java 字符流 字节流
java对文本文档进行操作(拷贝、显示)出现乱码一般来说,可以从两个方面入手。
1、文本文件本身的编码格式。
2、java代码中处理文本文件的编码格式。
这里要注意的一点是,我们可以看出copyFileByByte方法和copyFileByChar1方法都是没有办法设置目的文件的编码格式的,并且处理不好都可能出现乱码,但是需要明确一点的是,copyFileByByte方法拷贝的文件即便出现乱码也可以通过另存为其他格式来调整消除乱码,同样的操作在copyFileByChar1方法拷贝生成的源文件是不能消除乱码的。
假设我们以字节流格式来读取一份utf-8编码格式的txt文档:
package com.audi; import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream; public class ReadFile
{
File fileName = new File("C:/Users/Mike/Desktop/为什么使用接口.txt");
public void readFileByByte()
{
InputStream inputStream =null;
try
{
inputStream = new FileInputStream(fileName);
byte[] temp = new byte[2048];
StringBuilder buf = new StringBuilder(); //非线程安全,不过这里是单线程,无所谓线程安全与否
int length = 0;
while (-1!=(length=inputStream.read(temp)))
{
// 注意下面的代码使用utf-8作为编码格式
buf.append(new String(temp,0,length,"utf-8"));
}
System.out.println(buf.toString()); } catch (FileNotFoundException e)
{
e.printStackTrace();
System.out.println("文件C:/Users/Mike/Desktop/为什么使用接口.txt不存在");
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try
{
if (inputStream!=null)
{
inputStream.close();
}
} catch (Exception e2)
{
e2.printStackTrace();
} } } public void readFileByChar()
{ }
}
文本文件本来的内容为:
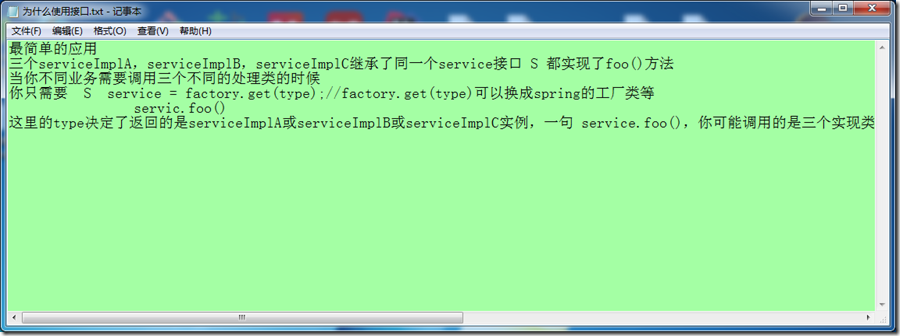
测试代码如下:
package com.audi; public class Test
{
public static void main(String[] args)
{
ReadFile readFile = new ReadFile();
readFile.readFileByByte();
}
}
运行程序读取文本文件得到的控制台输出:
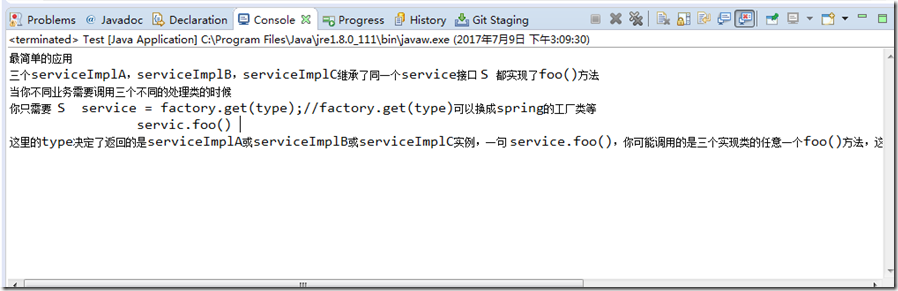
可以看出中文没有乱码,一切正常,如果我们在在上面的代码中不设置解码格式,运行程序,依然正常,这是为什么?
