Android数据库一些源码分析
对于批量数据插入这种最常见的情况来说,我们来看两种实现方式(两种都用了事务)。
下面这种应该是最多人使用的插入数据的方法:
public long addByExec(List<Person> persons) {
long start = System.currentTimeMillis();
db.beginTransaction();
for (Person person : persons) {
db.execSQL(" INSERT INTO person(name,age,info) VALUES(?, ?, ?) ",
new Object[] { person.name, person.age, person.info });
}
db.setTransactionSuccessful();
long end = System.currentTimeMillis();
db.endTransaction();
return end - start;
}
再看一种比较少用的插入方法
public long addByStatement(List<Person> persons) {
long start = System.currentTimeMillis();
db.beginTransaction();
SQLiteStatement sqLiteStatement = db.compileStatement(sql);
for (Person person : persons) {
sqLiteStatement.bindString(1, person.name);
sqLiteStatement.bindString(2, person.age);
sqLiteStatement.bindString(3, person.info);
sqLiteStatement.executeInsert();
}
db.setTransactionSuccessful();
long end = System.currentTimeMillis();
db.endTransaction();
return end - start;
}
然后我们分别用这两个方法 来向数据库里面插入一万条数据 看看耗时多少。为了演示效果更加突出一点,我录制了一个GIF,同时,
这2个方法我也没有用子线程来操作他,直接在ui线程上操作 所以看起来效果会比较突出一些(但是自己写代码的时候千万别这么写小心ANR)。
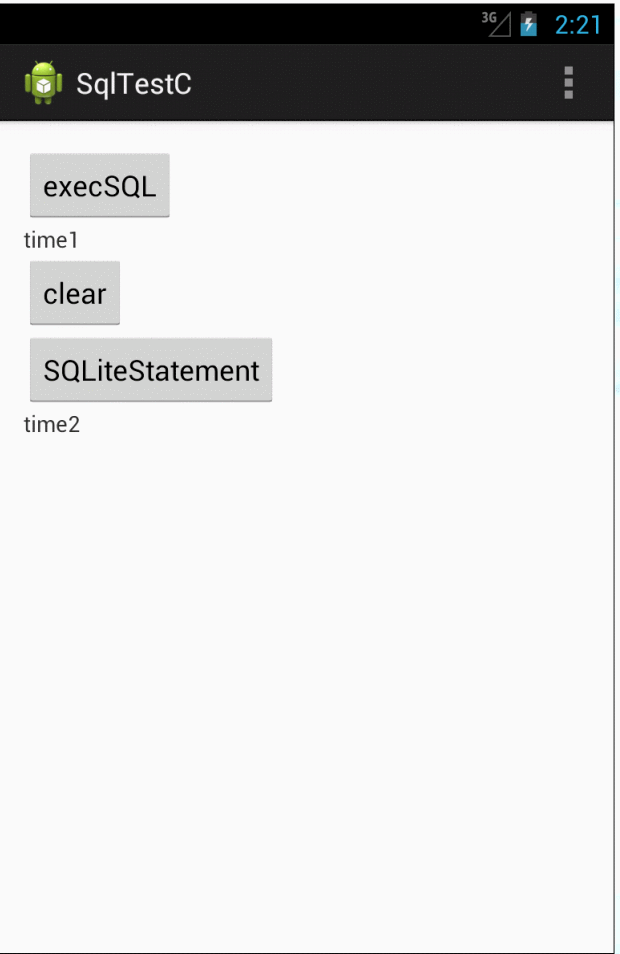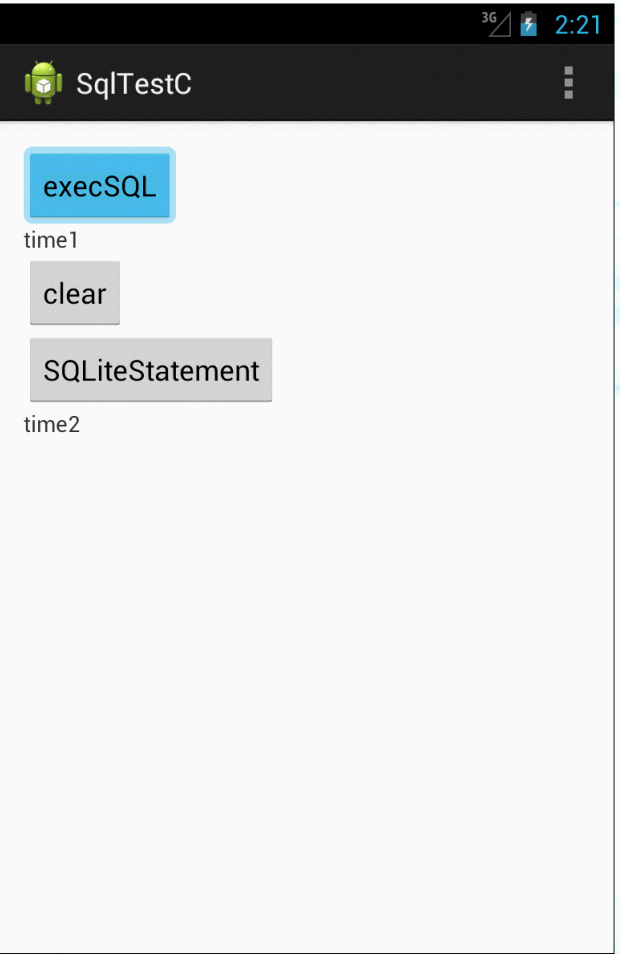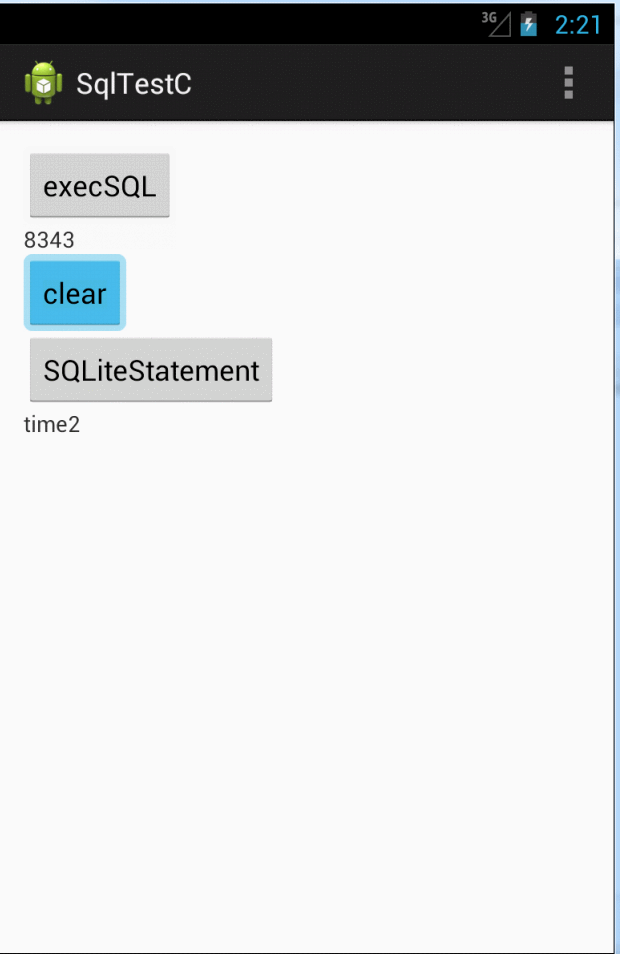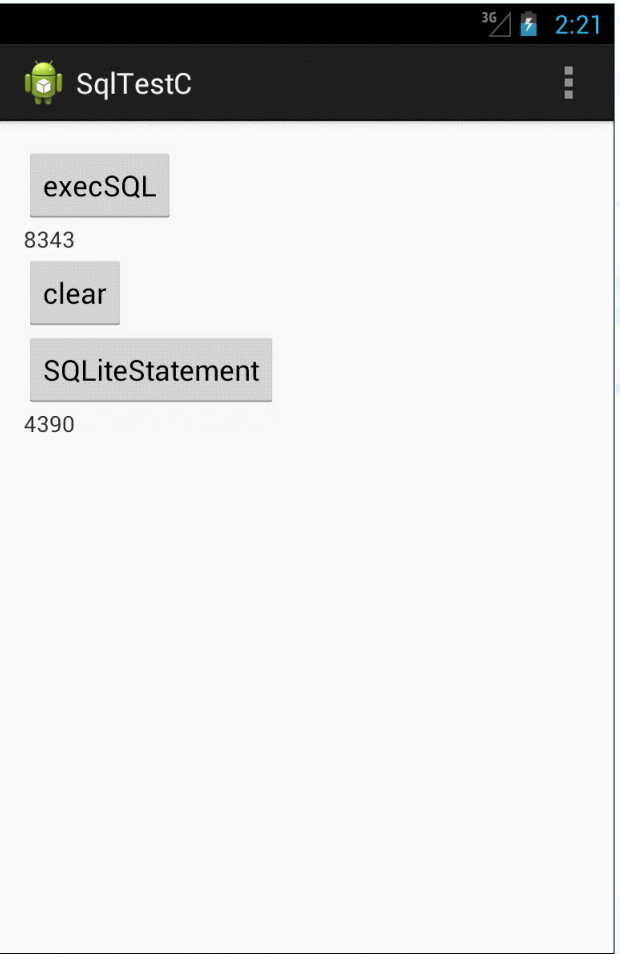
可以看出来后者耗时几乎只有前者的 一半(所以以后大家在做大批量数据插入的时候可以考虑后者的实现方式)。我们来看看源代码为啥会这样。
首先看前者的实现方法源码
public void execSQL(String sql, Object[] bindArgs) throws SQLException {
if (bindArgs == null) {
