图文了解 Kafka 的副本复制机制
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。
Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集群上不同大小的工作负载,调整 Kafka replication 以让它适用不同情况在今天来看是有点棘手的。使这点特别困难的挑战之一是如何防止副本从同步副本列表(也称为ISR)加入和退出。从用户的角度来看,这意味着如果生产者(producer )发送一批“足够大”的消息,那么这可能会导致 Kafka brokers 发出多个警报。这些警报表明某些主题“未被复制”(under replicated),这意味着数据未被复制到足够多的 brokers 上,从而增加数据丢失的可能性。因此,Kafka cluster 密切监控“未复制的”分区总数非常重要。在这篇文章中,我将讨论导致这种行为的根本原因以及我们如何解决这个问题。
一分钟了解 Kafka 复制机制
Kafka 主题中的每个分区都有一个预写日志(write-ahead log),我们写入 Kafka 的消息就存储在这里面。这里面的每条消息都有一个唯一的偏移量,用于标识它在当前分区日志中的位置。如下图所示:
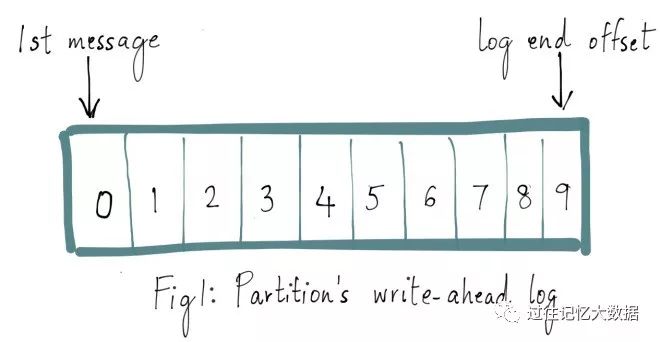
Kafka 中的每个主题分区都被复制了 n 次,其中的 n 是主题的复制因子(replication factor)。这允许 Kafka 在集群服务器发生故障时自动切换到这些副本,以便在出现故障时消息仍然可用。Kafka 的复制是以分区为粒度的,分区的预写日志被复制到 n 个服务器。 在 n 个副本中,一个副本作为 leader,其他副本成为 followers。顾名思义,producer 只能往 leader 分区上写数据(读也只能从 leader 分区上进行),followers 只按顺序从 leader 上复制日志。
日志复制算法(log replication algorithm)必须提供的基本保证是,如果它告诉客户端消息已被提交,而当前 leader 出现故障,新选出的 leader 也必须具有该消息。在出现故障时,Kafka 会从挂掉 leader 的 ISR 里面选择一个 follower 作为这个分区新的 leader ;换句话说,是因为这个 follower 是跟上 leader 写进度的。
每个分区的 leader 会维护一个 in-sync replica(同步副本列表,又称 ISR)。当 producer 往 broker 发送消息,消息先写入到对应 leader 分区上,然后复制到这个分区的所有副本中。只有将消息成功复制到所有同步副本(ISR)后,这条消息才算被提交。由于消息复制延迟受到最慢同步副本的限制,因此快速检测慢副本并将其从 ISR 中删除非常重要。 Kafka 复制协议的细节会有些细微差别,本博客并不打算对该主题进行详尽的讨论。感兴趣的同学可以到这里详细了解 Kafka 复制的工作原理。
副本在什么情况下才算跟上 leader
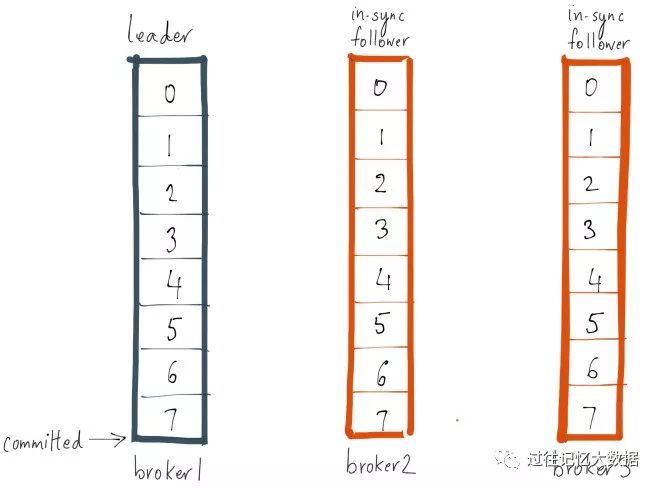
一个副本如果它没有跟上 leader 的日志进度,那么它可能会被标记为不同步的副本。我通过一个例子来解释跟上(caught up)的含义。假设我们有一个名为 foo 的主题,并且只有一个分区,同时复制因子为 3。假设此分区的副本分别在 brokers 1,2和3上,并且我们已经在主题 foo 上提交了3条消息。brokers 1上的副本是 leader,副本2和3是 followers,所有副本都是 ISR 的一部分。假设 replica.lag.max.messages 设置为4,这意味着只要 follower 落后 leader 的消息不超过3条,它就不会从 ISR 中删除。我们把 replica.lag.time.max.ms 设置为500毫秒,这意味着只要 follower 每隔500毫秒或更早地向 leader 发送一个 fetch 请求,它们就不会被标记为死亡并且不会从 ISR 中删除。

现在假设 producer 往 leader 上发送下一条消息,与此同时,broker 3 上发生了 GC 停顿,现在每个 broker 上的分区情况如下所示:

由于 broker 3 在 ISR中,因此在将 broker 3从 ISR 中移除或 broker 3 上的分区跟上 leader 的日志结束偏移之前,最新消息都是不认为被提交的。注意,由于 border 3 落后 leader 的消息比 replica.lag.max.messages = 4 要小,因此不符合从 ISR 中删除的条件。这意味着 broker 3 上的分区需要从 leader 上同步 offset 为 3 的消息,如果它做到了,那么这个副本就是跟上 leader 的。假设 broker 3 在 100ms 内 GC 完成了,并且跟上了 leader 的日志结束偏移,那么最新的情况如下图:

什么情况下会导致一个副本与 leader 失去同步
一个副本与 leader 失去同步的原因有很多,主要包括:
慢副本(Slow replica):follower replica 在一段时间内一直无法赶上 leader 的写进度。造成这种情况的最常见原因之一是 follower replica 上的 I/O瓶颈,导致它持久化日志的时间比它从 leader 消费消息的时间要长;
卡住副本(Stuck replica):follower replica 在很长一段时间内停止从 leader 获取消息。这可能是以为 GC 停顿,或者副本出现故障;
刚启动副本(Bootstrapping replica):当用户给某个主题增加副本因子时,新的 follower replicas 是不同步的,直到它跟上 leader 的日志。
当副本落后于 leader 分区时,这个副本被认为是不同步或滞后的。在 Kafka 0.8.2 中,副本的滞后于 leader 是根据 replica.lag.max.messages 或 replica.lag.time.max.ms 来衡量的; 前者用于检测慢副本(Slow replica),而后者用于检测卡住副本(Stuck replica)。
如何确认某个副本处于滞后状态
通过 replica.lag.time.max.ms 来检测卡住副本(Stuck replica)在所有情况下都能很好地工作。它跟踪 follower 副本没有向 leader 发送获取请求的时间,通过这个可以推断 follower 是否正常。另一方面,使用消息数量检测不同步慢副本(Slow replica)的模型只有在为单个主题或具有同类流量模式的多个主题设置这些参数时才能很好地工作,但我们发现它不能扩展到生产集群中所有主题。在我之前的示例的基础上,如果主题 foo 以 2 msg/sec 的速率写入数
据,其中 leader 收到的单个批次通常永远不会超过3条消息,那么我们知道这个主题的 replica.lag.max.messages 参数可以设置为 4。为什么? 因为我们以最大速度往 leader 写数据并且在 follower 副本复制这些消息之前,follower 的日志落后于 leader 不超过3条消息。同时,如果主题 foo 的 follower 副本始终落后于 leader 超过3条消息,则我们希望 leader 删除慢速 follower 副本以防止消息写入延迟增加。
这本质上是 replica.lag.max.messages 的目标 - 能够检测始终与 leader 不同步的副本。假设现在这个主题的流量由于峰值而增加,生产者最终往 foo 发送了一批包含4条消息,等于 replica.lag.max.messages = 4 的配置值。此时,两个 follower 副本将被视为与 leader 不同步,并被移除 ISR。

但是,由于两个 follower 副本都处于活动状态,因此它们将在下一个 fetch 请求中赶上 leader 的日志结束偏移量并被添加回 ISR。如果生产者继续向 leader 发送大量的消息,则将重复上述相同的过程。这证明了 follower 副本进出 ISR 时触发不必要的错误警报的情况。
replica.lag.max.messages 参数的核心问题是,用户必须猜测如何配置这个值,因为我们不知道 Kafka 的传入流量到底会到多少,特别是在网络峰值的情况下。
一个参数搞定一切
我们意识到,检测卡住或慢速副本真正重要的事情,是副本与 leader 不同步的时间。我们删除了通过猜测来设置的 replica.lag.max.messages 参数。现在,我们只需要在服务器上配置 replica.lag.time.max.ms 参数即可;这个参数的含义为副本与 leader 不同步的时间。
检测卡住副本(Stuck replica)的方式与以前相同 - 如果副本未能在 replica.lag.time.max.ms 时间内发送 fetch 请求,则会将其视为已死的副本并从 ISR 中删除;
检测慢副本的机制已经改变 - 如果副本落后于 leader 的时间超过 replica.lag.time.max.ms,则认为它太慢并且从 ISR 中删除。
因此,即使在峰值流量下,生产者往 leader 发送大量的消息,除非副本始终和 leader 保持 replica.lag.time.max.ms 时间的落后,否则它不会随机进出 ISR。
图文了解 Kafka 的副本复制机制的更多相关文章
- Kafka副本同步机制
引用自:http://blog.csdn.net/lizhitao/article/details/51718185 Kafka副本 Kafka中主题的每个Partition有一个预写式日志文件,每个 ...