这是因为我的java文件的默认编码格式就是utf-8,所以java代码在编译的时候默认就取了这个格式作为解码格式。
如果换成GBK,那么一样会出现乱码:

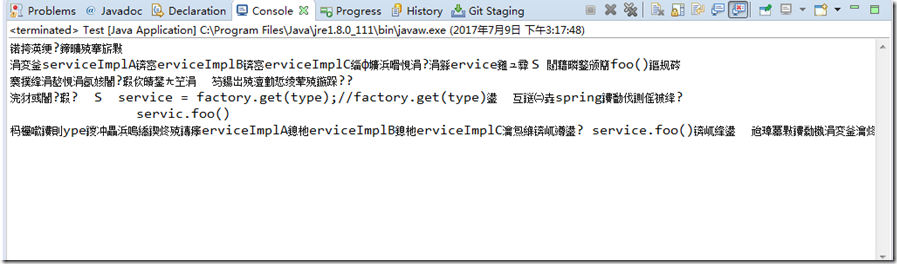
那么如果我们要使用字节流拷贝一份文本文件呢?
java代码如下:
public void copyFileByByte()
{
InputStream inputStream = null;
OutputStream outputStream = null;
File destName = new File("copyFileByByte.txt");
try
{
inputStream = new FileInputStream(fileName);
outputStream = new FileOutputStream(destName);
int length =0;
byte[] temp = new byte[2048];
while (-1!=(length=inputStream.read(temp)))
{
outputStream.write(temp, 0, length);
}
outputStream.flush();
} catch (Exception e)
{
e.printStackTrace();
}
finally {
try
{
if (inputStream!=null)
{
inputStream.close();
}
if (outputStream!=null)
{
outputStream.close();
}
} catch (Exception e2)
{
e2.printStackTrace();
}
}
}
测试代码如下:
package com.audi; public class Test
{
public static void main(String[] args)
{
ReadFile readFile = new ReadFile();
// readFile.readFileByByte();
readFile.copyFileByByte();
}
}
我的实际测试结果是,拷贝后的文件的编码格式是由源文件格式决定的,它会和源文件的格式保持一致。一般不会出现乱码。
下面是使用字符流来操作文本文件。
public void readFileByChar()
{
Reader reader = null;
try
{
reader = new BufferedReader(new FileReader(fileName));
int length =0;
char[] temp = new char[2048];
StringBuilder buf = new StringBuilder();
while (-1!=(length=reader.read(temp)))
{
buf.append(new String(temp, 0, length));
}
System.out.println(buf.toString());
} catch (FileNotFoundException e)
{
e.printStackTrace();
System.out.println("文件C:/Users/Mike/Desktop/为什么使用接口.txt不存在");
}
catch (IOException e) {
e.printStackTrace();
}
}
上面的代码和字节流读取文件不同的是:
1、缓冲数组改成了char[]类型
2、new string构造函数中不能再设定格式,这将会导致它直接使用测试的java文件格式来解码读取的字符流。如下图所示,因为我的txt文档也是utf-8格式的,所以不会出现乱码错误。

测试代码:
package com.audi; public class Test
{
public static void main(String[] args)
{
ReadFile readFile = new ReadFile();
// readFile.readFileByByte();
// readFile.copyFileByByte();
readFile.readFileByChar();
}
}
实际运行效果;
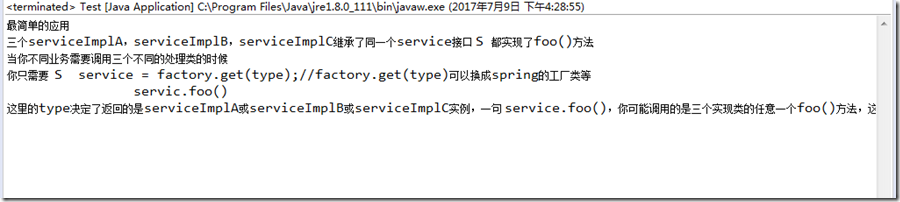
如果把测试java文件的编码格式改为gbk,那么就会出现乱码
下面以字符流方式拷贝文件,同样无法手动设置文件的编码格式:
public void copyFileByChar1()
{
FileReader fReader = null;
FileWriter fWriter = null;
File destName = new File("copyFileByChar1.txt");
try
{
fReader = new FileReader(fileName);
fWriter = new FileWriter(destName);
int length =0;
char[] temp = new char[2048];
while (-1!=(length=fReader.read(temp)))
{
fWriter.write(temp,0,length);
}
} catch (FileNotFoundException e)
{
e.printStackTrace();
System.out.println("文件C:/Users/Mike/Desktop/为什么使用接口.txt不存在");
}
catch (IOException e) {
e.printStackTrace();
}
finally
{
try
{
if (fReader!=null)
{
fReader.close();
}
if (fWriter!=null)
{
fWriter.close();
}
System.out.println("copy succeed");