throw new IllegalArgumentException("Empty bindArgs");
}
executeSql(sql, bindArgs);
}
private int executeSql(String sql, Object[] bindArgs) throws SQLException {
if (DatabaseUtils.getSqlStatementType(sql) == DatabaseUtils.STATEMENT_ATTACH) {
disableWriteAheadLogging();
mHasAttachedDbs = true;
}
SQLiteStatement statement = new SQLiteStatement(this, sql, bindArgs);
try {
return statement.executeUpdateDelete();
} catch (SQLiteDatabaseCorruptException e) {
onCorruption();
throw e;
} finally {
statement.close();
}
}
我们发现 前者的实现 实际上最后也是通过SQLiteStatement 这个类是操作的。
而后者不过是
public SQLiteStatement compileStatement(String sql) throws SQLException {
verifyDbIsOpen();
return new SQLiteStatement(this, sql, null);
}
所以实际上前者之所以比后者耗时 应该是下面这段代码的原因:
if (DatabaseUtils.getSqlStatementType(sql) == DatabaseUtils.STATEMENT_ATTACH) {
disableWriteAheadLogging();
mHasAttachedDbs = true;
}
public static int getSqlStatementType(String sql) {
sql = sql.trim();
if (sql.length() < 3) {
return STATEMENT_OTHER;
}
String prefixSql = sql.substring(0, 3).toUpperCase();
if (prefixSql.equals("SEL")) {
return STATEMENT_SELECT;
} else if (prefixSql.equals("INS") ||
prefixSql.equals("UPD") ||
prefixSql.equals("REP") ||
prefixSql.equals("DEL")) {
return STATEMENT_UPDATE;
} else if (prefixSql.equals("ATT")) {
return STATEMENT_ATTACH;
} else if (prefixSql.equals("COM")) {
return STATEMENT_COMMIT;
} else if (prefixSql.equals("END")) {
