SQL Server-简单查询示例(十一)
前言
本节我们讲讲一些简单查询语句示例以及需要注意的地方,简短的内容,深入的理解,Always to review the basics。
EOMONTH
在SQL Server 2012的教程示例中,对于Sales.Orders表的查询,需要返回每月最后一天的订单。我们普遍的查询如下
USE TSQL2012
GO SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate = DATEADD(MONTH, DATEDIFF(MONTH, '', orderdate), '')

但是在SQL Server 2012出现了新的函数直接返回每个月最后一天的订单,通过EOMONTH函数即可,将
WHERE orderdate = DATEADD(MONTH, DATEDIFF(MONTH, '', orderdate), '')
替换为
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
WHERE orderdate = EOMONTH(orderdate)
如上简单而粗暴。
HAVING AND WHERE
我们利用Sales.OrderDetails表来查询总价(qty*unitprice)大于10000的订单,且按照总价排序。
USE TSQL2012
GO SELECT orderid,SUM(unitprice *qty) AS TotalValue
FROM Sales.OrderDetails
GROUP BY orderid
HAVING SUM(unitprice *qty) >
ORDER BY TotalValue DESC

通过此例我们来说说WHERE和HAVING的区别,下面的示例是等同的
SELECT orderid
FROM Sales.OrderDetails
WHERE orderid >
GROUP BY orderid SELECT orderid
FROM Sales.OrderDetails
GROUP BY orderid
HAVING orderid >
但是利用聚合函数时能等同吗?
SELECT orderid
FROM Sales.OrderDetails
WHERE COUNT(qty * unitprice) >
GROUP BY orderid SELECT orderid
FROM Sales.OrderDetails
GROUP BY orderid
HAVING COUNT(qty * unitprice) >

二者的区别我们总结一下:
(1)WHERE能够用在UPDATE、DELETE、SELECT语句中,而HAVING只能用在SELECT语句中。
(2)WHERE过滤行在GROUP BY之前,而HAVING过滤行在GROUP BY之后。
(3)WHERE不能用在聚合函数中,除非该聚合函数位于HAVING子句或选择列表所包含的子查询中。
说了这么多,关于WHERE和HAVING的区别,其实WHERE的应用场景更多,我们归根结底一句话来概括的HAVING的用法即可。
HAVING仅仅在SELECT语句中对组(GROUP BY)或者聚合函数(AGGREGATE)进行过滤
INSERT TOP分析
当将查询出的数据插入到表中,我们其实有两种解决方案。
方案一
INSERT INTO TABLE …
SELECT TOP (N) Cols…
FROM Table
方案二
INSERT TOP(N) INTO TABLE …
SELECT Cols…
FROM Table
方案一是需要查询几条就插入几条,方案二则是查询所有我们需要插入几条数据,接下来我们来看看二者不同以及二者性能问题,创建查询表并插入数据。
CREATE TABLE TestValue(ID INT)
INSERT INTO TestValue (ID)
SELECT
UNION ALL
SELECT
UNION ALL
SELECT
UNION ALL
SELECT
UNION ALL
SELECT
需要插入的两个表
USE TSQL2012
GO CREATE TABLE InsertTestValue (ID INT) CREATE TABLE InsertTestValue1 (ID INT)
方案一的插入
INSERT INTO InsertTestValue (ID)
SELECT TOP () ID
FROM TestValue
ORDER BY ID DESC
GO
方案二的插入
INSERT TOP () INTO InsertTestValue1 (ID)
SELECT ID
FROM TestValue
ORDER BY ID DESC
GO
接下来查询方案一和方案二的数据
SELECT *
FROM InsertTestValue
GO SELECT *
FROM InsertTestValue1
GO

我们对方案一和方案二插入数据之前我们对查询的数据是进行了降序,此时我们能够很明显的看到方案一中的查询数据确确实实是降序,而方案二则忽略了降序,这是个很有意思的地方,至此我们看到了二者的不同。
二者性能比较
在插入数据时我们对其进行开销分析如下:
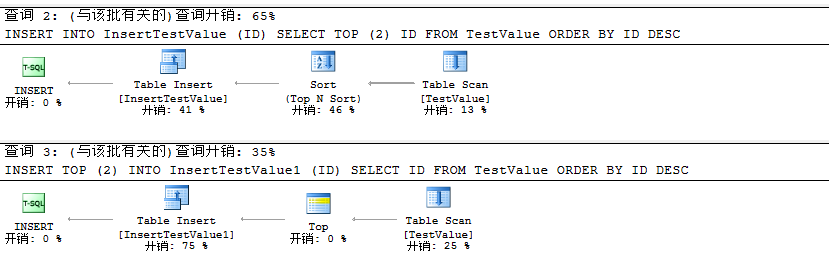
到这里我们能够知道利用INSET TOP (N)比INSERT … SELECT TOP (N)性能更好,同时INSERT TOP(N)会对查询出的数据排序进行忽略。至此我们可以得出如下结论
结论:INSERT TOP (N)比INSERT … SELECT TOP (N)插入数据性能更好。
COUNT(DISTINCT) AND COUNT(ALL)
关于DISTINCT就不用多讲,此关键字过滤重复针对的是所有列数据一致才过滤而不是针对于单列数据一致才过滤,我们看看COUNT(DISTINCT)和COUNT(ALL)查询出的数据是一致还是不一致呢?我们首先创建测试表
CREATE TABLE TestData
(
Id INT NOT NULL IDENTITY PRIMARY KEY,
NAME VARCHAR(max) NULL
);
插入如下测试数据

