spark提交运算原理
前面几天元旦过high了,博客也停了一两天,哈哈,今天我们重新开始,今天我们介绍的是spark的原理
首先先说一个小贴士:
spark中,对于var count = 0,如果想使count自增,我们不能使用count++,而是我们要使用count = count + 1
接下来开始我们的正经事了,介绍spark的工作原理,先放上一张原理图
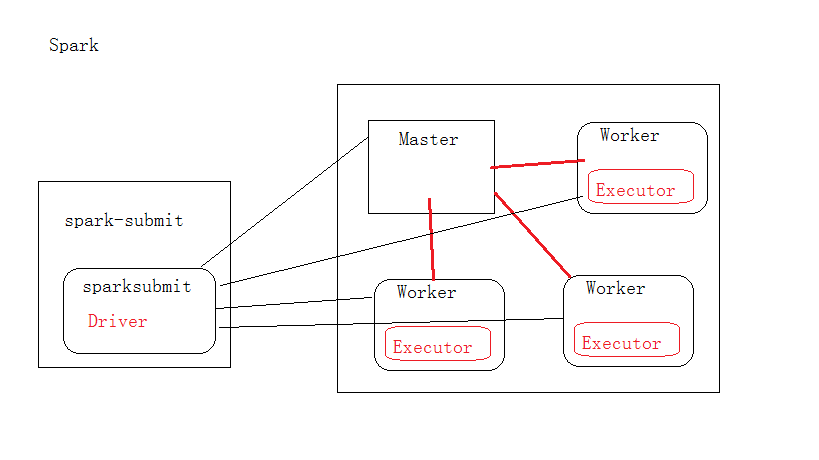
从这个图我们可以看出,当一个任务提交的时候,我们就可以调用调用Master,然后Master在找资源充沛的Worker,对于我们而言,如果我们写了一Spark的的程序,肯定里面有main方法,此时这个spark的程序就是一个spark-submit,而里面的main方法,我们就可以认为是一个SparkSubmit里面的Driver,一旦遇到Action,因为我们这里面分为Transformer以及Action,在前面的章节中已经介绍过这二者的区别了一旦遇到Action(此时我们可以简单的理解为这在执行collect),就把我们的任务提交到Master,然后Master申请资源,并决定在资源可用的机器上(Worker)启动一个Executor进程,则此后当Master接受到一个任务,并分配给资源可用的worker,其实是worker底下的Executor正在计算
在spark当中,一个任务叫做application,但是在hadoop中,一个任务叫做job
其中,我们可以这样理解,加入hdfs里面有200M缓存的规则,如果分为2个切片,则此时我们也是需要两个Excutor
来保存这两个block里面的内容,但是这个是不完整的,我们就会使用Driver会把这两个Excutor获取的数据进行汇总,
然后在经过Driver在对这个里面所有的Excutor进行广播,此时这个里面的Excutor的缓存了所有的数据
SPARK中的各个名词
spark程序:App
用于提交应用程序的:Driver
资源管理:Master
节点管理:Worker
执行真正的业务逻辑:spark-submit
spark提交运算原理的更多相关文章
- Spark生态以及原理
spark 生态及运行原理 Spark 特点 运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算.官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapR ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- Spark Scheduler内部原理剖析
文章正文 通过文章“Spark 核心概念RDD”我们知道,Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度.Spark的任务调度 ...
- Spark分布式执行原理
Spark分布式执行原理 让代码分布式运行是所有分布式计算框架需要解决的最基本的问题. Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有 ...
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
- Spark Streaming的原理
Spark Streaming应用也是Spark应用,Spark Streaming生成的DStream最终也是会转化成RDD,然后进行RDD的计算,所以Spark Streaming最终的计算是RD ...
- IOS-CGAffineTransformMake 矩阵变换 的运算原理
1.矩阵的基本知识: struct CGAffineTransform { CGFloat a, b, c, d; CGFloat tx, ty; }; CGAffineTransform C ...
- spark提交任务的流程
1.spark提交流程 sparkContext其实是与一个集群建立一个链接,当你停掉它之后 就会和集群断开链接,则属于这个资源的Excutor就会释放掉了,Driver 向Master申请资源,Ma ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
随机推荐
- 安装BI Publisher Desktop报错:“Template Builder Installer Failed:Unexpected Error”
原因:office的版本未安装正确,应该安装X86版本的,如果是X64的会出现,重新安装X86版本的office后解决问题.
- SuiteCRM-7.7.6 (Ubuntu 16.04)
平台: Ubuntu 类型: 虚拟机镜像 软件包: suitecrm-7.7.6 commercial crm open-source suitecrm 服务优惠价: 按服务商许可协议 云服务器费用: ...
- JavaMail 的简单使用
概述 邮件功能模块在大多数网站中,都是必不可少的功能模块.无论是用户注册还是重置密码,邮件都是比较常用的一个方式.本文主要介绍 JavaMail 的简单使用,方便大家快速开发,供大家参考.完整的 de ...
- April 12 2017 Week 15 Wednesday
Genius often betrays itself into great errors. 天才常被天才误. Genius can help us get greater achievements, ...
- POJ-2456 Aggressive cows---最大化最小值(也就是求最大值)
题目链接: https://vjudge.net/problem/POJ-2456 题目大意: 有n个牛栏,选m个放进牛,相当于一条线段上有 n 个点,选取 m 个点, 使得相邻点之间的最小距离值最大 ...
- DOM(一):节点层次-Node类型
Node类型DOM1级定义了一个Node接口,该接口将由DOM中的所有节点类型实现,每个节点都有一个nodeType属性,用于表明节点的类型.节点类型由在Node类型中定义的下列12个数值常量来表示, ...
- Android Support v4,v7,v13的区别和应用场景
android-support-v4 是谷歌推出的兼容包,最低兼容Android1.6的系统,里面有类似ViewPager等控件.ViewPager在Android 1.6以下的版本是不自带的,所以要 ...
- kiiti分割的数据及其处理
kitti和cityscape的gt的分割不太一样,下边缘不再是从黑色开始的,而是直接是类别 red,green,blue = img_gt[i,j] 1.道路的颜色(紫色):128 64 128 2 ...
- 第16章 STM32中断应用概览—零死角玩转STM32-F429系列
第16章 STM32中断应用概览 全套200集视频教程和1000页PDF教程请到秉火论坛下载:www.firebbs.cn 野火视频教程优酷观看网址:http://i.youku.com/fi ...
- java并发多线程(摘自网络)
1. 进程和线程之间有什么不同? 一个进程是一个独立(self contained)的运行环境,它可以被看作一个程序或者一个应用.而线程是在进程中执行的一个任务.Java运行环境是一个包含了不同的类和 ...