return STATEMENT_COMMIT;
} else if (prefixSql.equals("ROL")) {
return STATEMENT_ABORT;
} else if (prefixSql.equals("BEG")) {
return STATEMENT_BEGIN;
} else if (prefixSql.equals("PRA")) {
return STATEMENT_PRAGMA;
} else if (prefixSql.equals("CRE") || prefixSql.equals("DRO") ||
prefixSql.equals("ALT")) {
return STATEMENT_DDL;
} else if (prefixSql.equals("ANA") || prefixSql.equals("DET")) {
return STATEMENT_UNPREPARED;
}
return STATEMENT_OTHER;
}
实际上就是多了一个字符串处理的函数。这就是为什么前者耗时要比后者多。因为实际上直接调用executeSql的时候
他里面是先做字符串处理然后再调用SQLiteStatement来执行,这个过程当然是比我们直接调用SQLiteStatement
来执行速度慢的。
我们首先来看一下下面这个函数
public Cursor queryTest1() {
long start1 = System.currentTimeMillis();
Cursor c = db.rawQuery("select * from t1,t3 where t1.num>t3.num", null);
long end1 = System.currentTimeMillis();
Log.v("DBManager", "time1 need " + (end1 - start1));
long start2 = System.currentTimeMillis();
c.moveToNext();
long end2 = System.currentTimeMillis();
Log.v("DBManager", "time2 need" + (end2 - start2));
long start3 = System.currentTimeMillis();
c.moveToNext();
long end3 = System.currentTimeMillis();
Log.v("DBManager", "time3 need" + (end3 - start3));
return c;
}
一个很常见的,多表查询的函数,有些人可能会奇怪为啥在这个地方我要加那么多日志。实际上如果你t1和t3的数据都很多的话,这个查询是可以预料到的会非常耗时。
很多人都会以为这个耗时是在下面这条语句做的:
Cursor c = db.rawQuery("select * from t1,t3 where t1.num>t3.num", null);
但是实际上这个查询耗时是在你第一调用
c.moveToNext();
来做的,有兴趣的同学可以自己试一下,我们这里就不帮大家来演示这个效果了,但是可以帮助大家分析一下源代码为什么会是这样奇怪的结果?
