【算法】Normalization
Normalization(归一化)
写这一篇的原因是以前只知道一个Batch Normalization,自以为懂了。结果最近看文章,又发现一个Layer Normalization,一下就懵逼了。搞不懂这两者的区别。后来是不查不知道,一查吓一跳,Normalization的方法五花八门,Batch Normalization, Layer Normalization, Weight Normalization, Cosine Normalization, Instance Normalization, Group Normlization, Switchable Normlization.... 估计我没看到的还有很多。而且郁闷的是,感觉越看越不懂了...
这里简单记录一下目前的理解与问题。
白化
白化的目的是希望特征符合独立同分布i.i.d条件。包括:
- 去除特征之间的相关性 —> 独立;
- 使得所有特征具有相同的均值和方差 —> 同分布。
这里我有了第一个问题。什么叫做去除特征之间的相关性?
比如,有两个输入向量,X1=(x11,x12,x13,x14), X2=(x21,x22,x23,x24)
去除特征之间的相关性,只是去除x11,x12,x13,x14之间的相关性,还是去除x11和x21的相关性?
Normalization的好处
- 使得数据更加符合独立同分布条件,减少internal corvariate shift导致的偏移
- 使数据远离激活函数的饱和区,加快速度。(我理解是只对sigmoid这样的激活函数有效,对relu则没有加速作用了)
Normalization基本公式
\[h=f(g\frac{x-\mu}{\sigma}+b)\]
\(\mu\):均值
\(\sigma\):方差根
\(b\): 再平移参数,新数据以\(b\)为均值
\(g\): 再缩放参数,新数据以\(g^2\)为方差
归一化后的目标就是统一不同\(x\)之间的均值和方差
加入\(g\)和\(b\)的目的是使数据一定程度偏离激活函数的线性区,提高模型表达能力。因为均值是0的话正好落在sigmoid函数的线性部分。
第二个问题,g和b是根据什么确定的,是trainable的吗?
Batch Normalization
Batch Normalization是针对不同batch导致的数据偏移做归一化的方式。比如,一个batch有3个输入,每个输入是一个长度为4的向量。
\(X1=(x11,x12,x13,x14)\)
\(X2=(x21,x22,x23,x24)\)
\(X3=(x31,x32,x33,x34)\)
在上述条件下,归一化时的均值是:
\(\mu=(\frac{x11+x21+x31}{3},\frac{x12+x22+x32}{3},\frac{x13+x23+x33}{3},\frac{x14+x24+x34}{3})\)
这里主要展示一下计算时的方向,即对于每个元素位置,对不同的输入做归一化。方差同理。
第三个问题,很多文章都说batch norm需要在batch size较大,不同batch之间均值方差相差不大的情况下效果好。
即batch的均值方差跟整体的均值方差一致时效果好。
这我就不懂了,无论之前每个batch的分布是怎样的,经过归一化,都已经是相同分布了。为什么一定要原始batch之间分布相似呢?
Batch norm有个缺点,即需要记录每一个batch输入的均值和方差,对于变长的RNN网络来说计算麻烦。
第四个问题:为什么要记录每个batch的均值和方差?对RNN效果不好仅仅因为麻烦吗?
我个人理解BN在RNN上效果不好的原因是,虽然RNN训练时网络深度很深,但实际上只有一个神经元节点,相当于把所有层的神经元的均值和方差设定为相同的值了,导致效果不佳。
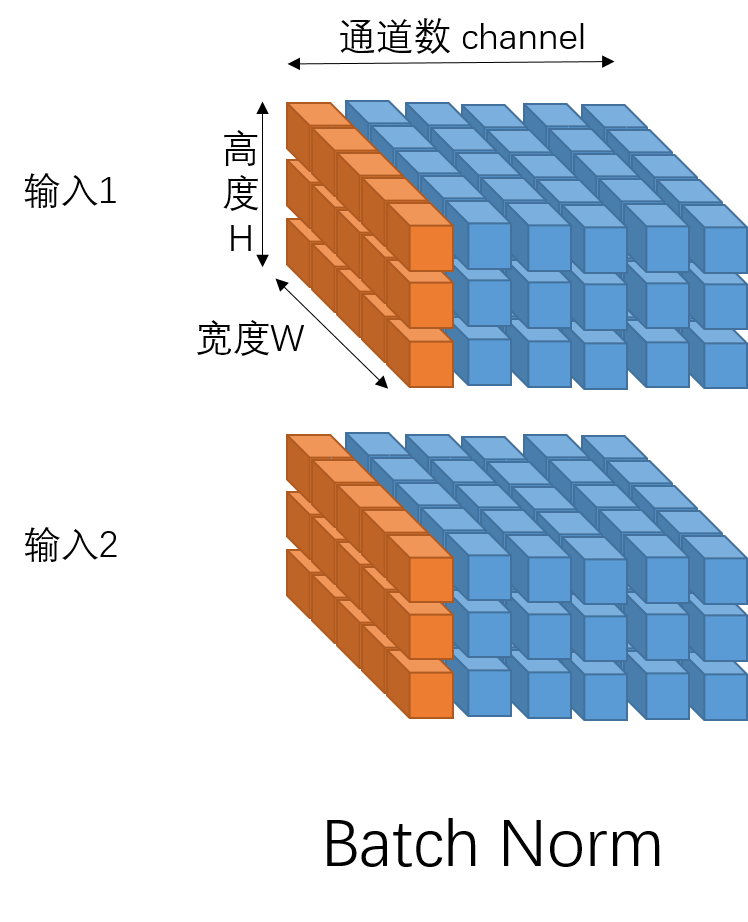
如果是图像,则输入是一个四维矩阵,(batch_size, channel_size, weight, height),此时batch norm是针对同一个batch的不同输入中属于同一通道的元素做归一化。如下图,是一个batch_size=2, channel_size=6, weight=5, height=3的例子。一次batch norm是对所有橙色部分元素做归一化。
Layer Normalization
Layer Normalization是针对同一个输入的不同维度特征的归一化方式。还是用上面的例子。
对于\(X1\)来说,layer norm的归一化均值是: \(\mu=\frac{x11+x12+x13+x14}{4}\)
对于图像来说,则是对一个输入的所有元素做归一化。如下图橙色部分:

