HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要
最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowKey中显然不太可能),或者全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题
查询需求
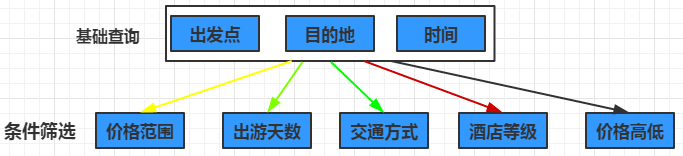
多个查询条件构成多维度的组合查询,需要根据不同组合查询出符合查询条件的数据
HBase的局限性
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难(如:对于价格+天数+酒店+交通的多条件组合查询困难),全表扫描效率低下。
二级索引的设计
设计思路
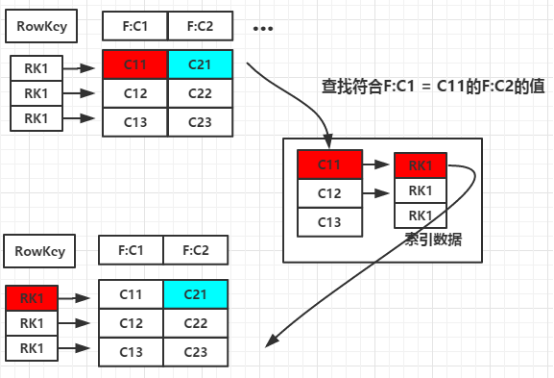
(图1)设计思路
二级索引的本质就是建立各列值与行键之间的映射关系
如(图1),当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)其查询步骤如下: 1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1 2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
逻辑视图
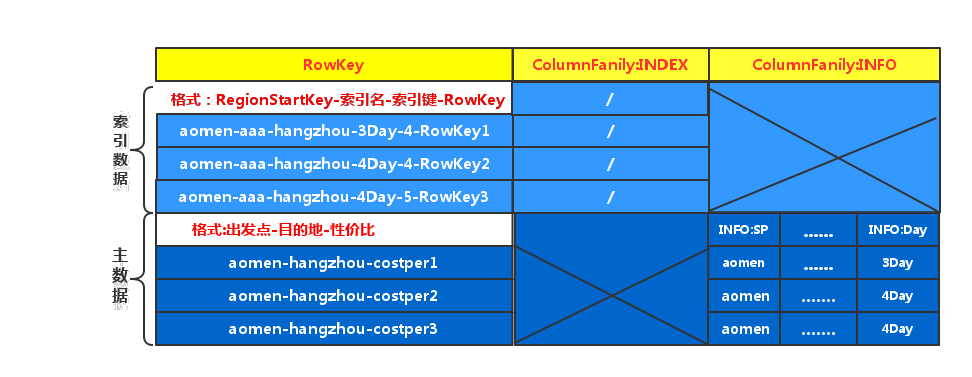
(图2) 部分数据在HBase中存储的逻辑视图
表中有两个列族,其中一个是列族INDEX,其并不存储任何的数据,仅仅是为了将索引数据与主数据分开存储(因为在HBase中同一列族的数据会被压缩在一起存储),索引数据的行键格式为:RegionStartKey-索引名-索引键-Rowkwy,其他RegionStartKey就是出发点,因为在创建HBase表时就对表根据出发点进行了预分区,索引键为主数据中某列(可能是多列)的列值,Rowkey对应主数据的行键;主数据的行键格式为:出发点-目的地-性价比,所以在存储数据时,同一出发点 目的地的数据默认是按性价比排序的;索引数据的行键和主数据的行键的前缀都是出发点,所以在存储时相同出发点的索引数据和主数据是存储在同一个Region中的,这样避免了在通过索引得到RK后又去其他Region上查询目标数据,提高了查询效率。
数据的查询过程
假设查询的条件:
出发点:澳门
目的地:杭州
出游天数:3天
酒店等级:4
其查询步骤如下:
首先根据查询条件来确定索引名,根据其查询条件为出游天数据 酒店等级确定索引名为aaa,这样就将查询的范围缩小在索引名为aaa的索引数据区内
根据出游天数的值为3天,酒店等级的值为4,结合Phoenix的模糊查询就能确定符合这两个查询条件的索引数据的行键
得到索引数据行键后就截取其最后的RowKey
最关键的Rowkey得到后就能轻易的获得其对应的列值了,整个查询过程就结束了。
对于其他更为复杂的组合查询的二级索引设计如类似。
缺点
需要额外的存储空间,属 一种以空间换时间的方式。
注意
1.将查询条件中的可选字段转换成数字能节省存储空间,如交通工具中的飞机,高铁,火车,轮船,汽车分别转换成5,4,3,2,1
2.将汉字转换成拼音才能保证数据按HBase的排序规则排序
3.如果数据量在百万级别以下可使用Phoenix(HBase的SQL查询引擎)模糊查询功能减少索引行键的设计
参考资料
apache kylin思路类似
HBase之八--(1):HBase二级索引的设计(案例讲解)的更多相关文章
- HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
- phoenix连接hbase数据库,创建二级索引报错:Error: org.apache.phoenix.exception.PhoenixIOException: Failed after attempts=36, exceptions: Tue Mar 06 10:32:02 CST 2018, null, java.net.SocketTimeoutException: callTimeou
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- hbase基于solr配置二级索引
一.概述 Hbase适用于大表的存储,通过单一的RowKey查询虽然能快速查询,但是对于复杂查询,尤其分页.查询总数等,实现方案浪费计算资源,所以可以针对hbase数据创建二级索引(Hbase Sec ...
