Python源码读后小结
Python 笔记
前言(还是叫杂记吧)
- 在python中一切皆对象, python中的对象体系大致包含了"类型对象", "Mapping对象(dict)", "Sequence对象(list, set, tuple, string)", "Number对象(integer, float, boolean)" 以及 "Python虚拟机自己使用的对象"
- 在Python中所有的对象都是一个结构体, 所有对象的父类的结构体是
#define PyObject_HEAD \
int ob_refcount; \
struct ob_type *ob_ref;
typdef struct {
PyObject_HEAD // 在每一个其他的结构体中都定义一个PyObject_HEAD, 为将来的多态打下基础
} PyObject;
- 在Python中的一个整型对象是
typedef struct {
PyObject_HEAD
long int_val;
} PyInt_Object;
在Python中一个Sequence对象是
注意: 由于序列的大小是变化的, 所以有定义一个PyObject_VARHEAD封装了PyObject_HEAD以及序列中元素的大小, 好确定空间
#define PyObject_VARHEAD \
PyObject\_HEAD \
long size;
typedef struct {
PyObject_VARHEAD
} PyStrObject;
- 创建一个对象时, 先创建一个类型对象(类型对象自始至终都是只要一个的, 在C源码中, 就是定义了一个全局的变量), 保存要创建对象的类型信息, 接着再在该类型对象的方法中创建指定的对象, 并将类型对象传递进入最为该对象的属性, 如创建一个int对象, 先PyInt_Type对象创建封装了信息之后再创建PyIntObject对象
- Python相比较于其他语言的好处是其doc文档就在程序之中, 通过PyTypeObject结构体中的doc属性,
可以看到Python之父真的不嫌累, 自己打了那么多的帮助手册的宏
Python中的整型对象
在python中为了提高程序运行的效率, 有小整数池和通用整数池
小整数池
小整数池的范围通过宏来定义的, 默认是-5-257, 我们可以通过修改此处的宏来调整小整数池的大小, 但是需要对python进行重新编译
小整数池是一个静态的数组, 在此数组的基础上又建立了链表
static PyIntObject *small_ints[262]
由此上面的代码可知, 在这个数组中存放是PyIntObject类型的指针, 我们已经知道了在一个PyObject结构体中都有一个PyTypeObject类型的指针,
Python利用这个类型对象充当单向链表的链, 即
value_one_pyobject->ob_type = next_pyobject;
next_pyobject->ob_type = dbnext_pyobject; 注意: 在python程序启动时此整数对象池还没有初始化, 但是一旦初始化了其中一个对象, 则那个对象就会一个存在, 知道程序结束 NOTE!! 在数组上建立的链表是通过一个PyIntBlock结构体和一个PyIntObject *类型的free_list创建的, 我们在创建通用整数池时再讲
通用整数池
通用整数池的实现核心是:
typedef _intblock {
struct _intblock *next;
PyIntObject objects[max_contain];
} PyBlockObject; PyBlockObject *block_list = NULL; // 代表着一个块
PyIntObject *free_list = NULL; // 总是指向在block中维护的数组的下
一个需要被分配空间的位置, 有该free_list调用fill_free_list
函数创建出一个PyBlockObject
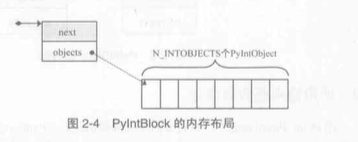
以上是单个block的情况, 其中在objects存储的直接就是一个PyIntObject结构体了