} catch (Exception e2)
{
e2.printStackTrace();
}
}
}
测试代码,拷贝后文件的格式依然会和测试代码的java文件的编码格式保持一致。
package com.audi; public class Test
{
public static void main(String[] args)
{
ReadFile readFile = new ReadFile();
// readFile.readFileByByte();
// readFile.copyFileByByte();
// readFile.readFileByChar();
readFile.copyFileByChar1();
}
}
这里要注意的一点是,我们可以看出copyFileByByte方法和copyFileByChar1方法都是没有办法设置目的文件的编码格式的,并且处理不好都可能出现乱码,但是需要明确一点的是,copyFileByByte方法拷贝的文件即便出现乱码也可以通过另存为其他格式来调整消除乱码,同样的操作在copyFileByChar1方法拷贝生成的源文件是不能消除乱码的。
下面介绍另外一种方法来拷贝文件,使用的是InputStreamReader和OutputStreamWriter:
public void copyFileByChar2()
{
InputStreamReader inputStreamReader =null;
OutputStreamWriter outputStreamWriter = null;
File destName = new File("copyFileByChar2.txt"); try
{
/*其实只有InputStreamReader和OutputStreamWriter才可以设置编码格式
*
* */
inputStreamReader = new InputStreamReader(new java.io.FileInputStream(fileName),"utf-8");
outputStreamWriter = new OutputStreamWriter(new java.io.FileOutputStream(destName),"utf-8");
int length =0;
char[] temp = new char[2048];
while (-1!=(length=inputStreamReader.read(temp)))
{
outputStreamWriter.write(temp,0,length);
}
} catch (UnsupportedEncodingException e1)
{
e1.printStackTrace();
} catch (FileNotFoundException e1)
{
e1.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
finally
{
try
{
outputStreamWriter.flush();
if (inputStreamReader!=null)
{
inputStreamReader.close();
}
if (outputStreamWriter!=null)
{
outputStreamWriter.close();
}
} catch (Exception e2)
{
e2.printStackTrace();
}
System.out.println("拷贝结束了");
}
}
这个时候拷贝文件的格式完全可控,再也不会依赖测试文件的格式了。
此时,设置源文件UTF-8格式,测试java文件GBK格式:

运行测试代码:
package com.audi; public class Test
{
public static void main(String[] args)
{
ReadFile readFile = new ReadFile();
// readFile.readFileByByte();
readFile.copyFileByByte();
// readFile.readFileByChar();
readFile.copyFileByChar1();
readFile.copyFileByChar2();
}
}
拷贝后的文件,没有出现乱码:
最后,其实我们上面一直在强调都是针对文本文件的操作,那如果是非文本文件呢?
非文本文件☞什么?
严格来说,文件只有两种类型:文本文件(也叫ASCII文件)和二进制文件。
ASCII码: 00110101 00110110 00110111 00111000
↓ ↓ ↓ ↓
十进制码: 5 6 7 8 共占用4个字节。
二进制文件是按二进制的编码方式来存放文件的。 例如, 数5678(五千六百七十八,十进制)的存储形式为:
00010110 00101110(二进制)只占二个字节。
非文本文件我们只能通过字节流来操作,因为字节流虽然也不能设置编解码格式,但是它是一个一个字节读取的,源文件是什么样,拷贝出的文件也是什么样,特定的解码器再去解码就可以了。
字符流就不一样了,它会根据设定的编解码格式的不同,一次读取两个或者三个字节来进行编解码,这样很可能会损坏源文件的编码方式,导致拷贝的文件出错。
java 字符流 字节流的更多相关文章
- Java 字符流实现文件读写操作(FileReader-FileWriter)
Java 字符流实现文件读写操作(FileReader-FileWriter) 备注:字符流效率高,但是没有字节流底层 字节流地址:http://pengyan5945.iteye.com/blog/ ...
- java字符流操作flush()方法及其注意事项
java字符流操作flush()方法及其注意事项 flush()方法介绍 查阅文档可以发现,IO流中每一个类都实现了Closeable接口,它们进行资源操作之后都需要执行close()方法将流关闭 ...
