查询主键为1的书籍的出版社所在的城市book_obj=Book.objects.filter(pk=1).first()# book_obj.publish 是主键为1的书籍对象关联的出版社对象 print(book_obj.publish.city) |
反向查询(按表名:book_set):
|
1
2
3
4
5
|
publish=Publish.objects.get(name="苹果出版社") #publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合book_list=publish.book_set.all() for book_obj in book_list: print(book_obj.title) |
一对一查询(Author与AuthorDetail)
正向查询(按字段:authorDetail):
|
1
2
|
egon=Author.objects.filter(name="egon").first()print(egon.authorDetail.telephone) |
反向查询(按表名:author):
|
1
2
3
4
5
|
# 查询所有住址在北京的作者的姓名authorDetail_list=AuthorDetail.objects.filter(addr="beijing")for obj in authorDetail_list: print(obj.author.name) |
多对多查询(Author与Book)
正向查询(按字段:authors):
|
1
2
3
4
5
6
|
# 金瓶眉所有作者的名字以及手机号book_obj=Book.objects.filter(title="金瓶眉").first()authors=book_obj.authors.all()for author_obj in authors: print(author_obj.name,author_obj.authorDetail.telephone) |
反向查询(按表名:book_set):
|
1
2
3
4
5
6
|
# 查询egon出过的所有书籍的名字 author_obj=Author.objects.get(name="egon") book_list=author_obj.book_set.all() #与egon作者相关的所有书籍 for book_obj in book_list: print(book_obj.title) |
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改:
|
1
|
publish = ForeignKey(Book, related_name='bookList') |
那么接下来就会如我们看到这般:
|
1
2
3
4
|
# 查询 人民出版社出版过的所有书籍publish=Publish.objects.get(name="人民出版社")book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合 |
三、基于双下划的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
''' 正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表 '''
一对一查询
# 查询alex的手机号
# 正向查询
ret=Author.objects.filter(name="alex").values("authordetail__telephone")
# 反向查询
ret=AuthorDetail.objects.filter(author__name="alex").values("telephone")
一对多查询
# 练习: 查询苹果出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="苹果出版社")
.values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="苹果出版社")
.values_list("book__title","book__price")
多对多查询
# 练习: 查询alex出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")
进阶练习(连续跨表)
# 练习: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__authors__age","book__authors__name")
# 练习: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
# 方式1:
queryResult=Book.objects
.filter(authors__authorDetail__telephone__regex="")
.values_list("title","publish__name")
# 方式2:
ret=Author.objects
.filter(authordetail__telephone__startswith="")
.values("book__title","book__publish__name")
related_name
反向查询时,如果定义了related_name ,则用related_name替换表名,例如:
publish = ForeignKey(Blog, related_name='bookList')
# 练习: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price")
四、聚合查询与分组查询
聚合
aggregate(*args, **kwargs)
|
1
2
3
4
|
# 计算所有图书的平均价格 >>> from django.db.models import Avg >>> Book.objects.all().aggregate(Avg('price')) {'price__avg': 34.35} |
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
|
1
2
|
>>> Book.objects.aggregate(average_price=Avg('price')){'average_price': 34.35} |
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
|
1
2
3
|
>>> from django.db.models import Avg, Max, Min>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')){'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')} |
分组
###################################--单表分组查询--####################################################### 查询每一个部门名称以及对应的员工数 emp: id name age salary dep
alex 12 2000 销售部
egon 22 3000 人事部
wen 22 5000 人事部 sql语句:
select dep,Count(*) from emp group by dep; ORM:
emp.objects.values("dep").annotate(c=Count("id") ###################################--多表分组查询--########################### 多表分组查询: 查询每一个部门名称以及对应的员工数 emp: id name age salary dep_id
alex 12 2000 1
egon 22 3000 2
wen 22 5000 2 dep id name
销售部
人事部 emp-dep: id name age salary dep_id id name
alex 12 2000 1 1 销售部
egon 22 3000 2 2 人事部
wen 22 5000 2 2 人事部 sql语句:
select dep.name,Count(*) from emp left join dep on emp.dep_id=dep.id group by dep.id ORM:
dep.objetcs.values("id").annotate(c=Count("emp")).values("name","c")
class Emp(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
salary=models.DecimalField(max_digits=8,decimal_places=2)
