利用python抓取页面数据
1、首先是安装python(注意python3.X和python2.X是不兼容的,我们最好用python3.X)
安装方法:安装python
2、安装成功后,再进行我们需要的插件安装。(这里我们需要用到requests和pymssql两个插件re是自带的)注:这里我们使用的是sqlserver所以安装的是pymssql,如果使用的是mysql可以参考:安装mysql驱动
安装插件的方法为
安装pymssql->进入命令行输入命令:pip install pymssql
安装requests->进入命令行输入命令:pip install requests
可以通过命令pip list来查看是否安装成功。
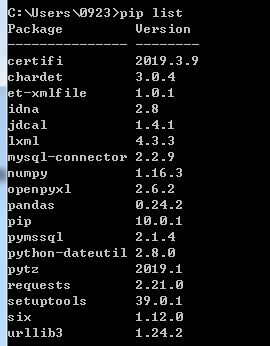
3、安装完成后,我们编写代码如下:
import requests
from requests.exceptions import RequestException
import re
import pymssql #通过url获得页面内容
def get_one_page(url):
try:
response = requests.get(url)
#解决乱码问题
response.encoding = response.apparent_encoding
if response.status_code == 200:
return response.text
return None
except RequestException:
return None #通过正则表达式抓取我们所需要的页面内容
def parse_one_page(html):
pattern = re.compile('<div class="newBox">.*?src="(.*?)".*?<h4>.*?<div class="fp_subtitle">.*?>(.*?)</a></div>.*?</h4>.*?<p>(.*?)</p>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?<span>(.*?)</span>.*?</div>',re.S)
items = re.findall(pattern,html)
return items; #数据库连接
def db_conn():
server = '192.168.6.111\mssqlzf'
user = 'sa'
password = 'sa@2016'
database = 'zfnewdb'
return pymssql.connect(server, user, password, database) #定义main()
def main():
conn = db_conn()
url = 'http://www.stdaily.com/cxzg80/index.shtml'
html = get_one_page(url)
cursor = conn.cursor()
#将抓取回来的数据循环插入到数据库中,注意:parse_one_page返回的数据类型为
for item in parse_one_page(html):
cursor.execute("INSERT INTO tblGrabNews VALUES (%s,%s,%s,%s,%s,%s)",(item[1], item[2], item[0], item[5], item[3], item[4]))
conn.commit()
conn.close() #执行main()
if __name__ == '__main__':
main()
注意,parse_one_page(html)函数返回的数据类型如下:[(),(),()...],所以上面程序要的for循环才会那么去写,如果不知道什么是list和tuple的同学可以看一下这篇文章list和tuple。

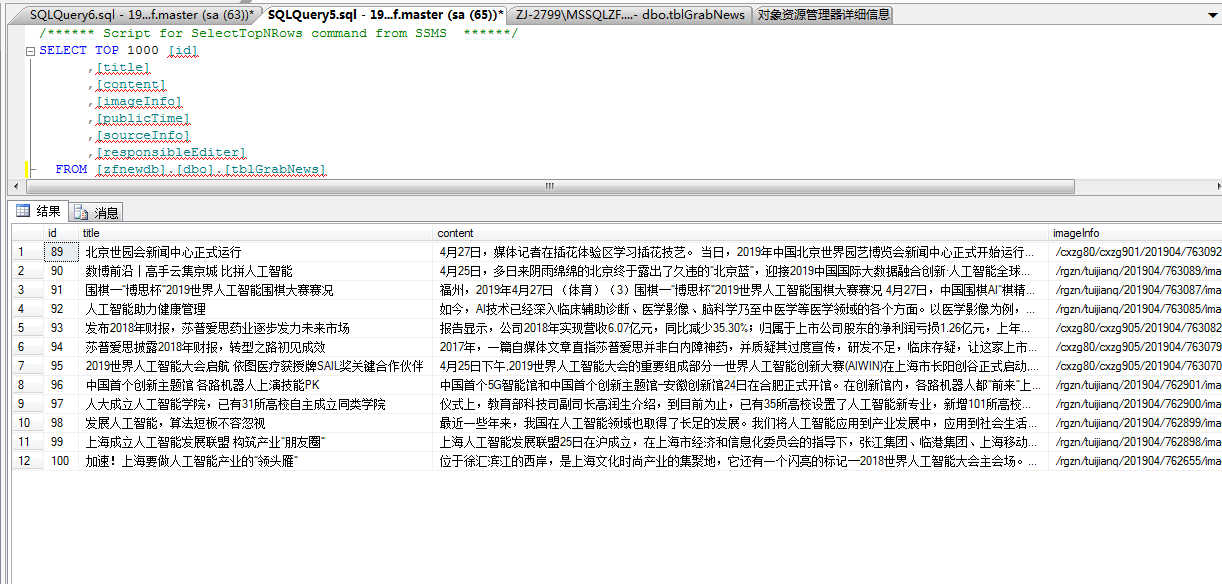
运行上述代码后,可在数据库中看到爬下来的数据。
数据表结构为:
create table [zfnewdb].[dbo].[tblGrabNews] (
id int identity (1,1) primary key,
title varchar(255),
content text,
imageInfo text,
publicTime varchar(100),
sourceInfo varchar(100),
responsibleEditer varchar(100)
)
希望能帮助到有需要的人。
利用python抓取页面数据的更多相关文章
- 爬虫抓取页面数据原理(php爬虫框架有很多 )
爬虫抓取页面数据原理(php爬虫框架有很多 ) 一.总结 1.php爬虫框架有很多,包括很多傻瓜式的软件 2.照以前写过java爬虫的例子来看,真的非常简单,就是一个获取网页数据的类或者方法(这里的话 ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
- 对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App)
对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App) 实验目的:对比使用Charles和Fiddler两个工具 实验对象:车易通App,易销通App 实验结果 ...