- Java字符流和字节流对文件操作
记得当初自己刚开始学习Java的时候,对Java的IO流这一块特别不明白,所以写了这篇随笔希望能对刚开始学习Java的人有所帮助,也方便以后自己查询.Java的IO流分为字符流(Reader,Writ ...
- java IO之 字符流 (字符流 = 字节流 + 编码表) 装饰器模式
字符流 计算机并不区分二进制文件与文本文件.所有的文件都是以二进制形式来存储的,因此, 从本质上说,所有的文件都是二进制文件.所以字符流是建立在字节流之上的,它能够提供字符 层次的编码和解码.列如,在 ...
- java字符流与字节流的区别是什么
java中字符流与字节流的区别: 1.字节流操作的基本单元为字节:字符流操作的基本单元为Unicode码元. 2.字节流默认不使用缓冲区:字符流使用缓冲区. 3.字节流通常用于处理二进制数据,实际上它 ...
- java 字符流与字节流互转
package test; import java.io.BufferedReader; import java.io.ByteArrayInputStream; import java.io.IOE ...
- Java 字符流操作
上篇文章Java 字节流操作介绍了java中基本的字节流操作,但是我们常常对于字符操作,如果使用字节流来实现输入输出就显得麻烦,我们可以使用字符流来实现对我们看得见的字符char进行操作,主要内容如下 ...
- Java 字符流文件读写
上篇文章,我们介绍了 Java 的文件字节流框架中的相关内容,而我们本篇文章将着重于文件字符流的相关内容. 首先需要明确一点的是,字节流处理文件的时候是基于字节的,而字符流处理文件则是基于一个个字符为 ...
- Java IO流-字节流
2017-11-05 17:48:17 Java中的IO流按数据类型分类分为两种,一是字节流,二是字符流.字符流的出现是为了简化文本数据的读入和写出操作. 如果操作的文件是文本文件,那么使用字符流会大 ...
随机推荐
- angular的$q,defer,promise
$q是Angular的一种内置服务,它可以使你异步地执行函数,并且当函数执行完成时它允许你使用函数的返回值(或异常). 官网:http://docs.angularjs.cn/api/ng/servi ...
- MySQL 数据库备份种类以及常用备份工具汇总
1,数据库备份种类 按照数据库大小备份,有四种类型,分别应用于不同场合,下面简要介绍一下: 1.1完全备份 这是大多数人常用的方式,它可以备份整个数据库,包含用户表.系统表.索引.视图和存储过程等所有 ...
- JSF中使用f:ajax标签无刷新页面改变数据
ajax本是用在前端的一种异步请求数据的操作,广泛用于js中,一般的js框架如jq都有被封装好的方法,用于发起异步请求操作.异步操作可以增强用户体验和操作,越来越多的程序都在使用ajax.JSF的fa ...
- 单端IO标准
单端标准 常用的单端IO标准是LVTTL和LVCMOS. 目前业界绝大部分FPGA/CPLD器件的LVCOMS的IO是由CMOS推挽(push-pull)驱动器构成的,这种结构是上面的PMOS管和下面 ...
- [转载]create_proc_read_entry中函数的说明
原型: struct proc_dir_entry *create_proc_read_entry (const char *name, mode_t mode, struct proc_dir_en ...
- Python:格式化操作符(%)
原文作者:田小计划 原文出处:http://www.cnblogs.com/wilber2013/ (若转载,请标明原文出处) 在编写程序的过程中,经常需要进行格式化输出,每次用每次查.干脆就在这里整 ...
- throw和throws的区别和联系
突然发现今天诗兴大发,看来又得写点内容了. throw和throws对于Java程序员而言它们真的不是很陌生.但对于我这样的选手而言一提到它们的区别和联系就蒙圈了... 为了以后不蒙圈,今天就研究一下 ...
- 2015.7.24 CAD库中列举五字代码点所属航路及终端区图,左连接的累加
select decode(fb.tupr,null,'仅航路',decode(fc.aw,null,'仅终端区','航路及终端区')) 范围,pt 五字代码点,fb.tupr 终端区图及程序,fc. ...
- 2015.1.15 利用Oracle函数返回表结果 重大技术进步!
-- sql 调用 select * from table( get_airway_subpoint(x,x,x)) ///////////////////////////////////////// ...
- [Codeforces]#179 div1-----295ABCDE
摘自我的github:https://github.com/Anoxxx The Solution Source: Codeforces Round #179 (Div. 1) VJudge链接: h ...