基于spark Mllib(ML)聚类实战
写在前面的话:由于spark2.0.0之后ML中才包括LDA,GaussianMixture 模型,这里k-means用的是ML模块做测试,LDA,GaussianMixture 则用的是MLlib模块
数据资料下载网站,大力推荐!!!
http://archive.ics.uci.edu/ml/datasets.html?format=&task=clu&att=&area=&numAtt=&numIns=&type=&sort=nameUp&view=table
1.Kmeans
大致思想就是把数据分为多个堆,每个堆就是一类。每个堆都有一个聚类中心(学习的结果就是获得这k个聚类中心),这个中心就是这个类中所有数据的均值,而这个堆中所有的点到该类的聚类中心都小于到其他类的聚类中心,分类的过程就是将未知数据对这k个聚类中心进行比较的过程。
spark kmeans 算法调用 数据演练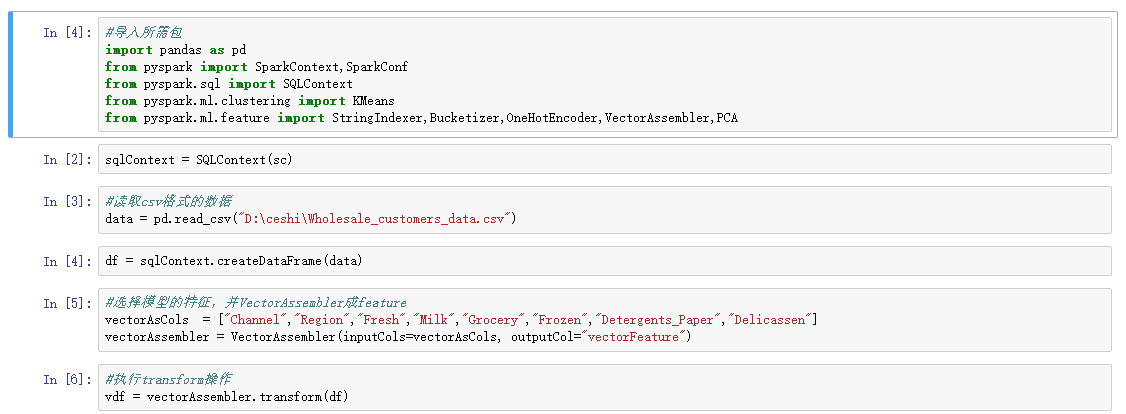
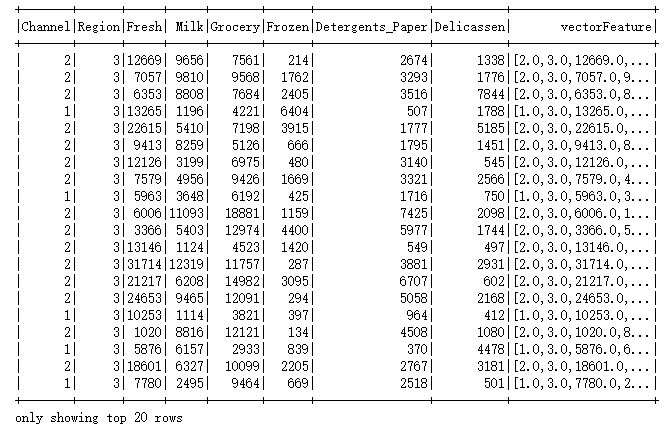
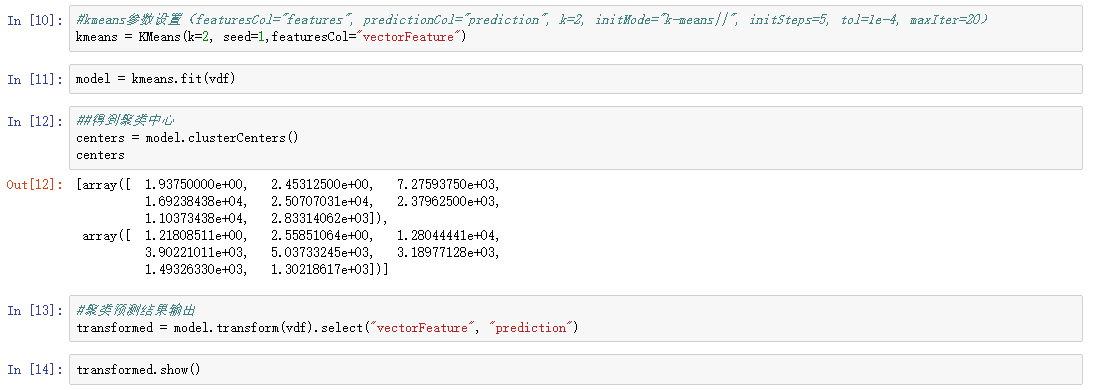

2.GMM
另外一种比较流行的聚类方法 Gaussian Mixture Model
大致思想就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个
Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
spark GMM 算法调用数据测试:
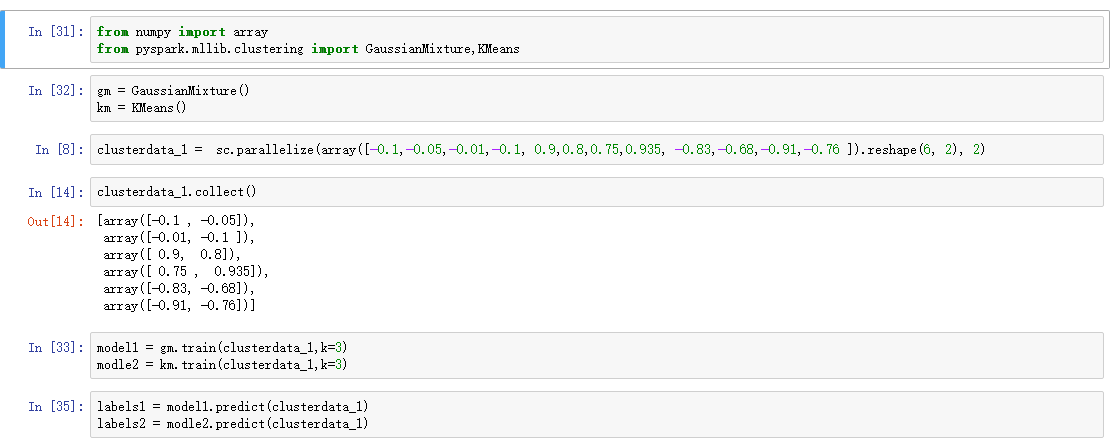