- python 抓取alexa数据
要抓取http://www.alexa.cn/rank/baidu.com网站的排名信息:例如抓取以下信息: 需要微信扫描登录 因为这个网站抓取数据是收费,所以就利用网站提供API服务获取json信息 ...
- 记录使用jQuery和Python抓取采集数据的一个实例
从现成的网站上抓取汽车品牌,型号,车系的数据库记录. 先看成果,大概4w条车款记录 一共建了四张表,分别存储品牌,车系,车型和车款 大概过程: 使用jQuery获取页面中呈现的大批内容 能通过页面一次 ...
- python 抓取金融数据,pandas进行数据分析并可视化系列 (一)
终于盼来了不是前言部分的前言,相当于杂谈,算得上闲扯,我觉得很多东西都是在闲扯中感悟的,比如需求这东西,一个人只有跟自己沟通好了,总结出某些东西了,才能更好的和别人去聊,去说. 今天这篇写的是明白需求 ...
- js 抓取页面数据
数据抓取 主要思路和原理 在根节点document中监听所有需要抓取的事件 在元素事件传递中,捕获阶段获取事件信息,进行埋点 通过getBoundingClientRect() 方法可获取元素的大小和 ...
- 使用python抓取App数据
App接口爬取数据过程使用抓包工具手机使用代理,app所有请求通过抓包工具获得接口,分析接口反编译apk获取key突破反爬限制需要的工具:夜神模拟器FiddlerPycharm实现过程首先下载夜神模拟 ...
- 网络爬虫-使用Python抓取网页数据
搬自大神boyXiong的干货! 闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干 准备搭建环境 因为是MAC电脑,所以自动安装了Python 2.7的版本 添加一个 库 Beauti ...
随机推荐
- 白盒测试实践-day02
一.任务进展情况 小组分工完成后,了解findbugs的使用过程,以及junit的测试步骤. 二.存在的问题 由于对单元测试不是太了解,导致无法进行测试. 三.解决方法 看mooc上面的视频,了解测试 ...
- Spring-注入
一.Spring的基本介绍:Spring是一个开源框架,Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson创建.简单来说,Spring是一个分层的JavaSE/ ...
- python自动化打开网页
from selenium.webdriver.firefox.options import Options as FOptionsfrom selenium.webdriver.chrome.opt ...
- yii 1.x 添加 rules 验证url数组
public function rules() { return CMap::mergeArray( parent::rules(),array( array('third_link', 'urlAr ...
- [dev][socket] unix domain socket删除socket文件
问题 在使用unix domain socket的时候,bind之后,会在本地路径里 产生一个与path对应的socket文件. 如何正确的在用完socket之后,对其销毁呢? 方案 使用 unlin ...
- echo 与 printf的区别与联系
echo命令默认是带有换行符的. 如果想让echo命令去掉每一行后面的换行符 方法1; 如果确信自己的脚本程序只运行在bash上,可以使用如下语法来出去空格: echo -n "Is it ...
- CF1139D Steps to One
题目链接:洛谷 这个公式可真是个好东西.(哪位大佬知道它叫什么名字的?) 如果$X$恒$\geq 0$,那么 $$E[X]=\int_0^{+\infty}P(X>t)dt$$ 呸,我什么都没写 ...
- Cookie/Session的机制与安全
转载自:https://harttle.land/2015/08/10/cookie-session.html Cookie和Session是为了在无状态的HTTP协议之上维护会话状态,使得服务器可以 ...
- Mybatis插入记录并返回MySQL自增主键
mapper Integer insertConfigAndGetId(CrawlerConfig config); xml <insert id="insertConfigAndGe ...
- Vue + webpack 项目实践
Vue.js 是一款极简的 mvvm 框架,如果让我用一个词来形容它,就是 “轻·巧” .如果用一句话来描述它,它能够集众多优秀逐流的前端框架之大成,但同时保持简单易用.废话不多说,来看几个例子: & ...