接下来我们进行如下查询
USE TSQL2012
GO SELECT COUNT(NAME) AS COUNT_NAME
FROM dbo.TestData SELECT COUNT(ALL NAME) AS COUNT_ALLNAME
FROM dbo.TestData SELECT COUNT(DISTINCT NAME) AS COUNT_DISTINCTNAME
FROM dbo.TestData

此时我们能够很清楚的看到COUNT(colName)和COUNT(ALL colName)的结果是一样的,其实COUNT(ALL colName)是默认的选项且包括所有非空值,换句话说ALL根本不需要我们去显示指定。
总结
本节我们简单讲了简单查询语句以及需要注意的地方,关于简单查询和基础概念我们到此结束,下一节我们开始进入表连接,接下来的内容将越来越有意思,简短的内容,深入的理解,我们下节再会。
SQL Server-简单查询示例(十一)的更多相关文章
- Sql Server 简单查询 异步服务器更新语句
//结构:select 子句 [into 子句] from 子句 [where 子句] [group by 子句] [having 子句] [order by 子句] select dept_c ...
- 【转】Sql Server参数化查询之where in和like实现之xml和DataTable传参
转载至: http://www.cnblogs.com/lzrabbit/archive/2012/04/29/2475427.html 在上一篇Sql Server参数化查询之where in和li ...
- Sql Server参数化查询之where in和like实现之xml和DataTable传参 (转)
在上一篇Sql Server参数化查询之where in和like实现详解中介绍了在Sql Server使用参数化查询where in的几种实现方案,遗漏了xml和表值参数,这里做一个补充 文章导读 ...
- C#构造方法(函数) C#方法重载 C#字段和属性 MUI实现上拉加载和下拉刷新 SVN常用功能介绍(二) SVN常用功能介绍(一) ASP.NET常用内置对象之——Server sql server——子查询 C#接口 字符串的本质 AJAX原生JavaScript写法
C#构造方法(函数) 一.概括 1.通常创建一个对象的方法如图: 通过 Student tom = new Student(); 创建tom对象,这种创建实例的形式被称为构造方法. 简述:用来初 ...
- Sql Server参数化查询之where in和like实现详解
where in 的参数化查询实现 首先说一下我们常用的办法,直接拼SQL实现,一般情况下都能满足需要 string userIds = "1,2,3,4"; using (Sql ...
- 【转】Sql Server参数化查询之where in和like实现详解
转载至:http://www.cnblogs.com/lzrabbit/archive/2012/04/22/2465313.html 文章导读 拼SQL实现where in查询 使用CHARINDE ...
- 优化SQL Server数据库查询方法
SQL Server数据库查询速度慢的原因有很多,常见的有以下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列 ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
- SQL Server 2016 查询存储性能优化小结
SQL Server 2016已经发布了有半年多,相信还有很多小伙伴还没有开始使用,今天我们来谈谈SQL Server 2016 查询存储性能优化,希望大家能够喜欢 作为一个DBA,排除SQL Ser ...
- 【转载】Sql Server参数化查询之where in和like实现详解
文章导读 拼SQL实现where in查询 使用CHARINDEX或like实现where in 参数化 使用exec动态执行SQl实现where in 参数化 为每一个参数生成一个参数实现where ...
随机推荐
- RecyclerView使用大全
RecylerView介绍 RecylerView是support-v7包中的新组件,是一个强大的滑动组件,与经典的ListView相比,同样拥有item回收复用的功能,这一点从它的名字recyler ...
- 从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点)
从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- C# i=0;i=i++,i的值是多少?
昨天看群里dalao们聊天,有一个人出来问这个问题 这个题应该是挺常见的 int i = 0, t; for(t = 0;t <= 5;t++) { ...
- [Java 缓存] Java Cache之 DCache的简单应用.
前言 上次总结了下本地缓存Guava Cache的简单应用, 这次来继续说下项目中使用的DCache的简单使用. 这里分为几部分进行总结, 1)DCache介绍; 2)DCache配置及使用; 3)使 ...
- 《Django By Example》第一章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:本人目前在杭州某家互联网公司工作, ...
- Oracle碎碎念~1
1. 设置SQL*Plus提示符 SQL> set sqlprompt "_user'@'_connect_identifier>" SYS@orcl> 为了对所 ...
- ASP.NET Core 1.0 开发记录
官方资料: https://github.com/dotnet/core https://docs.microsoft.com/en-us/aspnet/core https://docs.micro ...
- c#比较两个数组的差异
将DataTable中某一列数据直接转换成数组进行比较,使用的Linq,要引用命名空间using System.Linq; string[] arrRate = dtRate.AsEnumerable ...
- 如何用Java类配置Spring MVC(不通过web.xml和XML方式)
DispatcherServlet是Spring MVC的核心,按照传统方式, 需要把它配置到web.xml中. 我个人比较不喜欢XML配置方式, XML看起来太累, 冗长繁琐. 还好借助于Servl ...
- BPM费控管理解决方案分享
一.方案概述费用是除经营成本外企业的最主要支出,费用管理是财务管理的核心之一,加强企业内控管理如:费用申请.费用报销.费用分摊.费用审批.费用控制和费用支付等,通过科学有效的管理方法规范企业费用管理, ...