- Phoneix(三)HBase集成Phoenix创建二级索引
一.Hbase集成Phoneix 1.下载 在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本. ...
- HBase的二级索引
使用HBase存储中国好声音数据的案例,业务描述如下: 为了能高效的查询到我们需要的数据,我们在RowKey的设计上下了不少功夫,因为过滤RowKey或者根据RowKey查询数据的效率是最高的,我们的 ...
- hbase构建二级索引解决方案
关注公众号:大数据技术派,回复"资料",领取1024G资料. 1 为什么需要二级索引 HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索.假设我们相对Hbas ...
- [转]HBASE 二级索引
1.二级索引的核心思想是什么?2.二级索引由谁来管理?3.在主表中插入某条数据后,hbase如何将索引列写到索引表中去?4.scan查询的时候,coprocessor钩子的作用是什么?5.在split ...
随机推荐
- 3.Pycharm和navicate的使用
Pycharm的下载 进入到Pycharm官网,进入网页的最下边,下载企业版enterprise(可试用30天),企业版提供了创建项目.run等功能,而免费版没有这些功能 pycharm的使用: 在f ...
- delphi中httpencode使用注意事项
delphi中httpencode使用注意事项 一.uses HTTPApp二.使用前要用UTF8Encode转换成utf-8编码HTTPEncode(UTF8Encode(Text));不然和标准的 ...
- 剑指Offer——圆圈中最后剩下的数(约瑟夫环)
Question 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏.其中,有个游戏是这样的:首先,让小朋友们围成一个大圈.然后, ...
- QT 中一些数学计算函数
QT的一些範例中有出現 qmax, qmin 等 math函式的身影,但我在官方文件中卻找不到與 math函式相關的說明,所以我就把函式的source裡面提供的方法整理條列,並且看看還有哪些 math ...
- dubbox 学习
目录 编译源码 发布dubbo的jar包到私库 安装dubbo-admin 安装monitor Springboot+dubbox 其他 编译源码 dubbox是没有安装包的,所以我们只能先下载源码 ...
- numpy array转置与两个array合并
我们知道,用 .T 或者 .transpose() 都可以将一个矩阵进行转置. 但是一维数组转置的时候有个坑,光transpose没有用,需要指定shape参数, 在array中,当维数>=2, ...
- ceilometer alarm 创建过程中的DB操作及优化
创建一个ceilometer alarm需要4次DB操作: api/controllers/v2/alarms.py 1. is_over_quota 每一次都需要查询该user/project的所有 ...
- Java-集合类源码List篇(三)
前言 前面分析了ArrayList和LinkedList的实现,分别是基于数组和双向链表的List实现.但看之前那张图,还有两个实现类,一个是Vector,另一个是Stack,接下里一起走进它们的源码 ...
- 代码题(59)— 字符串相加、字符串相乘、打印最大n位数
1.415. 字符串相加 给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和. 思路:和链表相加类似,求进位. class Solution { public: string addS ...
- poj 2513 欧拉图/trie
http://poj.org/problem?id=2513 Colored Sticks Time Limit: 5000MS Memory Limit: 128000K Total Submi ...