dep=models.CharField(max_length=32)
province=models.CharField(max_length=32)
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
查询练习
(1) 练习:统计每一个出版社的最便宜的书
|
1
2
3
|
publishList=Publish.objects.annotate(MinPrice=Min("book__price"))for publish_obj in publishList: print(publish_obj.name,publish_obj.MinPrice) |
annotate的返回值是querySet,如果不想遍历对象,可以用上valuelist:
queryResult= Publish.objects
.annotate(MinPrice=Min("book__price"))
.values_list("name","MinPrice")
print(queryResult)
'''
SELECT "app01_publish"."name", MIN("app01_book"."price") AS "MinPrice" FROM "app01_publish"
LEFT JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id")
GROUP BY "app01_publish"."nid", "app01_publish"."name", "app01_publish"."city", "app01_publish"."email"
(2) 练习:统计每一本书的作者个数
ret=Book.objects.annotate(authorsNum=Count('authors__name'))
(3) 统计每一本以py开头的书籍的作者个数:
queryResult=Book.objects
.filter(title__startswith="Py")
.annotate(num_authors=Count('authors'))
(4) 统计不止一个作者的图书:
queryResult=Book.objects
.annotate(num_authors=Count('authors'))
.filter(num_authors__gt=1)
(5) 根据一本图书作者数量的多少对查询集 QuerySet进行排序:
|
1
|
Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors') |
(6) 查询各个作者出的书的总价格:
# 按author表的所有字段 group by
queryResult=Author.objects
.annotate(SumPrice=Sum("book__price"))
.values_list("name","SumPrice")
print(queryResult)
五、F查询与Q查询(F更新数据库得字段,Q构造复杂条件)
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
|
1
2
3
4
|
# 查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commnetNum__lt=F('keepNum')) |
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
|
1
2
|
# 查询评论数大于收藏数2倍的书籍 Book.objects.filter(commnetNum__lt=F('keepNum')*2) |
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
|
1
|
Book.objects.all().update(price=F("price")+30) |
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
|
1
2
|
from django.db.models import QQ(title__startswith='Py') |
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
|
1
|
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon")) |
等同于下面的SQL WHERE 子句:
|
1
|
WHERE name ="yuan" OR name ="egon" |
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
|
1
|
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title") |
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
|
1
2
3
|
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017), title__icontains="python" ) |
# 查询是字段名称
# Book.objects.filter(Q(title='yuan')|Q(price='123')) # Q() 查询放str,search_connection = Q()
search_connection.connector = 'or'
for search_field in self.search_fields:
search_connection.children.append((search_field,key_words)) data_list = self.model.objects.all().filter(search_connection)
六、QuerySet
可切片
使用Python 的切片语法来限制查询集记录的数目 。它等同于SQL 的LIMIT 和OFFSET 子句。
|
1
|
>>> Entry.objects.all()[:5] # (LIMIT 5) |
>>> Entry.objects.all()[5:10] # (OFFSET 5 LIMIT 5)
不支持负的索引(例如Entry.objects.all()[-1])。通常,查询集 的切片返回一个新的查询集 —— 它不会执行查询。
可迭代
articleList=models.Article.objects.all() for article in articleList:
print(article.title)
惰性查询
查询集 是惰性执行的 —— 创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整天,直到查询集 需要求值时,Django 才会真正运行这个查询。
|
1
2
3
4
5
6
|
queryResult=models.Article.objects.all() # not hits databaseprint(queryResult) # hits databasefor article in queryResult: print(article.title) # hits database |
一般来说,只有在“请求”查询集 的结果时才会到数据库中去获取它们。当你确实需要结果时,查询集 通过访问数据库来求值。
缓存机制
每个查询集都包含一个缓存来最小化对数据库的访问。理解它是如何工作的将让你编写最高效的代码。
在一个新创建的查询集中,缓存为空。首次对查询集进行求值 —— 同时发生数据库查询 ——Django 将保存查询的结果到查询集的缓存中并返回明确请求的结果(例如,如果正在迭代查询集,则返回下一个结果)。接下来对该查询集 的求值将重用缓存的结果。
请牢记这个缓存行为,因为对查询集使用不当的话,它会坑你的。例如,下面的语句创建两个查询集,对它们求值,然后扔掉它们:
|
1
2
|
print([a.title for a in models.Article.objects.all()])print([a.create_time for a in models.Article.objects.all()]) |
这意味着相同的数据库查询将执行两次,显然倍增了你的数据库负载。同时,还有可能两个结果列表并不包含相同的数据库记录,因为在两次请求期间有可能有Article被添加进来或删除掉。为了避免这个问题,只需保存查询集并重新使用它:
|
1
2
3
|
queryResult=models.Article.objects.all()print([a.title for a in queryResult])print([a.create_time for a in queryResult]) |
何时查询集不会被缓存?
