北大开源全新中文分词工具包:准确率远超THULAC、结巴分词
最近,北大开源了一个中文分词工具包,它在多个分词数据集上都有非常高的分词准确率。其中广泛使用的结巴分词误差率高达 18.55% 和 20.42,而北大的 pkuseg 只有 3.25% 与 4.32%。
pkuseg 是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。它简单易用,支持多领域分词,在不同领域的数据上都大幅提高了分词的准确率。
项目地址:https://github.com/lancopku/PKUSeg-python
pkuseg 具有如下几个特点:
高分词准确率:相比于其他的分词工具包,该工具包在不同领域的数据上都大幅提高了分词的准确度。根据北大研究组的测试结果,pkuseg 分别在示例数据集(MSRA 和 CTB8)上降低了 79.33% 和 63.67% 的分词错误率。
多领域分词:研究组训练了多种不同领域的分词模型。根据待分词的领域特点,用户可以自由地选择不同的模型。
支持用户自训练模型:支持用户使用全新的标注数据进行训练。
此外,作者们还选择 THULAC、结巴分词等国内代表分词工具包与 pkuseg 做性能比较。他们选择 Linux 作为测试环境,在新闻数据(MSRA)和混合型文本(CTB8)数据上对不同工具包进行了准确率测试。此外,测试使用的是第二届国际汉语分词评测比赛提供的分词评价脚本。评测结果如下:
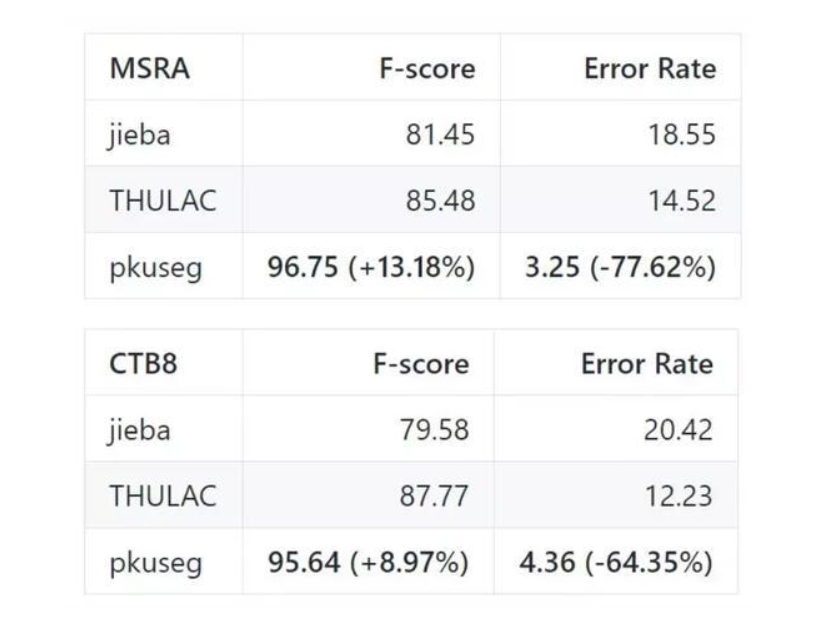
我们可以看到,最广泛使用的结巴分词准确率最低,清华构建的 THULAC 分词准确率也没有它高。当然,pkuseg 是在这些数据集上训练的,因此它在这些任务上的准确率也会更高一些。
预训练模型
分词模式下,用户需要加载预训练好的模型。研究组提供了三种在不同类型数据上训练得到的模型,根据具体需要,用户可以选择不同的预训练模型。以下是对预训练模型的说明:
MSRA:在 MSRA(新闻语料)上训练的模型。新版本代码采用的是此模型。
CTB8:在 CTB8(新闻文本及网络文本的混合型语料)上训练的模型。
WEIBO:在微博(网络文本语料)上训练的模型。
其中,MSRA 数据由第二届国际汉语分词评测比赛提供,CTB8 数据由 LDC 提供,WEIBO 数据由 NLPCC 分词比赛提供。在 GitHub 项目中,这三个预训练模型都提供了下载地址。
安装与使用
pkuseg 的安装非常简单,我们可以使用 pip 安装,也可以直接从 GitHub 下载:
- pip install pkuseg
使用 pkuseg 实现分词也很简单,基本上和其它分词库的用法都差不多:
- '''代码示例1: 使用默认模型及默认词典分词'''
- import pkuseg
- #以默认配置加载模型
- seg = pkuseg.pkuseg()
- #进行分词
- text = seg.cut('我爱北京天安门')
- print(text)
- '''代码示例2: 设置用户自定义词典'''
- import pkuseg
- #希望分词时用户词典中的词固定不分开
- lexicon = ['北京大学', '北京天安门']
- #加载模型,给定用户词典
- seg = pkuseg.pkuseg(user_dict=lexicon)
- text = seg.cut('我爱北京天安门')
- print(text)
- '''代码示例3'''
- import pkuseg
- #假设用户已经下载好了ctb8的模型并放在了'./ctb8'目录下,通过设置model_name加载该模型
- seg = pkuseg.pkuseg(model_name='./ctb8')
- text = seg.cut('我爱北京天安门')
- print(text)
对于大型文本数据集,如果需要快速分词的话,我们也可以采用多线程的方式:
- '''代码示例4'''
- import pkuseg
- #对input.txt的文件分词输出到output.txt中,使用默认模型和词典,开20个进程
- pkuseg.test('input.txt', 'output.txt', nthread=20)
最后,pkuseg 还能重新训练一个分词模型:
- '''代码示例5'''
- import pkuseg
- #训练文件为'msr_training.utf8',测试文件为'msr_test_gold.utf8',模型存到'./models'目录下,开20个进程训练模型
- pkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20)
这些都是 GitHub 上的示例,详细的内容请参考 GitHub 项目,例如参数说明和参考论文等。
北大开源全新中文分词工具包:准确率远超THULAC、结巴分词的更多相关文章
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- pkuseg:一个多领域中文分词工具包
pkuseg简单易用,支持细分领域分词,有效提升了分词准确度. 目录 主要亮点 编译和安装 各类分词工具包的性能对比 使用方式 相关论文 作者 常见问题及解答 主要亮点 pkuseg具有如下几个特点: ...