- kafka 数据一致性-leader,follower机制与zookeeper的区别;
我写了另一篇zookeeper选举机制的,可以参考:zookeeper 负载均衡 核心机制 包含ZAB协议(滴滴,阿里面试) 一.zookeeper 与kafka保持数据一致性的不同点: (1)zoo ...
- kafka消息的处理机制(五)
这一篇我们不在是探讨kafka的使用,前面几篇基本讲解了工作中的使用方式,基本api的使用还需要更深入的去钻研,多使用才会有提高.今天主要是探讨一下kafka的消息复制以及消息处理机制. 1. bro ...
- Kafka学习笔记(3)----Kafka的数据复制(Replica)与Failover
1. CAP理论 1.1 Cosistency(一致性) 通过某个节点的写操作结果对后面通过其他节点的读操作可见. 如果更新数据后,并发访问的情况下可立即感知该更新,称为强一致性 如果允许之后部分或全 ...
- 【转】跟我学Kafka之NIO通信机制
from:云栖社区 玛德,今天又被人打脸了,小看人,艹,确实,相对比起来,在某些方面差一点,,,,该好好捋捋了,强化下短板,规划下日程,,,引以为耻,铭记于心. 跟我学Kafka之NIO通信机制 ...
- Kafka文件的存储机制
Kafka文件的存储机制 同一个topic下有多个不同的partition,每个partition为一个目录,partition命名的规则是topic的名称加上一个序号,序号从0开始. 每一个part ...
- MySQL的复制机制
MySQL的复制机制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL复制介绍 1>.MySQL复制允许将主实例(master)上的数据同步到一个或多个从实例( ...
- PostgreSQL主备流复制机制
原文出处 http://mysql.taobao.org/monthly/2015/10/04/ PostgreSQL在9.0之后引入了主备流复制机制,通过流复制,备库不断的从主库同步相应的数据,并在 ...
- [redis]复制机制,调优,故障排查
在redis的安装目录下首先启动一个redis服务,使用默认的配置文件,作为主服务 ubuntu@slave1:~/redis2$ ./redis-server ./redis.conf & ...
随机推荐
- 【已解决】WebUploader 0.1.5 安卓手机不能访问相机、IOS直接访问相机 的问题
WebUploader 0.1.5 安卓手机不能访问相机.IOS直接访问相机 的问题 打开 webuploader.js if(navigator.userAgent.indexOf('Android ...
- 捕获网络数据包并进行分析的开源库-WinPcap
什么是WinPcap WinPcap是一个基于Win32平台的,用于捕获网络数据包并进行分析的开源库. 大多数网络应用程序通过被广泛使用的操作系统元件来访问网络,比如sockets. 这是一种简单的 ...
- MySQL四:表操作
阅读目录 表介绍 一 创建表 二 查看表结构 三 数据类型 四 表完整性约束 五 修改表ALTER TABLE 六 复制表 七 删除表 八 完整性约束 九 数据类型 表介绍 表相当于文件,表中的一条记 ...
- PHP-Socket-阻塞与非阻塞,同步与异步概念的理解
1. 概念理解 在进行网络编程时,我们常常见到同步(Sync)/异步(Async),阻塞(Block)/非阻塞(Unblock)四种调用方式:同步: 所谓同步,就是在发出一个功能调用时,在没 ...
- sql生成器(含凝视)问题修复版
接上篇http://blog.csdn.net/panliuwen/article/details/47406455 sql生成器--生成含凝视的sql语句 今天我使用自己写的sql生成器了.自我感觉 ...
- kubernetes高级之集群中使用sysctls
系列目录 在linux系统里,sysctls 接口允许管理员在运行时修改内核参数.参数存在于/proc/sys/虚拟进程文件系统里.参数涉及到很多子模块,例如: 内核(kernel)(常见前缀kern ...
- Linux 服务器上建立用户并分配权限
查看用户 whoami #要查看当前登录用户的用户名 who am i #表示打开当前伪终端的用户的用户名 who mom likes who 命令其它常用参数 参数 说明 -a 打印能打印的全部 - ...
- ural 1303 Minimal Coverage【贪心】
链接: http://acm.timus.ru/problem.aspx?space=1&num=1303 http://acm.hust.edu.cn/vjudge/contest/view ...
- python脚本分析nginx访问日志
日志格式如下: 223.74.135.248 [11/May/2017:11:19:47 +0800] "POST /login/getValidateCode HTTP/1.1" ...
- iOS 微信支付点击左上角返回解决方案
在网了搜了一些解决方案,感觉并不是那么严谨,于是自己动手搞了一下,直接说思路 iOS调起第三方支付和安卓还不一样,安卓是把第三方的支付SDK直接镶嵌在自己的App中,而iOS由于沙盒机制,各个应用之间 ...