查询集不会永远缓存它们的结果。当只对查询集的部分进行求值时会检查缓存, 如果这个部分不在缓存中,那么接下来查询返回的记录都将不会被缓存。所以,这意味着使用切片或索引来限制查询集将不会填充缓存。
例如,重复获取查询集对象中一个特定的索引将每次都查询数据库:
|
1
2
3
|
>>> queryset = Entry.objects.all()>>> print queryset[5] # Queries the database>>> print queryset[5] # Queries the database again |
然而,如果已经对全部查询集求值过,则将检查缓存:
|
1
2
3
4
|
>>> queryset = Entry.objects.all()>>> [entry for entry in queryset] # Queries the database>>> print queryset[5] # Uses cache>>> print queryset[5] # Uses cache |
下面是一些其它例子,它们会使得全部的查询集被求值并填充到缓存中:
|
1
2
3
4
|
>>> [entry for entry in queryset]>>> bool(queryset)>>> entry in queryset>>> list(queryset) |
注:简单地打印查询集不会填充缓存。
queryResult=models.Article.objects.all()(queryResult)# hits database(queryResult)# hits database
exists()与iterator()方法
exists:
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些 数据!为了避免这个,可以用exists()方法来检查是否有数据:
if queryResult.exists():
#SELECT (1) AS "a" FROM "blog_article" LIMIT 1; args=()
print("exists...")
iterator:
当queryset非常巨大时,cache会成为问题。
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统 进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法 来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
# iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.title)
#BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了
for obj in objs:
print(obj.title)
当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使 #用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询。
总结:
queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。 使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能 会造成额外的数据库查询。
七、中介模型
处理类似搭配 pizza 和 topping 这样简单的多对多关系时,使用标准的ManyToManyField 就可以了。但是,有时你可能需要关联数据到两个模型之间的关系上。
例如,有这样一个应用,它记录音乐家所属的音乐小组。我们可以用一个ManyToManyField 表示小组和成员之间的多对多关系。但是,有时你可能想知道更多成员关系的细节,比如成员是何时加入小组的。
对于这些情况,Django 允许你指定一个中介模型来定义多对多关系。 你可以将其他字段放在中介模型里面。源模型的ManyToManyField 字段将使用through 参数指向中介模型。对于上面的音乐小组的例子,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from django.db import modelsclass Person(models.Model): name = models.CharField(max_length=128) def __str__(self): # __unicode__ on Python 2 return self.nameclass Group(models.Model): name = models.CharField(max_length=128) members = models.ManyToManyField(Person, through='Membership') def __str__(self): # __unicode__ on Python 2 return self.nameclass Membership(models.Model): person = models.ForeignKey(Person) group = models.ForeignKey(Group) date_joined = models.DateField() invite_reason = models.CharField(max_length=64) |
既然你已经设置好ManyToManyField 来使用中介模型(在这个例子中就是Membership),接下来你要开始创建多对多关系。你要做的就是创建中介模型的实例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
>>> ringo = Person.objects.create(name="Ringo Starr")>>> paul = Person.objects.create(name="Paul McCartney")>>> beatles = Group.objects.create(name="The Beatles")>>> m1 = Membership(person=ringo, group=beatles,... date_joined=date(1962, 8, 16),... invite_reason="Needed a new drummer.")>>> m1.save()>>> beatles.members.all()[<Person: Ringo Starr>]>>> ringo.group_set.all()[<Group: The Beatles>]>>> m2 = Membership.objects.create(person=paul, group=beatles,... date_joined=date(1960, 8, 1),... invite_reason="Wanted to form a band.")>>> beatles.members.all()[<Person: Ringo Starr>, <Person: Paul McCartney>] |
与普通的多对多字段不同,你不能使用add、 create和赋值语句(比如,beatles.members = [...])来创建关系:
|
1
2
3
4
5
6
|