在该结构体中通过ob_type类型的指针形成一个单向链表
以上是多个block的情况, block_list指针总是指向最新生成的block结构体
如果第一个block中的objects的又有了空间的空间了, 为了避免空间的浪费, 在删除那个
对象时, 调用了int_dealloc方法, 有意思的是该方法并不会将空间释放归还给操作系统, 而是继续过该objects数组所有, 在该方法中有一个这样的操作: 因为objects数组也是一个链表, 随意我们可是使用指针进行索引, 在删除一个对象时, 将当期的free_list指针指向该对象所在的空间, 接着让我们删除的对象的ob_type指针指向刚才free_list指向的位置, 总而言之, int_dealloc是一个伪释放函数小整数池的创建
前面已经提到过了, 我们在static修饰的数组中存放整数, 在创建一个PyIntObject对象时, 也是通过block和freelist机制实现的, 首先通过free_list构建出一个可变的链表, 接着该链表中存放的就是
我们需要的PyIntObject结构体, 在数组中存放其引用并指向他即可
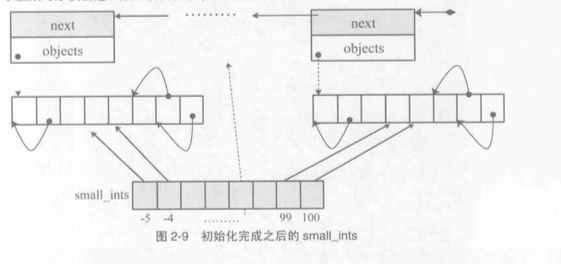
通过上图可知, 在static数组中的指针所执行的结构体分布在在几个个block维护的objects数组中
当一个block中的objects满时再创建next创建整型对象的方法
PyInt_FromLong()
PyInt_FromString(): "123" --> 123
PyInt_FromUnicode()每一个PyObject都有一个hash值, 存储在ob_type指针所指向的结构体中
该结构体中包含了类型信息, 函数族, 变量
字符串
字符串的结构体
typedef struct {
PyObject_VARHEAD
int ob_sstate; // 记录该字符串对象是否纳入了interned(实质上就是一个dict)机制
long ob_shash; // 保存字符串对象的hash值, 默认为-1, 用来缓存一个PyStringObject的hash值
char ob_sval[1]; // 用于存储一个字符, 如果是一个字符串则在该位置多申请空间
} PyStringObject;
字符串的缓冲

以上是PyObject_FromString()函数创建字符串对象的过程

- 先判断字符长度, 如果为1, 则在字符串中的256个字节的缓冲区中找
- 如果大于1, 创建新的字符串对象, 默认是进行interned的, 申请sizeof(PyStringObject) + size个空间, 将需要保存的字符串通过memcpy函数拷贝到ob_sval指针的控制域中
PyStringObject的interned机制的实现


使用"+"可以对字符串进行连接, 但是需要向system频繁地申请空间, 效率低
官方建议使用"string".join(str)的形式, 只想内存申请一块大的空间
因为:PyStringObject是不定长且不可变的
列表对象
python中的列表对象与C++中的vector对象实现是一样的
列表的结构体
typedef struct {
PyObject_VARHEAD
PyObject *item; // 存储PyObject*的数组指针
int size; // 元素数量
int allocted; // 最大容量
} PyListObject;
对列表进行插入, 删除的操作对应的C语言函数为SetItem, GetItem
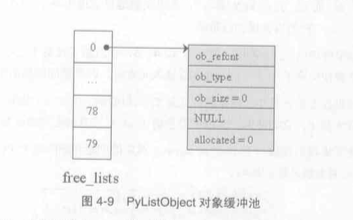
为了加快程序运行的速率, Python对List对象使用了缓冲, 有一个free_lists数组, 用来存放已经被删除的List对象, 其中的item, size, allocted为NULL, 0, 0, 有num_free_lists整数型变量用来记录在free_list中空闲的List个数, 每一次创建List对象时都会先判断num_free_lists的值是否为0, 如果为0, 则向内存申请空间创建一个PyListObject, 否则则直接获取在free_lists中的空间的PyListObject对象!