我们首先来分析一下rawQuery 这个函数
public Cursor rawQuery(String sql, String[] selectionArgs) {
return rawQueryWithFactory(null, sql, selectionArgs, null);
}
/**
* Runs the provided SQL and returns a cursor over the result set.
*
* @param cursorFactory the cursor factory to use, or null for the default factory
* @param sql the SQL query. The SQL string must not be ; terminated
* @param selectionArgs You may include ?s in where clause in the query,
* which will be replaced by the values from selectionArgs. The
* values will be bound as Strings.
* @param editTable the name of the first table, which is editable
* @return A {@link Cursor} object, which is positioned before the first entry. Note that
* {@link Cursor}s are not synchronized, see the documentation for more details.
*/
public Cursor rawQueryWithFactory(
CursorFactory cursorFactory, String sql, String[] selectionArgs,
String editTable) {
verifyDbIsOpen();
BlockGuard.getThreadPolicy().onReadFromDisk();
SQLiteDatabase db = getDbConnection(sql);
SQLiteCursorDriver driver = new SQLiteDirectCursorDriver(db, sql, editTable);
Cursor cursor = null;
try {
cursor = driver.query(
cursorFactory != null ? cursorFactory : mFactory,
selectionArgs);
} finally {
releaseDbConnection(db);
}
return cursor;
}
看一下24行,发现是构造了一个driver对象 然后调用这个driver对象的query方法
我们继续跟踪源代码
public SQLiteDirectCursorDriver(SQLiteDatabase db, String sql, String editTable,
CancellationSignal cancellationSignal) {
mDatabase = db;
mEditTable = editTable;
mSql = sql;
mCancellationSignal = cancellationSignal;
} public Cursor query(CursorFactory factory, String[] selectionArgs) {
final SQLiteQuery query = new SQLiteQuery(mDatabase, mSql, mCancellationSignal);
final Cursor cursor;
try {
query.bindAllArgsAsStrings(selectionArgs); if (factory == null) {
cursor = new SQLiteCursor(this, mEditTable, query);
} else {
cursor = factory.newCursor(mDatabase, this, mEditTable, query);
}
} catch (RuntimeException ex) {
query.close();
throw ex;
} mQuery = query;
return cursor;
}
发现这个返回的cursor实际上就是直接new出来的一个对象
public SQLiteCursor(SQLiteCursorDriver driver, String editTable, SQLiteQuery query) {
if (query == null) {
throw new IllegalArgumentException("query object cannot be null");
}
if (query.mDatabase == null) {
throw new IllegalArgumentException("query.mDatabase cannot be null");
}
mStackTrace = new DatabaseObjectNotClosedException().fillInStackTrace();
mDriver = driver;
mEditTable = editTable;
mColumnNameMap = null;
mQuery = query;
query.mDatabase.lock(query.mSql);
try {
// Setup the list of columns
int columnCount = mQuery.columnCountLocked();
mColumns = new String[columnCount];
// Read in all column names
for (int i = 0; i < columnCount; i++) {
String columnName = mQuery.columnNameLocked(i);
mColumns[i] = columnName;
if (false) {
Log.v("DatabaseWindow", "mColumns[" + i + "] is "
+ mColumns[i]);
}
// Make note of the row ID column index for quick access to it
if ("_id".equals(columnName)) {
mRowIdColumnIndex = i;
}
}
} finally {
query.mDatabase.unlock();
}
}
所以看到这里我们就能确定的是rawquery这个方法 返回的cursor实际上就是一个对象,并没有任何真正调用sql的地方。
然后我们来看看我们怀疑的moveToNext这个方法因为从日志上看耗时的地方在第一次调用他的时候,所以我们怀疑真正调用查询sql的地方
在这个函数里面被触发。
public final boolean moveToNext() {
return moveToPosition(mPos + 1);
}
public final boolean moveToPosition(int position) {
// Make sure position isn't past the end of the cursor