# THIS WILL NOT WORK>>> beatles.members.add(john)# NEITHER WILL THIS>>> beatles.members.create(name="George Harrison")# AND NEITHER WILL THIS>>> beatles.members = [john, paul, ringo, george] |
为什么不能这样做? 这是因为你不能只创建 Person和 Group之间的关联关系,你还要指定 Membership模型中所需要的所有信息;而简单的add、create 和赋值语句是做不到这一点的。所以它们不能在使用中介模型的多对多关系中使用。此时,唯一的办法就是创建中介模型的实例。
remove()方法被禁用也是出于同样的原因。但是clear() 方法却是可用的。它可以清空某个实例所有的多对多关系:
|
1
2
3
4
5
|
>>> # Beatles have broken up>>> beatles.members.clear()>>> # Note that this deletes the intermediate model instances>>> Membership.objects.all()[] |
八、查询优化
表数据
class UserInfo(AbstractUser):
"""
用户信息
"""
nid = models.BigAutoField(primary_key=True)
nickname = models.CharField(verbose_name='昵称', max_length=32)
telephone = models.CharField(max_length=11, blank=True, null=True, unique=True, verbose_name='手机号码')
avatar = models.FileField(verbose_name='头像',upload_to = 'avatar/',default="/avatar/default.png")
create_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) fans = models.ManyToManyField(verbose_name='粉丝们',
to='UserInfo',
through='UserFans',
related_name='f',
through_fields=('user', 'follower')) def __str__(self):
return self.username class UserFans(models.Model):
"""
互粉关系表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey(verbose_name='博主', to='UserInfo', to_field='nid', related_name='users')
follower = models.ForeignKey(verbose_name='粉丝', to='UserInfo', to_field='nid', related_name='followers') class Blog(models.Model): """
博客信息
"""
nid = models.BigAutoField(primary_key=True)
title = models.CharField(verbose_name='个人博客标题', max_length=64)
site = models.CharField(verbose_name='个人博客后缀', max_length=32, unique=True)
theme = models.CharField(verbose_name='博客主题', max_length=32)
user = models.OneToOneField(to='UserInfo', to_field='nid')
def __str__(self):
return self.title class Category(models.Model):
"""
博主个人文章分类表
"""
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name='分类标题', max_length=32) blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid') class Article(models.Model): nid = models.BigAutoField(primary_key=True)
title = models.CharField(max_length=50, verbose_name='文章标题')
desc = models.CharField(max_length=255, verbose_name='文章描述')
read_count = models.IntegerField(default=0)
comment_count= models.IntegerField(default=0)
up_count = models.IntegerField(default=0)
down_count = models.IntegerField(default=0)
category = models.ForeignKey(verbose_name='文章类型', to='Category', to_field='nid', null=True)
create_time = models.DateField(verbose_name='创建时间')
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid')
tags = models.ManyToManyField(
to="Tag",
through='Article2Tag',
through_fields=('article', 'tag'),
) class ArticleDetail(models.Model):
"""
文章详细表
"""
nid = models.AutoField(primary_key=True)
content = models.TextField(verbose_name='文章内容', ) article = models.OneToOneField(verbose_name='所属文章', to='Article', to_field='nid') class Comment(models.Model):
"""
评论表
"""
nid = models.BigAutoField(primary_key=True)
article = models.ForeignKey(verbose_name='评论文章', to='Article', to_field='nid')
content = models.CharField(verbose_name='评论内容', max_length=255)
create_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) parent_comment = models.ForeignKey('self', blank=True, null=True, verbose_name='父级评论')
