hadoop集群安装_实战
spark1.6.2+ hadoop2.6.2
词频统计完整案例:http://blog.csdn.net/zythy/article/details/17852579
hadoop学习:http://www.cnblogs.com/admln/category/618480.html
hadoop提交作业:http://weixiaolu.iteye.com/blog/1402919
所以,如果要永久修改RedHat的hostname,就修改/etc/sysconfig/network文件,将里面的HOSTNAME这一行修改成HOSTNAME=NEWNAME,其中NEWNAME就是你要设置的hostname。
1.机器准备:
关闭防火墙:
service iptables stop
service iptables status
10.112.29.177 vm-10-112-29-177 namenode
10.112.29.172 vm-10-112-29-172 datanode
10.112.29.174 vm-10-112-29-174 datanode
2.无密码登录:
生成master公钥:
- cd ~/.ssh (进入用户目录下的隐藏文件.ssh)
- ssh-keygen -t rsa (用rsa生成密钥)
- cp id_rsa.pub authorized_keys (把公钥复制一份,并改名为authorized_keys,这步执行完,应该ssh localhost可以无密码登录本机了,可能第一次要密码)
- scp authorized_key root@vm-10-112-29-172:~/.ssh (把重命名后的公钥通过ssh提供的远程复制文件复制到从机vm-10-112-29-172上面)
- chmod 600 authorized_keys (更改公钥的权限,也需要在从机vm-10-112-29-172中执行同样代码)
- ssh vm-10-112-29-172 (可以远程无密码登录vm-10-112-29-172这台机子了,注意是ssh不是sudo ssh。第一次需要密码,以后不再需要密码)
方法2:
cat id_rsa.pub >> authorized_keys
scp root@master:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
cat~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys

3.安装目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
4.
修改/usr/bigdata/hadoop-2.7.1/etc/hadoop下的配置文件
修改core-site.xml,加上
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-10-112-29-177:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
5.修改hdfs-site.xml,加上
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop-2.7.1/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm-10-112-29-177:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
6.修改mapred-site.xml,加上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>vm-10-112-29-177:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>vm-10-112-29-177:19888</value>
</property>
7.修改yarn-site.xml,加上
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>vm-10-112-29-177:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>vm-10-112-29-177:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>vm-10-112-29-177:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>vm-10-112-29-177:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>vm-10-112-29-177:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
注意:2048,2 设置过小,nodemanager启动失败 或者log中显示无法分配必要的资源 提交作业有可能一直 accpeted状态
8.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否则启动时会报error
export JAVA_HOME=/usr/java/jdk1.7.0_80
9.
配置/user/bigdata/hadoop-2.7.1/etc/hadoop目录下slaves
加上你的从服务器,
vm-10-112-29-172
vm-10-112-29-174
配置成功后,将hadhoop复制到各个从服务器上
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-172:/user/bigdata/
scp -r /user/bigdata/hadoop-2.7.1 root@vm-10-112-29-174:/user/bigdata/
scp /usr/bigdata/hadoop-2.6.2/etc/hadoop/yarn-site.xml root@vm-10-112-29-174:/usr/bigdata/hadoop-2.6.2/etc/hadoop
10.
主服务器上执行bin/hdfs namenode -format
进行初始化
sbin目录下执行 ./start-all.sh
可以使用jps查看信息
停止的话,输入命令,sbin/stop-all.sh
11.