细说SetItem
在List中删除一个元素, 如果使用了如下的代码
>>> lst = [1, 2, 3, 4]
>>> lst[1:3] = []
>>> lst
>>> [1, 4] >>> lst[0:] = [2, 3]
>>> lst
>>> [2, 3]
其中在Python中SetItem有进行判断, 如果传入的PyObject为NULL则为删除元素
如果传入的不为空则替换之为了节省内存空间, 在插入一个元素的时候, 如果size < allocted / 2, 则压缩空间
如果allocted / 2 <= size <= allocted 则直接插入, 必要时进行realloc(类似vector)在PyListObject中的ob_type指针所执行的结构体中的ob_free函数并不会将内存归还OS, 而只是进行了清理操作
dict
结构体
typedef struct {
PyObject_HEAD
int fill;
int used;
int mask;
PyDictEntry *table; // 在PyDictObject中存放的元素较多时使用
PyDictEntry *(*lookup)(PyDictObject *self, PyObject *key, long hash) // 冲突链上的搜索函数
PyDictEntry *small_table[8]; // 一个存放PyDictEntry的数组, 在PyDictObject中存放的元素较少时使用
} PyDictObject; typedef struct {
long hash; // 缓存对象的hash值
PyObject *key;
PyObject *value;
} PyDictEntry; // 在Python中不是对象
内存图
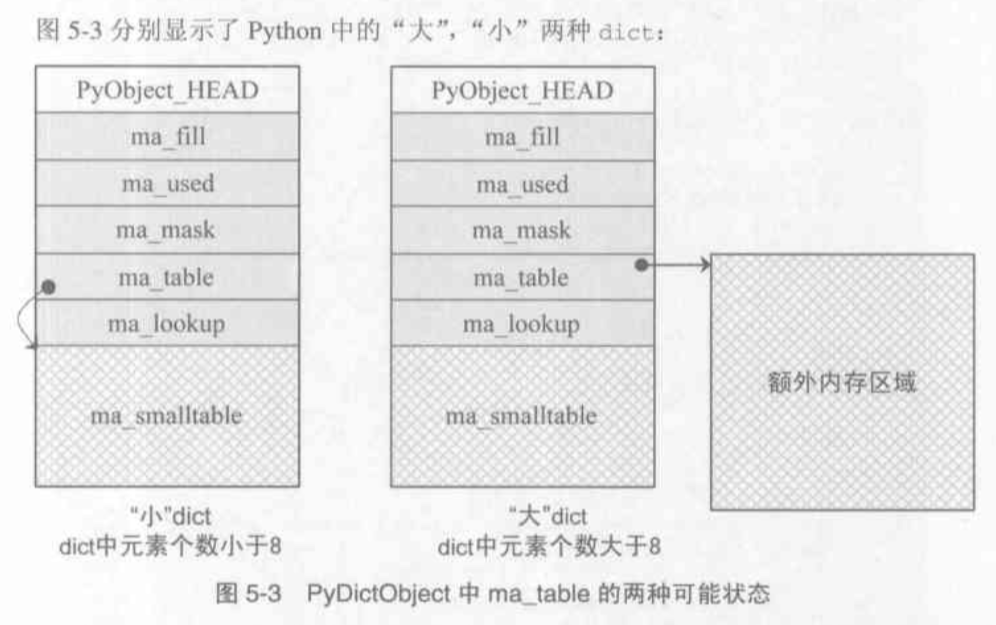
2. 注意: 在PyDictObject中存放是Entry, entry中存放的是键值对
3. Java中的dict使用的是"数组 + 链表", 而在Python中使用的是"开放地址法", 如果发生了冲突则在调用PyDictObject的lookup方法寻找下一个符合条件的位置, 返回一个可用的Entry, 对其进行赋值
4. Dict也采用了类似List的对象缓冲池, 此池在一开始时什么也没有, 只有在一个Dict对象销毁时才会有一个元素, 使用num_free_dict, free_dicts数组
- 作用
PyDictObject在python中用处极为广泛, 我们在python脚本中定义一个a = 1,
对应在C源码中就是根据整数1创建一个PyIntObject对象, 并将"a"字符串最为key, PyIntObject指针作为value存入到一个EnvironmentDict中, 这样python在访问变量a时就有了依据, 只需要从EnvironmentDict中以"a"为键找value, 其中"a"已经被hash过了
Python虚拟机
PyCodeObject
PyCodeObject是通过Scanner, Parser编译生成的, 存在于内存中的对象, 在Python脚本中一个名字空间对应一个PyCodeObject对象, 一个PyCodeObject对象可能会嵌套一个小的PyCodeObject对象, python编译生成PyCodeObject对象并将其写入到硬盘中named .pyc, 用于之后的加快速度, 该文件主要包括magic number, python source code created date, PyCodeObject byte
magic number: 用于解决python版本之间的兼容问题
date: 用于判断是否需要重新编译源文件
pycodeobject: 最重要的一部分, 存放的源代码的信息, 存放着让python虚拟机运行的执行集合
注意: 在PyCodeObject中不会保存List对象, 而是保存其中的值
PyFrameObject