user = models.ForeignKey(verbose_name='评论者', to='UserInfo', to_field='nid') up_count = models.IntegerField(default=0) def __str__(self):
return self.content class ArticleUpDown(models.Model):
"""
点赞表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey('UserInfo', null=True)
article = models.ForeignKey("Article", null=True)
models.BooleanField(verbose_name='是否赞') class CommentUp(models.Model):
"""
点赞表
"""
nid = models.AutoField(primary_key=True)
user = models.ForeignKey('UserInfo', null=True)
comment = models.ForeignKey("Comment", null=True) class Tag(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name='标签名称', max_length=32)
blog = models.ForeignKey(verbose_name='所属博客', to='Blog', to_field='nid') class Article2Tag(models.Model):
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(verbose_name='文章', to="Article", to_field='nid')
tag = models.ForeignKey(verbose_name='标签', to="Tag", to_field='nid')
select_related
简单使用
对于一对一字段(OneToOneField)和外键字段(ForeignKey),可以使用select_related 来对QuerySet进行优化。
select_related 返回一个QuerySet,当执行它的查询时它沿着外键关系查询关联的对象的数据。它会生成一个复杂的查询并引起性能的损耗,但是在以后使用外键关系时将不需要数据库查询。
简单说,在对QuerySet使用select_related()函数后,Django会获取相应外键对应的对象,从而在之后需要的时候不必再查询数据库了。
下面的例子解释了普通查询和select_related() 查询的区别。
查询id=2的文章的分类名称,下面是一个标准的查询:
|
1
2
3
4
5
|
# Hits the database.article=models.Article.objects.get(nid=2)# Hits the database again to get the related Blog object.print(article.category.title) |
''' SELECT
"blog_article"."nid",
"blog_article"."title",
"blog_article"."desc",
"blog_article"."read_count",
"blog_article"."comment_count",
"blog_article"."up_count",
"blog_article"."down_count",
"blog_article"."category_id",
"blog_article"."create_time",
"blog_article"."blog_id",
"blog_article"."article_type_id"
FROM "blog_article"
WHERE "blog_article"."nid" = 2; args=(2,) SELECT
"blog_category"."nid",
"blog_category"."title",
"blog_category"."blog_id"
FROM "blog_category"
WHERE "blog_category"."nid" = 4; args=(4,) '''
如果我们使用select_related()函数:
|
1
2
3
4
5
6
7
|
articleList=models.Article.objects.select_related("category").all() for article_obj in articleList: # Doesn't hit the database, because article_obj.category # has been prepopulated in the previous query. print(article_obj.category.title) |
SELECT
"blog_article"."nid",
"blog_article"."title",
"blog_article"."desc",
"blog_article"."read_count",
"blog_article"."comment_count",
"blog_article"."up_count",
"blog_article"."down_count",
"blog_article"."category_id",
"blog_article"."create_time",
"blog_article"."blog_id",
"blog_article"."article_type_id", "blog_category"."nid",
"blog_category"."title",
"blog_category"."blog_id" FROM "blog_article"
LEFT OUTER JOIN "blog_category" ON ("blog_article"."category_id" = "blog_category"."nid");
多外键查询
这是针对category的外键查询,如果是另外一个外键呢?让我们一起看下:
|
1
2
|
article=models.Article.objects.select_related("category").get(nid=1)print(article.articledetail) |
观察logging结果,发现依然需要查询两次,所以需要改为:
|
1
2
|
article=models.Article.objects.select_related("category","articledetail").get(nid=1)print(article.articledetail) |
或者:
article=models.Article.objects
.select_related("category")
.select_related("articledetail")
.get(nid=1) # django 1.7 支持链式操作
print(article.articledetail)
SELECT
"blog_article"."nid",
"blog_article"."title",
......