这时可以浏览器打开10.112.29.177:8088查看集群信息啦
到此配置就成功啦,开始你的大数据旅程吧。。。
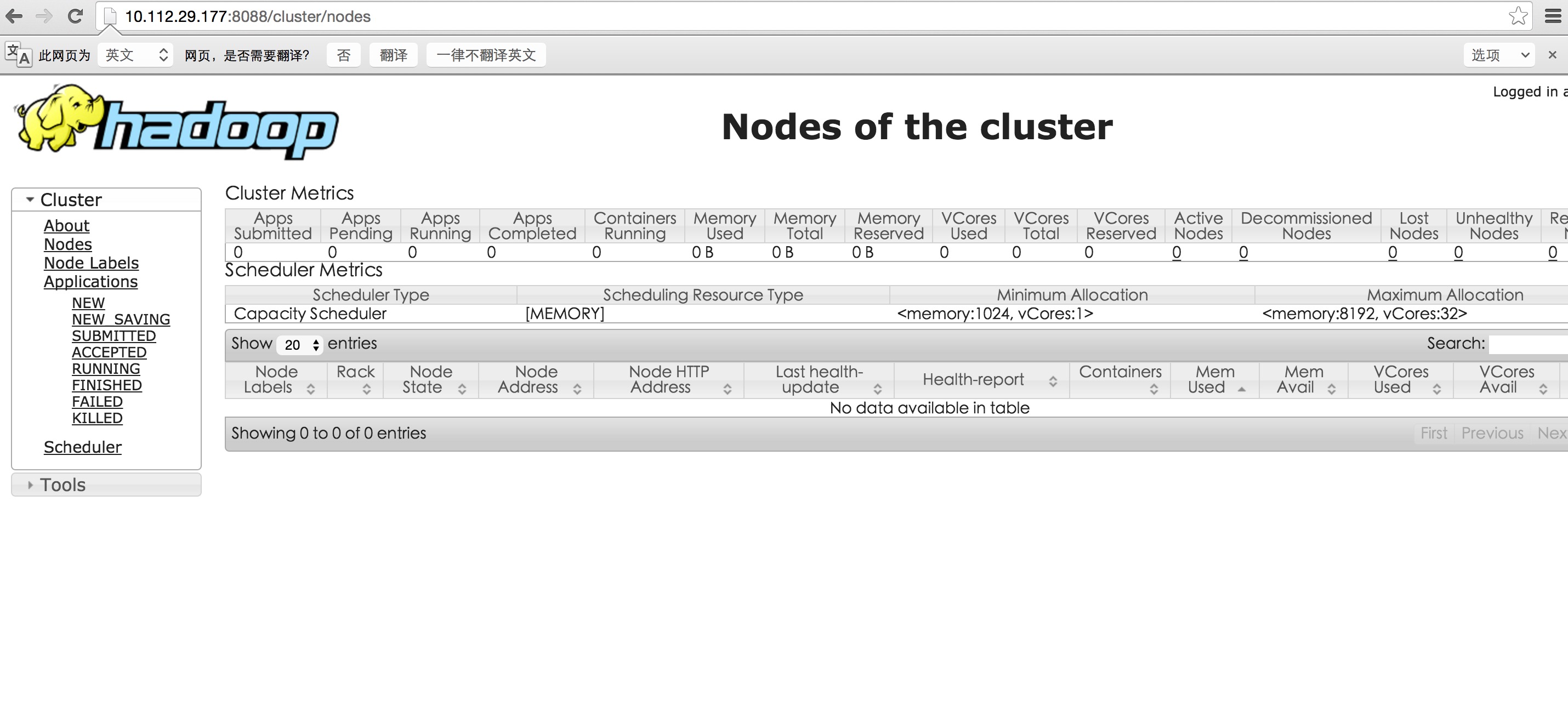
解决nodemanager 启动问题以后:

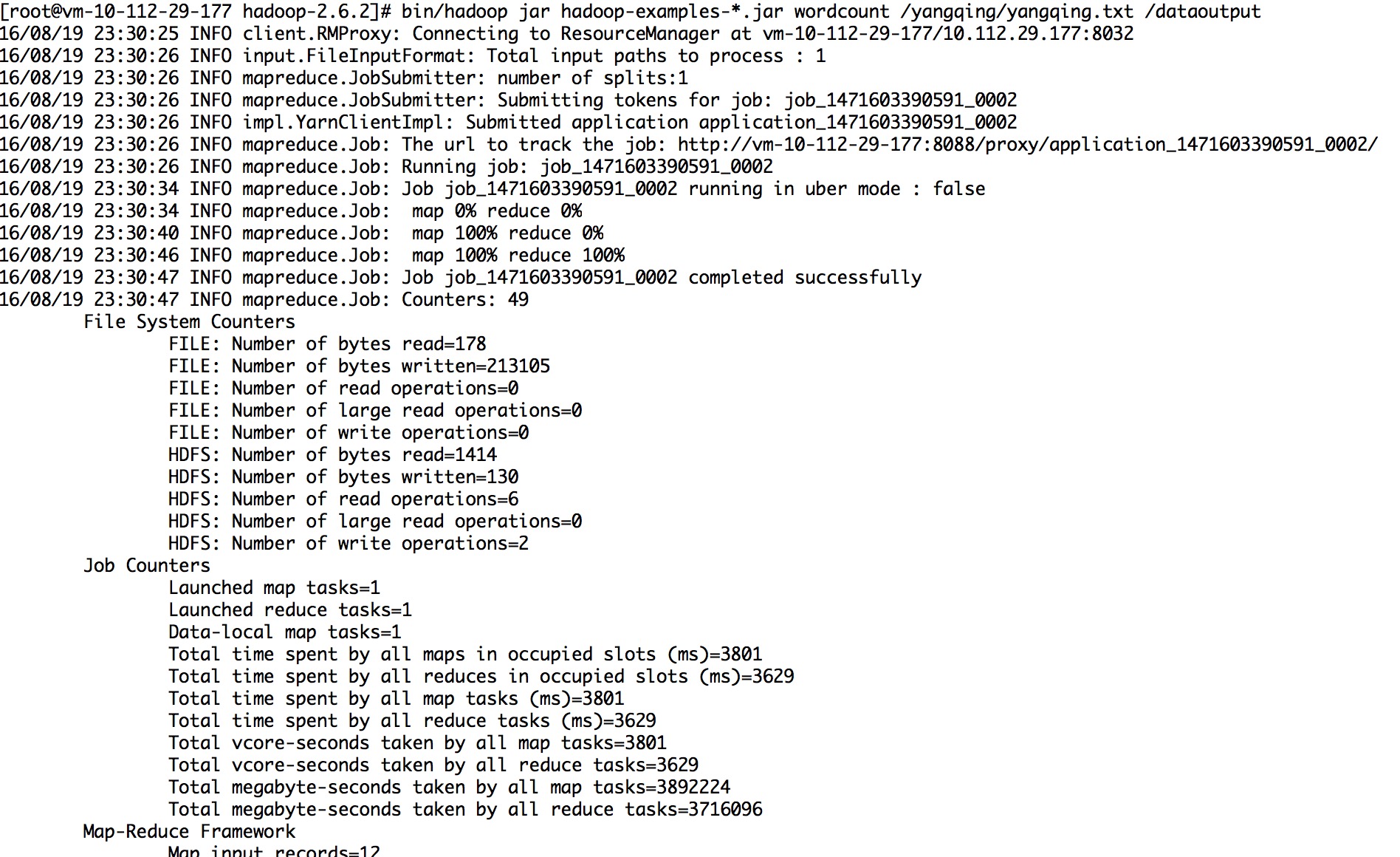
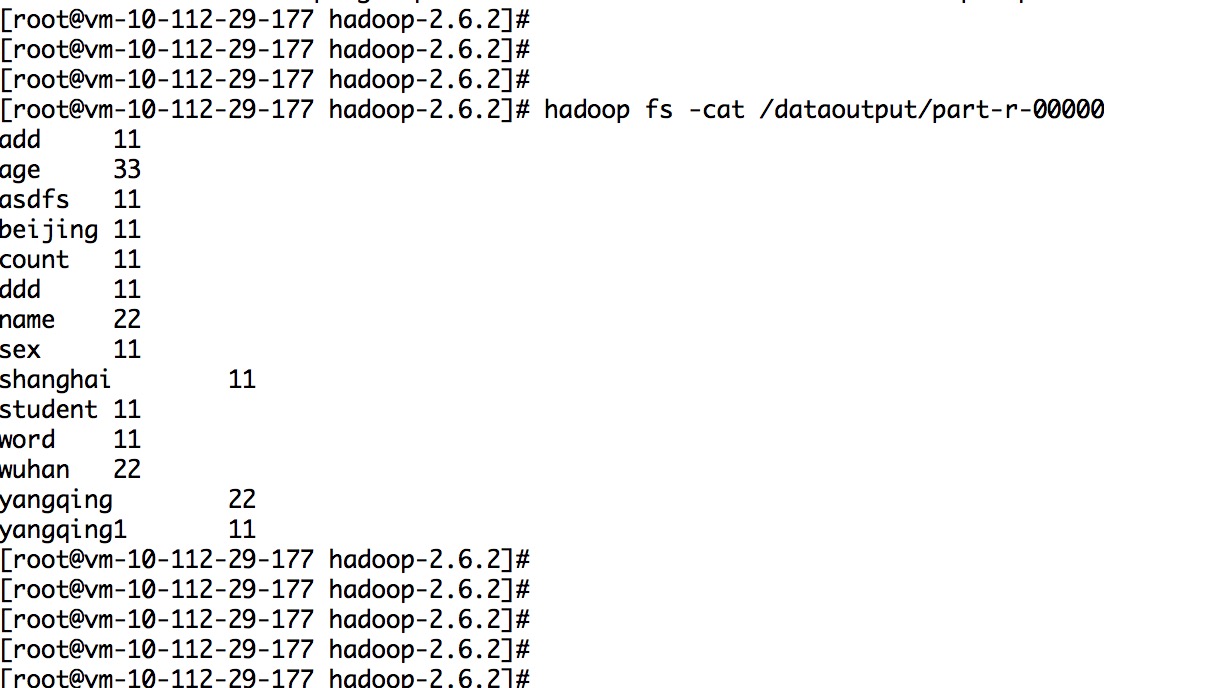
10.实例代码:
http://blog.csdn.net/ylchou/article/details/9264899
sh bin/hadoop fs -mkdir /tttt bin/hadoop fs -put /root/test/tttt.txt /tttt scp -r /usr/bigdata/hadoop-2.6.2 root@vm-10-112-29-174:/usr/bigdata/
hadoop集群安装_实战的更多相关文章
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群安装故障解决
nodemanager进程解决:http://blog.csdn.net/baiyangfu_love/article/details/13504849 编译安装:http://blog.csdn.n ...