PyFramObject是一个执行环境, 每调用一个函数就会创建一个PyFrameObject对象, 其中包含了PyCodeObject, 总而言之, 一个PyFrameObject对应一个PyCodeObject, PyFrameObject类似于OS的函数压栈, 有一个f_back用于保存之前函数调用的位置, 在当前函数执行完毕之后就回到原来的函数的栈位置python代码的执行就是在这个PyFrameObject中执行的, pythonVM通过PyFrameObject对象中保存的PyCodeObject来执行Python字节码, 并且命名空间也与PyFrameObject有关, 其有locals, globals, builtins字典(查找次序是local, global, builtin, 对于module来说, local与global是一样的), 用于保存对应的域的名字, local就是当前的frame中的变量, global就是当前模块中在函数之外定义的变量
python虚拟机并不是直接对PyCodeObject进行直接的操作, 而是以PyFrameObject对象为参数获取他的属性PyCodeObject, 通过CodeObject中的code, first, next, last来操作code字符串数组的执行, 通过一个for(;;)循环中套着一个巨大的switch case语句, 可以说这就是一个python虚拟机了, 就是这么一个函数而已
RuntimeEnvironment
其中的系统栈是python虚拟机提供的
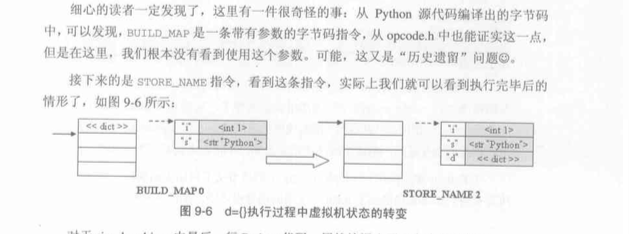
以上就是python虚拟机根据字节码执行在栈和local名字空间之间的转换, 最后的栈会变为空栈, 而存储在了local的字典中, 首先根据python虚拟机自己认可的字节码创建PyObject对象(int, string等), 压入栈, 接着在放到local中
字节码的读取顺序一般是自左向右Python虚拟机的字节码
BUILD_MAP: 背后对应的case内容是创建一个map
BUILD_LIST: 创建一个list
POP: 出栈
TOP: 返回栈顶的元素, 但是不出栈
LOAD_NAME: 根据指定的的变量名字符串, 在local中搜索指定到对应的Object并压栈
STORE_NAME: 将栈中的object弹出并存放到local中 对于迭代的语句
都会先进行SET_LOOP: 正式进入到循环中
接着在迭代list时会从PyFrameObject中得到PyTryBlock, 该PyTryBlock也是PyObject对象, 他里面存放的是python虚拟机的状态信息, 在ListObject中的ob_type指向的类型对象中存放这一个listiterobject对象, 获取该对象, 该iterobject对象中封装了一个调用他的ListObject, 并且有一个int类型的变量存放元素在ListObject中的位置, 这样这个迭代器就可以迭代ListObject中的元素了, 迭代完了之后, 将栈恢复到迭代之前(python根据PyTryBlock恢复的)
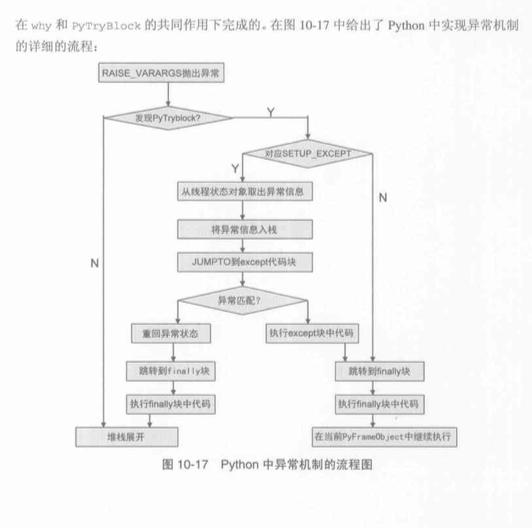
Python中的异常处理机制
比如在遇到ZeroDivError异常时, 虚拟机会判断被除数是否为0, 如果为0则break出虚拟机中的switch-case语句(这样python虚拟机不就停止了吗? 其实python虚拟机的这个函数是一个递归调用的函数, 调用一次python中的函数就会创建一个PyFrameObject对象, 而FrameObject又会对应一个递归地Python虚拟机的PyEval_EvalFrame_Exc函数, 该这个Frame中的Eval函数只执行该Frame对应的那那些指令, 这样就不会断掉了, 成为栈展开), 并将当前的异常对象一起报错的异常信息存储到当前对应的线程状态对象中去