"blog_category"."nid",
"blog_category"."title",
"blog_category"."blog_id",
"blog_articledetail"."nid",
"blog_articledetail"."content",
"blog_articledetail"."article_id"
FROM "blog_article"
LEFT OUTER JOIN "blog_category" ON ("blog_article"."category_id" = "blog_category"."nid")
LEFT OUTER JOIN "blog_articledetail" ON ("blog_article"."nid" = "blog_articledetail"."article_id")
WHERE "blog_article"."nid" = 1; args=(1,)
深层查询
|
1
2
3
4
|
# 查询id=1的文章的用户姓名 article=models.Article.objects.select_related("blog").get(nid=1) print(article.blog.user.username) |
依然需要查询两次:
SELECT
"blog_article"."nid",
"blog_article"."title",
...... "blog_blog"."nid",
"blog_blog"."title", FROM "blog_article" INNER JOIN "blog_blog" ON ("blog_article"."blog_id" = "blog_blog"."nid")
WHERE "blog_article"."nid" = 1; SELECT
"blog_userinfo"."password",
"blog_userinfo"."last_login",
...... FROM "blog_userinfo"
WHERE "blog_userinfo"."nid" = 1;
这是因为第一次查询没有query到userInfo表,所以,修改如下:
|
1
2
|
article=models.Article.objects.select_related("blog__user").get(nid=1)print(article.blog.user.username) |
SELECT "blog_article"."nid", "blog_article"."title",
...... "blog_blog"."nid", "blog_blog"."title",
...... "blog_userinfo"."password", "blog_userinfo"."last_login",
...... FROM "blog_article" INNER JOIN "blog_blog" ON ("blog_article"."blog_id" = "blog_blog"."nid") INNER JOIN "blog_userinfo" ON ("blog_blog"."user_id" = "blog_userinfo"."nid")
WHERE "blog_article"."nid" = 1;
总结
- select_related主要针一对一和多对一关系进行优化。
- select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
- 可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询。
- 没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
- 也可以通过depth参数指定递归的深度,Django会自动缓存指定深度内所有的字段。如果要访问指定深度外的字段,Django会再次进行SQL查询。
- 也接受无参数的调用,Django会尽可能深的递归查询所有的字段。但注意有Django递归的限制和性能的浪费。
- Django >= 1.7,链式调用的select_related相当于使用可变长参数。Django < 1.7,链式调用会导致前边的select_related失效,只保留最后一个。
prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。
|
1
2
3
4
5
|
# 查询所有文章关联的所有标签 article_obj=models.Article.objects.all() for i in article_obj: print(i.tags.all()) #4篇文章: hits database 5 |
改为prefetch_related:
|
1
2
3
4
5
|
# 查询所有文章关联的所有标签 article_obj=models.Article.objects.prefetch_related("tags").all() for i in article_obj: print(i.tags.all()) #4篇文章: hits database 2 |
SELECT "blog_article"."nid",
"blog_article"."title",
...... FROM "blog_article"; SELECT
("blog_article2tag"."article_id") AS "_prefetch_related_val_article_id",
"blog_tag"."nid",
"blog_tag"."title",
"blog_tag"."blog_id"
FROM "blog_tag"
INNER JOIN "blog_article2tag" ON ("blog_tag"."nid" = "blog_article2tag"."tag_id")
WHERE "blog_article2tag"."article_id" IN (1, 2, 3, 4);
九、extra
extra(select=None, where=None, params=None,
tables=None, order_by=None, select_params=None)
有些情况下,Django的查询语法难以简单的表达复杂的 WHERE 子句,对于这种情况, Django 提供了 extra() QuerySet修改机制 — 它能在 QuerySet生成的SQL从句中注入新子句
extra可以指定一个或多个 参数,例如 select, where or tables. 这些参数都不是必须的,但是你至少要使用一个!要注意这些额外的方式对不同的数据库引擎可能存在移植性问题.(因为你在显式的书写SQL语句),除非万不得已,尽量避免这样做
参数之select
The select 参数可以让你在 SELECT 从句中添加其他字段信息,它应该是一个字典,存放着属性名到 SQL 从句的映射。
queryResult=models.Article
.objects.extra(select={'is_recent': "create_time > '2017-09-05'"})
结果集中每个 Entry 对象都有一个额外的属性is_recent, 它是一个布尔值,表示 Article对象的create_time 是否晚于2017-09-05.