- linux hadoop 集群安装步骤
http://blog.csdn.net/xjavasunjava/article/details/12013677 1,时间同步hadoop集群的每台机器的时间不能相差太大. 安装集群前最好进行一下 ...
- hadoop集群安装
首现非常感谢 虾皮(http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html) 安装过程是参照他的<Hadoop集群(第5期 ...
随机推荐
- 第一次在Django上编写静态网页
新建一个Python Django工程: Win+R进入cmd命令界面,并cd到指定工程目录下,比如我的工程目录是E:\wamp\Apache24\www\ 输入E: 跳转E盘 输入cd wamp\A ...
- Linux Kernel代码艺术——系统调用宏定义
我们习惯在SI(Source Insight)中阅读Linux内核,SI会建立符号表数据库,能非常方便地跳转到变量.宏.函数等的定义处.但在处理系统调用的函数时,却会遇到一些麻烦:我们知道系统调用函数 ...
- bzoj-4514(网络流)
题目链接: 4514: [Sdoi2016]数字配对 Description 有 n 种数字,第 i 种数字是 ai.有 bi 个,权值是 ci. 若两个数字 ai.aj 满足,ai 是 aj 的倍数 ...
- UVA - 11137 Ingenuous Cubrency[背包DP]
People in Cubeland use cubic coins. Not only the unit of currency iscalled a cube but also the coins ...
- 【每日一linux命令6】命令中的命令
许多命令在执行后,会进入该命令的操作模式,如 fdisk.pine.top 等,进入后我们必须要使用该 命令中的命令,才能正确执行:而一般要退出该命令,可以输入 exit.q.quit 或是按[Ctr ...
- Jenkins学习四:Jenkins 邮件配置
本文主要对Windows环境 jenkins 的邮件通知进行介绍 jenkins 内置的邮件功能 使用email-ext插件扩展的邮件功能 邮件通知功能主要包含两个部分:全局配置和项目配置. 一. 先 ...
- [2016湖南长沙培训Day4][前鬼后鬼的守护 chen] (动态开点线段树+中位数 or 动规 or 贪心+堆优化)
题目大意 给定一个长度为n的正整数序列,令修改一个数的代价为修改前后两个数的绝对值之差,求用最小代价将序列转换为不减序列. 其中,n满足小于500000,序列中的正整数小于10^9 题解(引自mzx神 ...
- ThinkPHP实现支付宝接口功能
最近做系统,需要实现在线支付功能,毫不犹豫,选择的是支付宝的接口支付功能.这里我用的是即时到帐的接口,具体实现的步骤如下:一.下载支付宝接口包下载地址:https://doc.open.alipay. ...
- C#.NET 大型企业信息化系统集成快速开发平台 4.1 版本 - 如何才能成为全国知名软件组件
往往我们看到一个好用的工具.就能知道制作这个工具有多少不容易,使用好这个工具也有多少不容易? 通用快速开发框架同样也是经过多年的完善改进才到了今天的稳定成熟度,知名程度,为什么能成为全国有名的软件组件 ...
- Nginx负载均衡实践之一:基本实现
由于现在的网站架构越来越大,基于互联网的用户也是日渐增长,所以传统的单机版服务器已经渐渐不能适应时代发展的需要.最近在和其他企业接触的过程中,发现对于互联网的经验尤为看重,所谓的互联网经验,其实就是指 ...