final int count = getCount();
if (position >= count) {
mPos = count;
return false;
}
// Make sure position isn't before the beginning of the cursor
if (position < 0) {
mPos = -1;
return false;
}
// Check for no-op moves, and skip the rest of the work for them
if (position == mPos) {
return true;
}
boolean result = onMove(mPos, position);
if (result == false) {
mPos = -1;
} else {
mPos = position;
if (mRowIdColumnIndex != -1) {
mCurrentRowID = Long.valueOf(getLong(mRowIdColumnIndex));
}
}
return result;
}
看一下那个getcount方法
@Override
public int getCount() {
if (mCount == NO_COUNT) {
fillWindow(0);
}
return mCount;
} private void fillWindow(int startPos) {
clearOrCreateLocalWindow(getDatabase().getPath());
mWindow.setStartPosition(startPos);
int count = getQuery().fillWindow(mWindow);
if (startPos == 0) { // fillWindow returns count(*) only for startPos = 0
if (Log.isLoggable(TAG, Log.DEBUG)) {
Log.d(TAG, "received count(*) from native_fill_window: " + count);
}
mCount = count;
} else if (mCount <= 0) {
throw new IllegalStateException("Row count should never be zero or negative "
+ "when the start position is non-zero");
}
}
发现如果满足某个条件的话 就调用fillwindow这个方法,我们来看看是什么条件
/** The number of rows in the cursor */
private volatile int mCount = NO_COUNT;
static final int NO_COUNT = -1;
看到这就明白了,如果你默认的mCount为-1的话就代表你这个cursor里面还没有查过吗,所以必须要调用fillwindow方法
private synchronized SQLiteQuery getQuery() {
return mQuery;
}
我们来看看这个query是什么
/** The query object for the cursor */
private SQLiteQuery mQuery;
看看他的fillwindow方法
/**
* Reads rows into a buffer. This method acquires the database lock.
*
* @param window The window to fill into
* @return number of total rows in the query
*/
/* package */ int fillWindow(CursorWindow window) {
mDatabase.lock(mSql);
long timeStart = SystemClock.uptimeMillis();
try {
acquireReference();
try {
window.acquireReference();
int startPos = window.getStartPosition();
int numRows = nativeFillWindow(nHandle, nStatement, window.mWindowPtr,
startPos, mOffsetIndex);
if (SQLiteDebug.DEBUG_LOG_SLOW_QUERIES) {
long elapsed = SystemClock.uptimeMillis() - timeStart;
if (SQLiteDebug.shouldLogSlowQuery(elapsed)) {
Log.d(TAG, "fillWindow took " + elapsed
+ " ms: window=\"" + window
+ "\", startPos=" + startPos
+ ", offset=" + mOffsetIndex
+ ", filledRows=" + window.getNumRows()
+ ", countedRows=" + numRows
+ ", query=\"" + mSql + "\""
+ ", args=[" + (mBindArgs != null ?
TextUtils.join(", ", mBindArgs.values()) : "")
+ "]");
}
}
mDatabase.logTimeStat(mSql, timeStart);
return numRows;
} catch (IllegalStateException e){
// simply ignore it
return 0;
} catch (SQLiteDatabaseCorruptException e) {
mDatabase.onCorruption();
throw e;
} catch (SQLiteException e) {
Log.e(TAG, "exception: " + e.getMessage() + "; query: " + mSql);
throw e;
} finally {
window.releaseReference();
}
} finally {
releaseReference();
mDatabase.unlock();
}
}
一目了然,其实就是rawquery返回的是一个没有意义的cursor对象里面什么都没有,当你调用movetonext之类的方法的时候,
会判断是否里面没有数据 如果有数据就返回你要的数据,如果没有的话,实际上最终调用的就是SQLiteQuery这个类的fillwindow方法
来最终执行你写的sql语句~~耗时也就是在这里耗时!!!!!切记!不是在rawquery里耗时的!
Android数据库一些源码分析的更多相关文章
- Android网络框架源码分析一---Volley
转载自 http://www.jianshu.com/p/9e17727f31a1?utm_campaign=maleskine&utm_content=note&utm_medium ...
- OpenGL—Android 开机动画源码分析一
.1 Android开机动画实现方式目前实现Android开机动画的方式主要是逐帧动画和OpenGL动画. ?逐帧动画 逐帧动画是一种常见的动画形式(Frame By Frame),其原理是在“连续的 ...