练习:
# in sqlite:
article_obj=models.Article.objects
.filter(nid=1)
.extra(select={"standard_time":"strftime('%%Y-%%m-%%d',create_time)"})
.values("standard_time","nid","title")
print(article_obj)
# <QuerySet [{'title': 'MongoDb 入门教程', 'standard_time': '2017-09-03', 'nid': 1}]>
参数之where / tables
您可以使用where定义显式SQL WHERE子句 - 也许执行非显式连接。您可以使用tables手动将表添加到SQL FROM子句。
where和tables都接受字符串列表。所有where参数均为“与”任何其他搜索条件。
举例来讲:
queryResult=models.Article
.objects.extra(where=['nid in (1,3) OR title like "py%" ','nid>2'])
十、整体插入
创建对象时,尽可能使用bulk_create()来减少SQL查询的数量。例如:
Entry.objects.bulk_create([
Entry(headline="Python 3.0 Released"),
Entry(headline="Python 3.1 Planned")
])
...更优于:
Entry.objects.create(headline="Python 3.0 Released")
Entry.objects.create(headline="Python 3.1 Planned")
注意该方法有很多注意事项,所以确保它适用于你的情况。
这也可以用在ManyToManyFields中,所以:
my_band.members.add(me, my_friend)
...更优于:
my_band.members.add(me)
my_band.members.add(my_friend)
...其中Bands和Artists具有多对多关联。
https://www.cnblogs.com/yuanchenqi/articles/8963244.html
https://www.cnblogs.com/yuanchenqi/articles/7570003.htm
十一、补充 - query
# 查询沙河出版社 出版社的 书名 价格
# ret = Publish.objects.filter(name='沙河出版社').values('book__title','book__price')
# 还有一种写法:
# ret = Book.objects.filter(publish__name='沙河出版社').values('title','price')
#
# print(ret)
# print(ret.query) # 查询单条语句的 sql
"""
SELECT
"app01_book"."title", "app01_book"."price"
FROM "app01_publish"
LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id")
WHERE "app01_publish"."name" = 沙河出版社
"""
"""
SELECT
"app01_book"."title", "app01_book"."price"
FROM "app01_book"
INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."nid")
WHERE "app01_publish"."name" = 沙河出版社
"""
"""
select
Book.title,Book.price
from Publish
inner join Book on Publish.pk = Book.publish_id
where publish.name = '沙河出版社'
"""
十二、补充 - only defer selected_related prefetch_related (和性能相关得)
ORM补充:
a. 需求: 只取某n列
queryset=[ {},{}]
models.User.objects.all().values( 'id','name') queryset=[ (),()]
models.User.objects.all().values_list( 'id','name') queryset=[ obj,obj]
result = models.User.objects.all().only('id','name','age') # 只取
# result = models.User.objects.all().defer('id','name','age') # 排除
for item in reuslt:
print(item.id,item.name,item.age)
b. 需求: 打印所有用户姓名以及部门名称 class depart:
title = .... class User:
name = ...
dp = FK(depart) # select * from user
# result = models.User.objects.all()
# for item in result:
# print(item.name) # select * from user left join depart on user.dp_id = depart.id
# result = models.User.objects.all().selected_related('dp') # 性能上提高
# for item in result:
#print(item.name,item.dp.title )
- only
- defer
- seleted_related
- prefetch_related 示例:
class Depart(models.Model): 5个部门
title = models.CharField(...) class User(models.Model): 10个用户
name = models.CharField(...)
email = models.CharField(...)
dp = models.FK(Depart) 1.以前的你:11次单表查询 result = User.objects.all()
for item in result:
print(item.name,item.dp.title) 2. seleted_related,主动做连表查询(1次链表)(支持onetoone FK) result = User.objects.all().seleted_related('dp')
for item in result:
print(item.name,item.dp.title) 问题:如果链表多,性能越来越差。 3. prefetch_related:2次单表查询 (还支持m2m)
# select * from user ;
# 通过python代码获取:dp_id = [1,2]
# select * from depart where id in dp_id
result = User.objects.all().prefetch_related('dp')
for item in result:
print(item.name,item.dp.title) 赠送:
为什么要有FK; 如何没有FK,所有的数据就都得存在一张表里;浪费硬盘;降低了查询速度,插入有约束;
但是:
数据量比较大,不会使用FK,允许出现数据冗余。因为单表查询速度快。
十三、orm操作,偏原生sql, using ... 选择数据库
- select_related,连表操作,相当于主动做join
- prefeth_related,多次单表操作,先查询想要的数据,然后构造条件,如:id=[1,2,3],再次查询其他表根据id做条件。
- only
- defer
- F 更新数据库字段
- Q 构造复杂条件
- 通过ORM写偏原生SQL:
https://www.cnblogs.com/wupeiqi/articles/6216618.html
- extra
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) - raw
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) - 原生SQL from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
PS: 选择数据库
queryset = models.Course.objects.using('default').all()
Django - ORM - 进阶的更多相关文章
- Django orm进阶查询(聚合、分组、F查询、Q查询)、常见字段、查询优化及事务操作
Django orm进阶查询(聚合.分组.F查询.Q查询).常见字段.查询优化及事务操作 聚合查询 记住用到关键字aggregate然后还有几个常用的聚合函数就好了 from django.db.mo ...