在虚拟机初始化环境的时候, 一开始_PyThreadState_Current = NULL, 后来通过PyTread_New返回一个PyTheadState对象赋值给_PyThreadState_Current, 用来当做当前的线程, 而PyThreadState_GET就是一个(_PyThreadState_Current)内容的宏python虚拟机异常的处理
python中的函数(PyFunctionObject)的调用机制, 其中用的命名空间是他维护的PyCodeObject中的globals, 在执行函数时会创建一个PyFrameObject, 它会取出PyFunctionObject中维护的PyCodeObject中的globals

python解释器在遇到def语句时就会创建一个PyFuncObject对象, 保存相应的参数信息(有参数或者没有参数), 接着在调用该函数时, 会将funcobject加载到运行时栈(所谓运行时栈, 顾名思义就是python程序在执行时的一个计算空间, 所有的加减乘除, 方法的调用都要在运行时栈中完成, 而数据的存储则在别处)中, 在将参数自左向右入栈, 因每一个函数会对应一个比他大一个的PyFrameObject, 所以在call_function函数中就会创建一个维护当前FunctionObject的FrameObject, 接着将栈中的参数都移动到栈的开头的再上面的位置, 比如叫对
a += 2, 则将a对象压入到栈中, 计算完结果在将结果更新到栈之前的a对象的位置, 完成计算

其他类型的参数就不提了
注意: python在指定def func(a, name=[]): 时, 编译器会将func, a, name, []都存起来, 这里的[]存了起来, 就产生了陷阱了
Python虚拟机中的类机制
- 在Python2.2之前, 内置的对象, 也就是有Guido自己定义的在Python虚拟机初始化完成之后就被创建的类型对象是不可以被继承的, 如int, list等, 比如
class A(int):
def __add__(self, value):
return 10
当使用a + a1时会报错, 因为python虚拟机不能知道该方法, 虽然继承过来了
在Python2.2之后, 为PyTypeObject添加了tp_dict属性, 该属性表示一个dict对象, 在编译时
并没有确定他保存的元素, 而在Python虚拟机在执行字节码指令时就会初始化这些对象, 首先创建dict,
里面的entry是类似于"__add__":PyIntObject中的NumbersMethods结构体中的int_add函数执行的地址, 这样一步一步的初始化, 当然在初始化时采用了和Java一样的机制, 动态加载, 在初始化一个PyTypeObject类型的对象的实例时, 会先判断该实例的父类是否初始化完成, 如果没有则递归调用初始化函数来初始化父类的dict, 这里的初始化对象指的都是PyTypeObject, 所以一般其父类都是为NULL, 只有个别的如PyBoolTypeObject的实例的base是PyIntTypeObject, 这样以后再调用方法时就可以有两种方式调用了, 不过我们在C源码级别还是只有一种方式, 因为他是动态生成的dict!, 这样在a + a1时, 会自动调用__add__函数, 而虚拟机遇到__add__函数就会调用A类重写了的__add__函数, 总之可以调用而不会出错

以上为类之间的关系, 其中最右侧时示例对象, 他们真的是纯粹的实例对象, 而中间的class对象, 即是类型, 因为通过他们可以new出实例对象来, 还是type类型的实例对象, 因为他们都是通过最右侧的type类型创建的, 所有的类型的基类都是object, type也是object的子类
我们来梳理一下:
instance对象:
C源码级别:
PyStrObject结构体创建出来的对象, PyIntObject..., PyListObject...