- Android分包MultiDex源码分析
转载请标明出处:http://blog.csdn.net/shensky711/article/details/52845661 本文出自: [HansChen的博客] 概述 Android开发者应该 ...
- Android 数据库 ObjectBox 源码解析
一.ObjectBox 是什么? greenrobot 团队(现有 EventBus.greenDAO 等开源产品)推出的又一数据库开源产品,主打移动设备.支持跨平台,最大的优点是速度快.操作简洁,目 ...
- Android消息机制源码分析
本篇主要介绍Android中的消息机制,即Looper.Handler是如何协同工作的: Looper:主要用来管理当前线程的消息队列,每个线程只能有一个Looper Handler:用来将消息(Me ...
- Android 开机动画源码分析
Android系统在启动SystemServer进程时,通过两个阶段来启动系统所有服务,在第一阶段启动本地服务,如SurfaceFlinger,SensorService等,在第二阶段则启动一系列的J ...
- Android开源框架源码分析:Okhttp
一 请求与响应流程 1.1 请求的封装 1.2 请求的发送 1.3 请求的调度 二 拦截器 2.1 RetryAndFollowUpInterceptor 2.2 BridgeInterceptor ...
- android hardware.c 源码分析
android的jni通过ID来找hal模块,使用了hw_get_module()函数,本文就通过这个函数的来分析一下hal层的模块是如何匹配的. 首先要了解三个结构体hw_module_t,hw_m ...
- Android -- 消息处理机制源码分析(Looper,Handler,Message)
android的消息处理有三个核心类:Looper,Handler和Message.其实还有一个Message Queue(消息队列),但是MQ被封装到Looper里面了,我们不会直接与MQ打交道,因 ...
随机推荐
- JavaScript基础(一)
我是一个初学者,但求能学到些许知识!以下是根据韩顺平老师的<轻松搞定网页设计html+css+javascript—javascrip部分>整理而成. 为什么要学习javascript? ...
- 欧拉工程第55题:Lychrel numbers
package projecteuler51to60; import java.math.BigInteger; import java.util.Iterator; import java.util ...
- C语言关键字
No. 关键字 意义 备注 1 auto 声明自动变量 2 break 跳出当前循环 3 case switch语句的分支 4 char 声明字符型变量 5 const 声明只读变量 C90新增 6 ...
- RTMP/RTP/RTSP/RTCP的区别
RTCP RTMP/RTP/RTSP/RTCP的区别 http://blog.csdn.net/frankiewang008/article/details/7665547 流媒体协议介绍(rtp/r ...
- Ibm-jQuery教程学习笔记
一.概述 1.虽然 jQuery 本身并非一门新的语言.但是,学习其语法有助于我们熟练.灵活地使用它.回顾下我们熟悉的 CSS 语法,不难发现 jQuery 的语法与 CSS 有相似之处. jQuer ...
- 局部敏感哈希Locality Sensitive Hashing(LSH)之随机投影法
1. 概述 LSH是由文献[1]提出的一种用于高效求解最近邻搜索问题的Hash算法.LSH算法的基本思想是利用一个hash函数把集合中的元素映射成hash值,使得相似度越高的元素hash值相等的概率也 ...
- javascript 中文数字阿拉伯数字转换类 Nzh
之前工作中碰到了数字转中文的情景,网上找的现成方法或多或少不合我的口味,最后还是自已写了一个. 现在整理了一下,补充了繁体,自定义字符,以及反函数(中文数字转阿拉伯数字) 现在发布出来,希望能合大家的 ...
- 英语学习APP—百词斩
英语学习APP-百词斩 1.简介: 百词斩是由成都超有爱科技有限公司针对英语学习开发的一款"图背单词软件".软件为每一个单词提供了趣味的配图和例句,让记单词成为一种乐趣. 百词斩覆 ...
- Java中的public、protected、default和private的区别
(1) 对于public修饰符,它具有最大的访问权限,可以访问任何一个在CLASSPATH下的类.接口.异常等.它往往用于对外的情况,也就是对象或类对外的一种接口的形式. (2) ...
- poj 1182 食物链 (并查集)
http://poj.org/problem?id=1182 关于并查集 很好的一道题,开始也看了一直没懂.这次是因为<挑战程序设计竞赛>书上有讲解看了几遍终于懂了.是一种很好的思路,跟网 ...