- 9.14.16 Django ORM进阶用法
2018-9-14 14:26:45 ORM 练习题 : http://www.cnblogs.com/liwenzhou/articles/8337352.html 2018-9-14 21:1 ...
- Django中的ORM进阶操作
Django中的ORM进阶操作 Django中是通过ORM来操作数据库的,通过ORM可以很easy的实现与数据库的交互.但是仍然有几种操作是非常绕也特别容易混淆的.于是,针对这一块,来一个分类总结吧. ...
- 【python】-- Django ORM(进阶)
Django ORM(进阶) 上一篇博文简述了Django ORM的单表操作,在本篇博文中主要简述Django ORM的连表操作. 一.一对多:models.ForeignKey() 应用场景:当一张 ...
- django框架基础-ORM进阶-长期维护
############### ORM进阶---contenttype ################ 设计思路: """ 路飞有两种课,专题课和学位课, ...
- Django ORM操作及进阶
一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 ...
- django 2 ORM操作 ORM进阶 cookie和session 中间件
ORM操作 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述 ...
- Python之路【第十七篇】:Django【进阶篇 】
Python之路[第十七篇]:Django[进阶篇 ] Model 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接 ...
- Python之路【第十七篇】:Django【进阶篇】
Python之路[第十七篇]:Django[进阶篇 ] Model 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接 ...
随机推荐
- php -- 静态变量
一般的函数内变量在函数结束后会释放,比如局部变量,但是静态变量却不会.下次再调用这个函数的时候,该变量的值会保留下来. 静态的变量的基本用法 1. 在类中定义静态变量 [访问修饰符] static $ ...
- python 模块之间相互引用
模块层级关系: ----: |->AA.py |->BB.py |->CC.py AA.py from BB import BB class AA: def sub(self, x) ...
- 原生js版ajax请求
function getXMLHttpRequest() { var xhr; if(window.ActiveXObject) { xhr= new ActiveXObject("Micr ...
- Session超时问题(AOP 过滤器)
public class TimeoutAttribute : ActionFilterAttribute { public override void OnActionExecuting(Actio ...
- react新手入门(序)
之前在软件园使用的是react,当时为了做个集光推送,自己去搭过react,这次项目中继续使用react,于是又重新操作了遍,恰巧公司买了本react的书籍,这本书写的非常好,看着并不觉得拗口,很容易 ...
- ubuntu网络配置命令
Ubuntu网络配置例如: (1) 配置eth0的IP地址, 同时激活该设备. #ifconfig eth0 192.168.1.10 netmask 255.255.255.0 up (2) 配置e ...
- laravel 模版引擎使用
laravel 模版引擎以 @标签 开头,以 @end标签 结尾,常用有 foreach foreachelse if for while等 1)foreach 和 foreachelse 差不到,区 ...
- Hash表(hash table ,又名散列表)
直接进去主题好了. 什么是哈希表? 哈希表(Hash table,也叫散列表),是根据key而直接进行访问的数据结构.也就是说,它通过把key映射到表中一个位置来访问记录,以加快查找的速度.这个映射函 ...
- 安全日志:/var/log/secure
/var/log/secure 一般用来记录安全相关的信息,记录最多的是哪些用户登录服务器的相关日志,如果该文件很大,说明有人在破解你的 root 密码 [root@localhost ~]$ tai ...
- js方法区分IE浏览器和非IE浏览器
可以从IE特有的方法和非IE特有的方法来区分不同的浏览器 1.为元素添加事件监听: 非IE:.addEventListener("click",show,false)//第三个参数 ...