Spark RDD概念学习系列之RDD的操作(七)
RDD的操作
RDD支持两种操作:转换和动作。
1)转换,即从现有的数据集创建一个新的数据集。
2)动作,即在数据集上进行计算后,返回一个值给Driver程序。
例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布式数据集表示结果。另一个方面,reduce是一种动作,通过一些函数将所有元素叠加起来,并将最终结果返回Driver(还有一个并行的reduceByKey,能返回一个分布式数据集)。
下图描述了从外部数据源创建RDD,经过多次转换,通过一个动作操作将结果写回外部存储系统的逻辑运行图。整个过程的计算都是在Worker中的Executor中运行。

图 1 RDD的创建、转换和动作的逻辑计算图
RDD的转换
RDD中的所有转换都是惰性的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这个设计让Spark更加有效率地运行。例如我们可以实现:通过map创建的一个新数据集,并在reduce中使用,最终只返回reduce的结果给Driver,而不是整个大的新数据集。图2描述了RDD在进行groupByRey时的内部RDD转换的实现逻辑图。图3描述了reduceByKey的实现逻辑图。

图2 RDD groupByKey的逻辑转换图
在groupByKey的操作中,会在MapPartitionsRDD做一次Shuffle,图2中设置的分片数量是3,因此ShuffledRDD会有3个分片,ShuffledRDD实际上仅仅是从上游的任务中读取Shuffle的结果,因此图的箭头是指向上游的MapPartitionsRDD的。关于Shuffle的实现实际上要比图中展示得复杂得多。reduceByKey和groupByKey的实现差不多,它在Shuffle完成之后,需要做一次reduce。
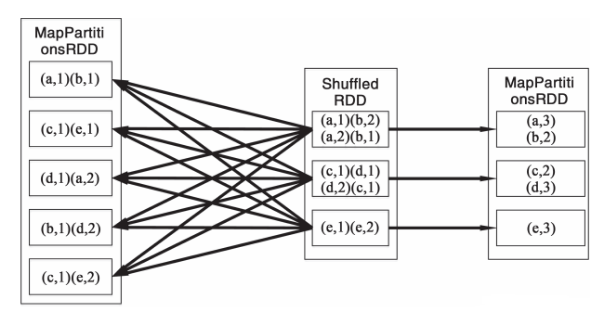
图3 RDD reduceByKey 的逻辑转换图
默认情况下,每一个转换过的RDD都会在它执行一个动作时被重新计算。不过也可以使用persist(或者cache)方法,在内存中持久化一个RDD。在这种情况下,Spark将会在集群中保存相关元素,下次查询这个RDD时能更快访问它。也支持在磁盘上持久化数据集,或在集群间复制数据集。
Spark RDD概念学习系列之RDD的操作(七)的更多相关文章
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之RDD与DSM的异同分析(十三)
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比. 在DSM系统[1]中,应用可以向全局地址空间的任意位置进行读写操作 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
随机推荐
- STL笔记(3) copy()之绝版应用
STL笔记(3) copy()之绝版应用 我选用了一个稍稍复杂一点的例子,它的大致功能是:从标准输入设备(一般是键盘)读入一些整型数据,然后对它们进行排序,最终将结果输出到标准输出设备(一般是显示器屏 ...
- Headfirst JSP 01 (概述)
HTTP 协议 http 是tcp/ip上层协议, 如果你对这些网络协议还不是太熟悉, 下面提供一个非常简单的解释, tcp负责确保从一个网络节点向另一个网络节点发送文件能作为一个完整的文件到达目的地 ...
- Android微信SDK API 调用教程1
最近一直在调用微信的API,却发现一直调用不成功,纠结了好久,各方面找教程,找官方,官方里的文档也只是写得很模糊,说是按三步走. 1.申请App_ID 2.填写包名3. 获取程序签名的md5值, 这三 ...
- document.body.innerHTML用jquery如何表示
$("body").html('XXXX'); //这个是赋值 $("body").html(); //这个是获取HTML的内容
- gulp some tips
gulp作为替代grunt的task runner后起之秀,基于nodejs的stream操作模型,大大减少了对磁盘的操作因此大大提高了性能. gulp error handling var gulp ...
- ionic中登陆逻辑控制
问题 登陆成功后从login.html调转到home.html,此时在home页面按back键又回到了login.html . 解决方案 登陆成功后,清除导航历史堆栈. 具体代码 menu.html ...
- POJ (线段树) Who Gets the Most Candies?
这道题综合性挺强的,又牵扯到数论,又有线段树. 线段树维护的信息就是区间中有多少个人没跳出去,然后计算出下一个人是剩下的人中第几个. 我在这调程序调了好久,就是那个模来模去的弄得我头晕. 不过题确实是 ...
- POJ2186 POPULAR COW
链接:http://poj.org/problem?id=2186 题意:给你N个点,然后在给你N条有向边,然后让你找出这样的点S,S满足条件图上任意一点都能到达S. 要想满足任意一点都能到达,首先满 ...
- Singleton模式写法
public class Singleton { /** * 类级的内部类,也就是静态的成员式内部类,该内部类的实例与外部类的实例 * 没有绑定关系,而且只有被调用到才会装载,从而实现了延迟加载 */ ...
- csu 1326 The contest
裸的 并查集 + 分组背包: #include<iostream> #include<cstring> #include<algorithm> #inclu ...