Python源码级别:
"Hello world", 1, [1, 2, "Hello world"]
class对象:
C源码级别:
PyIntObject, PyStrObject, PyListObject
他们每一个都是单例的, 通过PyType_Type结构体创建出来的
对应在Python源码级别:
int, str, list
type类型:
C源码级别:
PyType_Type
Python:
type
上面提到的动态的填充tp_dict, 我们再联系一下Python中的an_instance.__dict__, 发现这两个东西的名字特别的相似, 其实我们通过an_instance.__dict__显示的东西就是这里tp_dict中维护的值
当我们使用"asd".__class__, 在python源代码中就是获取strobj->ob_type对象
在class中每一个Codeblock中定义的都是该class的属性, 也就是A.__dict__中显示的内容, 包括函数和类中的全局变量, 而在函数中定义的属性
比如
def __init__(self):
self.value = "value"
则是给了该class创建的instance的对象中的__dict__
继承的实现
创建class对象时,
遇到class语句, PVM会调用该class所在module对应的PyCodeObject中的co_code维护的字
节码, 加载class, 虽然class的声明和实现在逻辑上是一体的, 但是在PyCodeObject中是分开来存放的, 这与function_object是一样的, 在moduel中的codeobject中维护的指令集合中只有
class的声明的指令, 加载一些参数, 而在functionObject中也是如此, 之后转向class名字空间对应
的codeobject, 指令里面的指令真正的创建一个class对象, 在C层次上就是类似于PyType PyStrObject = {};
在执行声明class的指令时, PVM会根据继承的对象, 实现MRO机制
Python对于int, str等内置对象采用的静态的方式创建的, 就是PyType_Type PyStrType = {...};
而用户定义的class对象就不是动态生成的了, 也就是说我们不能和str类型对象的创建一样, 直接使用一个大括号括起来, 在里面赋值
而是PyType_Type user_define_type;
user_define_type.tp_name = "Person"; // 你懂的, 就是class Person(object):中的"Person"
user_define_type.tp_type = &PyType_Type;
user_define_type.bases = some;
user_define_type.tp_as_numbers = numbers;
user_define_type.tp_as_sequence = sequences;
user_define_type.tp_as_mappging = mappgings;
还有一些函数就从父类中获取了, 因为用户定义的结构体有一个bases, 通过他我们就可以访问到父类的函数了, 这样一直延伸到object类型对象
要调用子类没有而父类有的方法, 需要去到父类中的dict中维护的"函数名":函数, 中找, 找到就调用
```



Python虚拟机初始化
1. Python虚拟机初始化的时候会创建许多的内置模块, 首先创建的就是__builtin__ module, 其实我们当前的文件就是一个module, 在Python内置对象中有一个进程对象, 里面维护了一个modules的map,
它是由来存储所有模块的名字和模块对象键值对的, 因为每一个module又会有一些函数, 属性等等, 所以在每一个模块对象中又会有一个map, 用来存储module中的键值对, 对于__builtin__ module来说, Python
虚拟机首先创建出一个空的ModuleObject, 接着让里面填充域和其他信息, 我们知道在使用Python时有一些内置的函数, 比如len, dir等等, 这就是填充的内容, 以键值对的形式填充: "add":AddFunctionObject, 等等, 调用add方法时其实就是内置的每一个python对象都遵守了add函数调用的协议:)
注意: 这里内置的add, len函数, 在Python源码中时PyMethodDef, 反正只要是内置的东西, 他就和我们使用python编写的函数或者对象本质上就是不一样的, 比如一个"abc"的字符串对象, 我们查看"abc".__add__, 显示的是<method-wrapper '__add__' of str object at 0x106cc7308>, 而我们定义一个class A对象, 里面添加一个__add__函数, 而A.__add__显示的是<function __main__.A.__add__(self)>, 虽然我们定义的class A对象遵守了"+"的协议, 定义a = A(), b = A(), a + b 时会自动调用__add__, 但是这时的__add__已经和内置的不一样了
注意: sys.modules是全局名字空间, 这里的全局是指一个Python进程, 并且全局名字空间不会受import ... as ... 语句中重命名的影响, 其实sys.modules叫做modules pool
