pytorch构建优化器
这是莫凡python学习笔记。
1.构造数据,可以可视化看看数据样子
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
# torch.manual_seed(1) # reproducible LR = 0.01
BATCH_SIZE = 32
EPOCH = 12 # fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size())) # plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
输出
2.构造数据集,及数据加载器
# put dateset into torch dataset
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
3.搭建网络,以相应优化器命名
# default network
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
4.构造优化器,此处共构造了SGD,Momentum,RMSprop,Adam四种优化器
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
5.定义损失函数,并开始迭代训练
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # record loss # training
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
6.画图,观察损失在不同优化器下的变化
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
输出
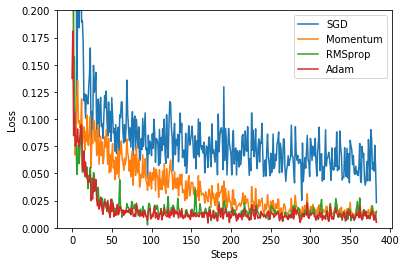
可以看到RMSprop和Adam的效果最好。
pytorch构建优化器的更多相关文章
- [源码解析] PyTorch分布式优化器(1)----基石篇
[源码解析] PyTorch分布式优化器(1)----基石篇 目录 [源码解析] PyTorch分布式优化器(1)----基石篇 0x00 摘要 0x01 从问题出发 1.1 示例 1.2 问题点 0 ...
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
[源码解析] PyTorch分布式优化器(2)----数据并行优化器 目录 [源码解析] PyTorch分布式优化器(2)----数据并行优化器 0x00 摘要 0x01 前文回顾 0x02 DP 之 ...
- [源码解析] PyTorch分布式优化器(3)---- 模型并行
[源码解析] PyTorch分布式优化器(3)---- 模型并行 目录 [源码解析] PyTorch分布式优化器(3)---- 模型并行 0x00 摘要 0x01 前文回顾 0x02 单机模型 2.1 ...
- 【小知识】神经网络中的SGD优化器和MSE损失函数
今天来讲下之前发的一篇极其简单的搭建网络的博客里的一些细节 (前文传送门) 之前的那个文章中,用Pytorch搭建优化器的代码如下: # 设置优化器 optimzer = torch.optim.SG ...
- 【机器学习的Tricks】随机权值平均优化器swa与pseudo-label伪标签
文章来自公众号[机器学习炼丹术] 1 stochastic weight averaging(swa) 随机权值平均 这是一种全新的优化器,目前常见的有SGB,ADAM, [概述]:这是一种通过梯度下 ...
- 『PyTorch』第十一弹_torch.optim优化器
一.简化前馈网络LeNet import torch as t class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__i ...
- Pytorch torch.optim优化器个性化使用
一.简化前馈网络LeNet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 im ...
- Pytorch实现MNIST(附SGD、Adam、AdaBound不同优化器下的训练比较) adabound实现
学习工具最快的方法就是在使用的过程中学习,也就是在工作中(解决实际问题中)学习.文章结尾处附完整代码. 一.数据准备 在Pytorch中提供了MNIST的数据,因此我们只需要使用Pytorch提供 ...
- pytorch 优化器调参
torch.optim 如何使用optimizer 构建 为每个参数单独设置选项 进行单次优化 optimizer.step() optimizer.step(closure) 算法 如何调整学习率 ...
随机推荐
- [Python Study Notes]七彩散点图绘制
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ...
- render tree与css解析
浏览器在构造DOM树的同时也在构造着另一棵树-Render Tree,与DOM树相对应暂且叫它Render树吧,我们知道DOM树为javascript提供了一些列的访问接口(DOM API),但这棵树 ...
- ES01 数据类型、正则表达式、身份证校验
1 基本数据类型 参见W3C的教程即可 2 正则表达式 参考博文:点击前往 3 身份证校验 参考博文:点击前往 <div class="panel panel-primary" ...
- Mongo client - cross-platform MongoDB management tool
Mongo client for Ubuntu or Windows http://robomongo.org/download.html
- php学习笔记-默认参数
在定义函数的时候,我们可以把其中的一个参数变的特殊起来,使它有一个默认值,这个参数就叫默认参数.在调用这个函数的时候,你既可以给这个默认参数传递一个值,这样的话默认参数的值会被覆盖掉,也可以不给它传递 ...
- R: 自动计算代码运行时间
################################################### 问题:代码运行时间 18.4.25 怎么计算代码的运行时间? 解决方案: ptm = pro ...
- win7搭建TensorFlow环境
官网安装指南地址:https://www.tensorflow.org/install/pip 安装过程碰到的问题: 1.创建虚拟环境 virtualenv --system-site-package ...
- c#处理未捕获的异常(UnhandledException)
处理未捕获的异常,放在program类的Main函数下 1.UnhandledException 作用:接收未捕获到的异常 例: static void Main(string[] args) { A ...
- [转]Passing Managed Structures With Strings To Unmanaged Code Part 3
1. Introduction. 1.1 In part 1 of this series of blogs we studied how to pass a managed structure (w ...
- 使用Privoxy转化SSH到HTTP代理
为什么要进行转换? 一般我们很容易找到通过SOCKS5代理的方法,如SSH,但是很多浏览器或是软件只支持HTTP方式,所以就需要将我们的SSH代理模式转为HTTP代理方式 如何转换? 使用Privo ...