3.LDA

最后总结一下,用GMM的优点是投影后样本点不是得到一个确定的分类标记,而是得到每个类的概率,这是一个重要信息。GMM每一步迭代的计算量比较大,大于
k-means。GMM的求解办法基于EM算法,因此有可能陷入局部极值,这和初始值的选取十分相关了。GMM不仅可以用在聚类上,也可以用在概率密度估计上。
基于spark Mllib(ML)聚类实战的更多相关文章
- 基于Spark Mllib的文本分类
基于Spark Mllib的文本分类 文本分类是一个典型的机器学习问题,其主要目标是通过对已有语料库文本数据训练得到分类模型,进而对新文本进行类别标签的预测.这在很多领域都有现实的应用场景,如新闻网站 ...
- 【spark】spark应用(分布式估算圆周率+基于Spark MLlib的贷款风险预测)
注:本章不涉及spark和scala原理的探讨,详情见其他随笔 一.分布式估算圆周率 计算原理:假设正方形的面积S等于x²,而正方形的内切圆的面积C等于Pi×(x/2)²,因此圆面积与正方形面积之比C ...
- 推荐系统那点事 —— 基于Spark MLlib的特征选择
在机器学习中,一般都会按照下面几个步骤:特征提取.数据预处理.特征选择.模型训练.检验优化.那么特征的选择就很关键了,一般模型最后效果的好坏往往都是跟特征的选择有关系的,因为模型本身的参数并没有太多优 ...
- Spark MLlib KMeans 聚类算法
一.简介 KMeans 算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把分类样本点分到各个簇.然后按平均法重新计算各个簇的质心,从而确定新的簇心.一直迭代,直到簇心的移动距离小于某个给定的值. ...
- Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统
1.前言 上接 YFCC 100M数据集分析笔记 和 使用百度地图api可视化聚类结果, 在对 YFCC 100M 聚类出的景点信息的基础上,使用 Spark MLlib 提供的 ALS 算法构建推荐 ...
- 基于Spark Mllib,SparkSQL的电影推荐系统
本文测试的Spark版本是1.3.1 本文将在Spark集群上搭建一个简单的小型的电影推荐系统,以为之后的完整项目做铺垫和知识积累 整个系统的工作流程描述如下: 1.某电影网站拥有可观的电影资源和用户 ...
- 基于Spark Mllib的Spark NLP库
SparkNLP的官方文档 1>sbt引入: scala为2.11时 libraryDependencies += "com.johnsnowlabs.nlp" %% &qu ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
- Spark MLlib 之 StringIndexer、IndexToString使用说明以及源码剖析
最近在用Spark MLlib进行特征处理时,对于StringIndexer和IndexToString遇到了点问题,查阅官方文档也没有解决疑惑.无奈之下翻看源码才明白其中一二...这就给大家娓娓道来 ...
随机推荐
- 【mysql格式化日期】
date_format(now(),'%Y-%c-%d'): 1. DATE_FORMAT() 函数用于以不同的格式显示日期/时间数据. DATE_FORMAT(date,format) format ...
- UE4简单实现描边高亮效果
材质文件下载地址: 链接:https://pan.baidu.com/s/10HUmXR_YNMOTF-Cg4ybuUg 提取码:m1my 1. 将材质文件放到Content目录中 2. 在项目中添加 ...
- Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 编译安装 1.ELK简介 下载相关安装包地址:https://www.elastic.co/cn/downloads ELK是Elasticsearch+Logstash+Kibana的简称 ...
- python编译环境安装指南
windows系统先安装python解释器: windows版本exe安装文件下载地址:https://www.python.org/ftp/python/2.7.12/python-2.7.12.m ...
- 开发外包注意事项二——iOS APP的开发
目前我的方式是按时间算. 首先这得建立在双方的信任基础上. 以我做过的Case为例: 首先会和客户一起评估需求: 1. 哪些功能是最为重要的 2. 哪些功能是可以删除的 3. 用什么策略保证APP的出 ...
- Python Day23
Django之Model操作 一.字段 字段列表 AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - ...
- poi使用
1.首先需要下载Apache POI 打开poi下载的链接:http://poi.apache.org/download.html ,点击“The latest stable release is ...
- 2、kvm基础常用命令操作
KVM 虚拟机默认的配置文件在 /etc/libvirt/qemu 目录下,默认是以虚拟机名称命名的.xml文件,如下: root@xuedianhu:~# ls /etc/libvirt/qemu ...
- Knight Tournament (set)
Hooray! Berl II, the king of Berland is making a knight tournament. The king has already sent the me ...
- tcp 三次握手,四次挥手几常见面试题
TCP报文首部 源端口和目的端口,各占2个字节,分别写入源端口和目的端口: 序号,占4个字节,TCP连接中传送的字节流中的每个字节都按顺序编号.例如,一段报文的序号字段值是 301 ,而携带的数据共有 ...