- 轻量级的中文分词工具包 - IK Analyzer
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luence为应用 ...
- THULAC:一个高效的中文词法分析工具包(z'z)
网址:http://thulac.thunlp.org/ THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词 ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- python 中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- 中文分词之结巴分词~~~附使用场景+demo(net)
常用技能(更新ing):http://www.cnblogs.com/dunitian/p/4822808.html#skill 技能总纲(更新ing):http://www.cnblogs.com/ ...
- EasyPR--一个开源的中文车牌识别系统
我正在做一个开源的中文车牌识别系统,Git地址为:https://github.com/liuruoze/EasyPR. 我给它取的名字为EasyPR,也就是Easy to do Plate Reco ...
- 中文分词接口api,采用结巴分词PHP版中文分词接口
中文分词,分词就是将连续的字序列按照一定的规范重新组合成词序列的过程.我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字.句和段能通过明显的分界符来简单划界,唯独词没有一个形式上 ...
随机推荐
- C语言作业2
一.实验目的与要求 1.if语句的应用 ●掌握C语言的逻辑运算和关系运算的规则 ●学会正确的使用关系表达式和逻辑表达式 ●掌握if-else语句的使用方法 2.switch/case语句的应用 ● ...
- 2018-2019-2 20165206 网络攻防技术 Exp5 MSF基础应用
- 2018-2019-2 20165206<网络攻防技术>Exp5 MSF基础应用 - 实验任务 1.1一个主动攻击实践,如ms08_067; (1分) 1.2 一个针对浏览器的攻击,如 ...
- (译)(function (window, document, undefined) {})(window, document); 真正的意思
由于非常感兴趣, 我查询了很多关于IIFE (immediately-invoked function expression)的东西, 如下: (function (window, document, ...
- DevExpress控件库 开发使用经验总结1 DevExpress简介、安装、使用
2015-01-24 最近公司开发的WinForm客户端图书行业ERP管理系统,界面端采用了DevExpress控件库.界面效果非常绚丽,类似于Office2007.2010的界面风格. 其中的控件功 ...
- XFire+Spring构建Web Service经验总结
使用工具 MyEclipse:6.5 ,tomcat6.x. 1.新建web项目,要导入用的包: 2程序结构: 3 web.xml配置文件 <?xml version="1.0&quo ...
- 基本排序算法(Java)
基本排序算法 (Java) 经过几次笔试,发现自己的Java基础有些薄弱,基本的排序算法掌握的还不够熟练,需要多加学习总结. 1. 选择排序 思想: 给定一个整数数组,例 int[] a ={38,6 ...
- 学习随笔:Django 补充及常见Web攻击 和 ueditor
判断用户是否登录 <!-- xxx.html --> {% if request.user.is_authenticated %} django中的request对象详解 填错表格返回上次 ...
- 其他信息: 未能加载文件或程序集“file:///C:\Program Files (x86)\SAP BusinessObjects\Crystal Reports for .NET Framework 4.0\Common\SAP BusinessObjects Enterprise XI 4.0\win32_x86\dotnet1\crdb_adoplus.dll”或它的某一个依赖
今天在使用水晶报表的过程中,遇到了这个问题,下面是代码 FormReportView form = new FormReportView(); ReportDocument rptc = new Re ...
- C语言柔性数组讲解
#include<stdio.h> typedef struct _SoftArray{ int len; int array[]; }SoftArray; int main() { ; ...
- tar解压到指定目录
对于tar.gz的压缩包,压缩参数是tar xvzf 指定解压路径为/tmp则为: tar xzvf xxx.tar.gz -C /tmp 注意/文件夹必须存在.