2. Python除了会加载__builtin__ module, 还有加载一个非常重要的module, 就是我们常用了sys module, 这也模块中sys.path可以查看python的查找路径, sys.modules显示所有已经加载到内存中的
module
注意: 一开始我们会以为python只是加载了__builtin__到内存中, 其实并不是这样的, python在初始化的时候就已经加载了大量的内置module到内存中, 只是没有显示出来而已, 也就是没有在命名空间中
显示, 我们知道, 我们要访问一个对象, 就是从命名空间去找, 所以现在使用不了那么多已经加载到内存中的内置模块, 而使用了import关键字加载内置模块时, python会直接从内存中找到那个module对象, 将他
的引用返回, 并且放在用户可以访问到的名字空间中, 不管是import内置模块还是用户自定义的模块, 都会更新sys.modules这一个全局模块的名字空间, 如果重复导入一个模块, 只需要从sys.modules中放回那个
模块就行了, 这就是python防止重复导入的原理
3. import加载一个package(一个文件夹)时, import pacname.some, 我们只是想要加载some文件, 但是python会一同将pacname也加载进来, 是想一个下, 我们是怎么访问some, 是通过pacname.some,
由此可见我们使用该some时是需要pacname, 所以加载包对python来说是必须的, 这是的some不在local名字空间中, 而是在pacname的属性中
4. 如果我们需要只加载我们需要的, 则使用from ... import , 但是实质上还是同第3点是一样的, 还是会加载pacname, 但是some也会被放在locals名字空间中, 并将其映射为pacname.some, 通过from我们
可以做到精准加载
5. 使用del语句删除一个module, 其实只是删除了其符号在当前名字空间的位置位置, 在全局的module pool中还是存在的, 所有就算删除了, 我们还是可以在module pool中找到该对象
6. 使用reload(module)函数可以对一个模块进行动态加载(或者说是更新), 如果在一个模块中添加了 a = 10, 则调用了reload时, 就是在该module维护的dict中添加一个键值对, 而不是
重新创建一个module对象,
Python中的PyCFuncObject(内置的函数len, dir, 都是这个数据结构), PyMethodObject, PyMethodDef(内置对象的方法都是这个数据结构)
在Python中内置对象中的方法与用户自定义的方法是不同的数据结构, 用户自定义的类中的方法都是PyMethodObject数据结构, 而内置的对象(int, str, list, dict)则是使用了PyCFuncObject和PyMethodDef来实现的, 首先PyMethodDef封装了PyCFuncObject, 而PyCFuncObject中有一个指针指向了那个PyMethodDef
注意: 以上实质对非魔法内置函数的讨论
对于一个list实例lt, lt.append(1), 就会遍历list中methoddef数组, 找到名为'append'的methoddef, 取出对应的PyMethodDef, 再获取其中的PyFuncObject, 得到已经内置好的append函数指针, 调用该函数即可
而对应一个用户自定义的class, 调用方法a, 也会查找字典, 找到'f', 取出对应的PyMethod, 里面维护这codeobject, 根据其中的字节码执行逻辑, 如果没有重写内置父类方法的话则还是上述的过程
对于魔法方法或函数:
Python采用的是slotdef与descriptor的组合, slotdef中封装了__add__字符串对应的函数指针, 而descriptor封装了slotdef, 访问__add__方法时, 通过__add__字符串找到descriptor, 接着访问其中的函数指针, 调用即可。 注意: 该模式是为了用户可以继承内置对象, 在2.0之前是不能继承内置对象的, 因为如何访问函数指针会出现问题, 所以在2.2只有加入了tp_dict专门来解决内置的魔法方法的调用, 而其他的内置对象的非魔法方法已经在原始版本的python中通过MethodDef和MemberDef数组解决了, 里面存储了名字和PyCFuncObject(维护这函数指针)
Python源码读后小结的更多相关文章
- webbench1.5源码读后总结
webbench简介 webbench由C语言写成的用于网站压力测试的一个非常简单的工具,它最多可以模拟30000个并发连接去进行测试. webbench的安装和使用可以自行百度,也可以过下这篇文章. ...
- 读python源码--对象模型
学python的人都知道,python中一切皆是对象,如class生成的对象是对象,class本身也是对象,int是对象,str是对象,dict是对象....所以,我很好奇,python是怎样实现这些 ...
- Python源码剖析——02虚拟机
<Python源码剖析>笔记 第七章:编译结果 1.大概过程 运行一个Python程序会经历以下几个步骤: 由解释器对源文件(.py)进行编译,得到字节码(.pyc文件) 然后由虚拟机按照 ...