Instance Norm
对一个输入图像的一个通道中的所有元素做归一化。如下图橙色部分:

Group Norm
对于一个输入图像的多个通道元素做归一化。如下图橙色部分:

Weight Norm
前面的归一化方法都是从不同维度对输入数据做归一化,而weight norm则是对权重做归一化。
Cosine Norm
抛弃了权重和输入点积的计算方式,改用其他函数。
参考文献
【算法】Normalization的更多相关文章
- 【转载】 详解BN(Batch Normalization)算法
原文地址: http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ------------------------------- ...
- Batch Normalization原理及其TensorFlow实现——为了减少深度神经网络中的internal covariate shift,论文中提出了Batch Normalization算法,首先是对”每一层“的输入做一个Batch Normalization 变换
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanish ...
- Batch Normalization的算法本质是在网络每一层的输入前增加一层BN层(也即归一化层),对数据进行归一化处理,然后再进入网络下一层,但是BN并不是简单的对数据进行求归一化,而是引入了两个参数λ和β去进行数据重构
Batch Normalization Batch Normalization是深度学习领域在2015年非常热门的一个算法,许多网络应用该方法进行训练,并且取得了非常好的效果. 众所周知,深度学习是应 ...
- 常见的几种 Normalization 算法
神经网络中有各种归一化算法:Batch Normalization (BN).Layer Normalization (LN).Instance Normalization (IN).Group No ...
- 归一化方法 Normalization Method
1. 概要 数据预处理在众多深度学习算法中都起着重要作用,实际情况中,将数据做归一化和白化处理后,很多算法能够发挥最佳效果.然而除非对这些算法有丰富的使用经验,否则预处理的精确参数并非显而易见. 2. ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- PCA算法
本文出处:http://blog.csdn.net/xizhibei http://www.cnblogs.com/bourneli/p/3624073.html PrincipalComponent ...
- SIFT算法:DoG尺度空间生产
SIFT算法:DoG尺度空间生产 SIFT算法:KeyPoint找寻.定位与优化 SIFT算法:确定特征点方向 SIFT算法:特征描述子 目录: 1.高斯尺度空间(GSS - Gauss Scal ...
随机推荐
- react-redux的基本用法
注意:读懂本文需要具备redux基础知识, 注明:本文旨在说明如何在实际项目中快速使用react-redux,限于篇幅,本文对具体的原理并未做分析,请参考redux官网 我一直以为我写了一篇关于rea ...
- [HNOI2007]神奇游乐园(插头DP)
题意:n*m的矩阵内值有正有负,找一个四连通的简单环(长度>=4),使得环上值的和最大. 题解:看到2<=m<=6和简单环,很容易想到插头DP,设f[i][j][k]表示轮廓线为第i ...
- hdu 4542 "小明系列故事——未知剩余系" (反素数+DFS剪枝)
传送门 参考资料: [1]:https://blog.csdn.net/acdreamers/article/details/25049767 题意: 输入两个数 type , k: ①type = ...
- Activity之间的跳转和数据传输
1.显式跳转 protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceSt ...
- CSS 知识点整理
本文是我整理的关于CSS的部分基础知识点,适合正在准备前端工作面试的人做简单回顾. 1. 盒子模型 CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容. Mar ...
- oracle not in 改为 not exist
修改前 SELECT pageID, permissionID FROM tableA WHERE userID=#{userID} AND projectCode=#{projectCode} AN ...
- To making it count.
- How do you take your caviar, sir? 鱼子酱还要吗,先生? - No caviar for me, thanks. Never did like it much. ...
- 技术栈(technology stack)
technology stack 技术栈: 产品实现上依赖的软件基础组件, 包括 1. 系统 2. 中间件 3. 数据库 4. 应用软件 5. 开发语言 6. 框架 https://en.wikipe ...
- Java虚拟机运行时内存区域简析
figure:first-child { margin-top: -20px; } #write ol, #write ul { position: relative; } img { max-wid ...
- Ubuntu18.04环境下melodic安装gmapping
Ubuntu18.04 环境下melodic中很多包没有提供sudo apt install的安装方式,需要通过源代码安装,安装方法如下: 1.先安装依赖库: sudo apt--dev sudo a ...