- VS2013编译python源码
系统:win10 手头有个python模块,是用C写的,想编译安装就需要让python调用C编译器.直接编译发现使用的是vc9编译,不支持C99标准(两个槽点:为啥VS2008都还不支持C99?手头这 ...
- 三种排序算法python源码——冒泡排序、插入排序、选择排序
最近在学习python,用python实现几个简单的排序算法,一方面巩固一下数据结构的知识,另一方面加深一下python的简单语法. 冒泡排序算法的思路是对任意两个相邻的数据进行比较,每次将最小和最大 ...
- 转换器5:参考Python源码,实现Php代码转Ast并直接运行
前两个周末写了<手写PHP转Python编译器>的词法,语法分析部分,上个周末卡文了. 访问器部分写了两次都不满意,没办法,只好停下来,参考一下Python的实现.我实现的部分正好和Pyt ...
- 类似py2exe软件真的能保护python源码吗
类似py2exe软件真的能保护python源码吗 背景 最近写了个工具用于对项目中C/C++文件的字符串常量进行自动化加密处理,用python写的,工具效果不错,所以打算在公司内部推广.为了防止代码泄 ...
- Python源码中的PyCodeObject
1.Python程序的执行过程 Python解释器(interpreter)在执行任何一个Python程序文件时,首先进行的动作都是先对文件中的Python源代码进行编译,编译的主要结果是产生的一组P ...
- 【转】类似py2exe软件真的能保护python源码吗
类似py2exe软件真的能保护python源码吗 背景 最近写了个工具用于对项目中C/C++文件的字符串常量进行自动化加密处理,用python写的,工具效果不错,所以打算在公司内部推广.为了防止代码泄 ...
随机推荐
- android studio中配置X5 webview时的一个坑
在接入X5的第二步中,需要配置so文件,这里说一下遇到的坑 1. 需要把demo下载回来,不然你找不到so文件,找到so文件后放到自己相对应的目录下边,自己里面那个目录也没有,所以和文件夹一起复制过去 ...
- 【C#】如何打开Model Browser(实体数据模型浏览器)
Visual Studio 2017 如何打开Model Browser(实体数据模型浏览器) 2017-10-11 十有三 2 浏览:4956 开发工具 Visual Studio 做个笔记,记录下 ...
- Android按钮单击事件处理的几种方法(Android学习笔记)
方法一:匿名内部类实现按钮事件处理 this.btnButton=(Button)super.findViewById(R.id.mybtn); this.btnButton.setOnClickLi ...
- myql 服务启动不了怎么办
今天,不小心手动将mysql 服务停掉后,怎么也启动不了,后面查了半天 ,终于知道要先将任务管理器里的mysql.exe 先Kill掉,然后可以启动了,记录一下
- [Django笔记] 从已有的数据库构建应用
Django适合从零开始构建,所谓 'Green-field' 开发.那么当我需要基于已存在的数据库构建应用时怎么办呢? inspectdb # 扫描默认数据库 python manage.py in ...
- P4332 [SHOI2014]三叉神经树
\(\color{#0066ff}{ 题目描述 }\) 计算神经学作为新兴的交叉学科近些年来一直是学术界的热点.一种叫做SHOI 的神经组织因为其和近日发现的化合物 SHTSC 的密切联系引起了人们的 ...
- centos上安装docker
一 docker安装: 1 首先需要检查linux内核的版本,docker要求linux内核是在3.10之上的, uname -r 2 更新yum源,注意这步应该是管理员权限,如果当前不是管理员,切换 ...
- 【实例分割】PANet简单笔记
PANet是18年的一篇CVPR,作者来自港中文,北大,商汤与腾讯优图,PANET可看作Mask-RCNN+,是在Mask-RCNN基础上做的几处改进. 论文地址:https://arxiv.org/ ...
- 什么是Uboot
U-Boot的全称是Universal Boot Loader,遵循GPL条款的开放源码项目. U-Boot的作用是系统引导. U-Boot目前不仅仅支持嵌入式Linux系统的引导(对Linux的支持 ...
- 主席树的各类模板(区间第k大数【动,静】,区间不同数的个数,区间<=k的个数)
取板粗 好东西来的 1.(HDOJ2665)http://acm.hdu.edu.cn/showproblem.php?pid=2665 (POJ2104)http://poj.org/probl ...