4.深入TiDB:执行计划执行过程详解
本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/598
上一篇讲解了 TiDB 的执行优化相关的内容,这篇我们继续往下看,在获取到执行优化结果之后如何执行整个计划。
我们这里还是使用一个简单的例子:
CREATE TABLE student
(
id VARCHAR(31),
name VARCHAR(50),
age int,
key id_idx (id)
);
INSERT INTO student VALUES ('pingcap001', 'pingcap', 13);
select name from student where age>10;
我们直接看到 session/session.go 下的 ExecuteStmt() 方法 :
func (s *session) ExecuteStmt(ctx context.Context, stmtNode ast.StmtNode) (sqlexec.RecordSet, error) {
...
compiler := executor.Compiler{Ctx: s}
// 制定查询计划以及优化
stmt, err := compiler.Compile(ctx, stmtNode)
...
// Execute the physical plan.
logStmt(stmt, s)
recordSet, err := runStmt(ctx, s, stmt)
...
return recordSet, nil
}
在上一篇讲解了 compiler.Compile 制定会调用到 Optimize 制定逻辑计划和物理计划相关的代码,下面主要是讲解 runStmt 这部分,它主要作用是根据制定好的执行计划去 TiKV 中获取相关的数据。
func runStmt(ctx context.Context, se *session, s sqlexec.Statement) (rs sqlexec.RecordSet, err error) {
...
// 校验用户使用 rollback、commit 这种显示关闭事务的 SQL 中断执行
err = se.checkTxnAborted(s)
if err != nil {
return nil, err
}
//执行 SQL,并返回 rs 结果集
rs, err = s.Exec(ctx)
se.updateTelemetryMetric(s.(*executor.ExecStmt))
sessVars.TxnCtx.StatementCount++
if rs != nil {
return &execStmtResult{
RecordSet: rs,
sql: s,
se: se,
}, err
}
//在执行完语句后,检查是否该提交了
err = finishStmt(ctx, se, err, s)
if se.hasQuerySpecial() {
se.SetValue(ExecStmtVarKey, s.(*executor.ExecStmt))
} else {
s.(*executor.ExecStmt).FinishExecuteStmt(origTxnCtx.StartTS, err, false)
}
return nil, err
}
runStmt 这段代码中,我们直接进入到 Exec 继续跟踪执行相关代码。
func (a *ExecStmt) Exec(ctx context.Context) (_ sqlexec.RecordSet, err error) {
...
// 生成执行器
e, err := a.buildExecutor()
if err != nil {
return nil, err
}
ctx = a.setPlanLabelForTopSQL(ctx)
// 根据不同执行者进行不同的处理
if err = e.Open(ctx); err != nil {
terror.Call(e.Close)
return nil, err
}
...
return &recordSet{
executor: e,
stmt: a,
txnStartTS: txnStartTS,
}, nil
}
构建 Executor
我们在构建执行计划的时候,会根据 SQL 语句生成各种各样的算子,所以这里会根据算子构建不同的 Executor ,然后再执行 Open 进行数据处理。
我们先看看生成执行器 buildExecutor :
func (a *ExecStmt) buildExecutor() (Executor, error) {
ctx := a.Ctx
...
// 新建一个构造者
b := newExecutorBuilder(ctx, a.InfoSchema, a.Ti, a.SnapshotTS, a.ExplicitStaleness, a.TxnScope)
text := a.Text
if strings.Contains(text, "student") {
fmt.Println(text)
}
//根据执行计划构建 Executor
e := b.build(a.Plan)
if b.err != nil {
return nil, errors.Trace(b.err)
}
...
return e, nil
}
这里构建好的 ExecutorBuilder 会根据执行计划构建 Executor。对于我们上面的查询例子:
select name from student where age>10;
对于这个查询条件来说生成的物理执行计划大概是这样:
TableReader(Table(student)->Sel([gt(test.student.age, 1)])->Limit)->Limit
最外层是一个 PhysicalLimit,内部是 PhysicalTableReader。所以在执行 executorBuilder 的 build 方法的时候会根据类型进行判断进入到 buildLimit 中:
func (b *executorBuilder) build(p plannercore.Plan) Executor {
switch v := p.(type) {
case nil:
return nil
// 根据执行计划类型进入不同的build方法中
case *plannercore.PhysicalTableReader:
return b.buildTableReader(v)
case *plannercore.PhysicalLimit:
return b.buildLimit(v)
...
default:
if mp, ok := p.(MockPhysicalPlan); ok {
return mp.GetExecutor()
}
b.err = ErrUnknownPlan.GenWithStack("Unknown Plan %T", p)
return nil
}
}
这里的执行计划的类型有好几十种,我这里先看看 buildLimit,其他方法感兴趣的可以自己去看看。
func (b *executorBuilder) buildLimit(v *plannercore.PhysicalLimit) Executor {
// 获取子计划的Executor
childExec := b.build(v.Children()[0])
if b.err != nil {
return nil
}
n := int(mathutil.MinUint64(v.Count, uint64(b.ctx.GetSessionVars().MaxChunkSize)))
base := newBaseExecutor(b.ctx, v.Schema(), v.ID(), childExec)
base.initCap = n
// 构建 limit executor
e := &LimitExec{
baseExecutor: base,
begin: v.Offset,
end: v.Offset + v.Count,
}
...
return e
}
buildLimit 会获取子计划的 Executor,然后构建 limit executor。这里子计划就是 PhysicalTableReader,所以再次进入到 build 方法中会调用 buildTableReader 进行构建:
func (b *executorBuilder) buildTableReader(v *plannercore.PhysicalTableReader) Executor {
...
// 先构建一个无范围的 TableReaderExecutor
ret, err := buildNoRangeTableReader(b, v)
if err != nil {
b.err = err
return nil
}
// 通过递归执行计划来更新TableReaderExecutor范围
ts := v.GetTableScan()
ret.ranges = ts.Ranges
sctx := b.ctx.GetSessionVars().StmtCtx
sctx.TableIDs = append(sctx.TableIDs, ts.Table.ID)
// 如果不使用动态分区进行修建则直接返回
if !b.ctx.GetSessionVars().UseDynamicPartitionPrune() {
return ret
}
...
return ret
}
这里先是调用 buildNoRangeTableReader 函数构建一个无范围的 TableReaderExecutor,然后调用 GetTableScan 递归执行计划获取 table plan 的 PhysicalTableScan,然后从中获取 Ranges 填充 Executor 的范围。
发送请求给 TiKV
这里获取到 Executor 之后继续回到 ExecStmt 的 Exec 中 执行 Executor 的 Open 方法:
func (e *LimitExec) Open(ctx context.Context) error {
// 遍历子 Executor 执行其 Open 方法
if err := e.baseExecutor.Open(ctx); err != nil {
return err
}
e.childResult = newFirstChunk(e.children[0])
e.cursor = 0
e.meetFirstBatch = e.begin == 0
return nil
}
需要注意的是,我们上面的查询中,先是构建的 LimitExec ,它里面封装的才是 TableReaderExecutor ,所以它继续会调用到 TableReaderExecutor 的 Open 方法中。
func (e *TableReaderExecutor) Open(ctx context.Context) error {
...
firstPartRanges, secondPartRanges := distsql.SplitRangesAcrossInt64Boundary(e.ranges, e.keepOrder, e.desc, e.table.Meta() != nil && e.table.Meta().IsCommonHandle)
...
// 将 firstPartRanges 进行执行,请求TiKV并获取返回的结果
firstResult, err := e.buildResp(ctx, firstPartRanges)
if err != nil {
e.feedback.Invalidate()
return err
}
// 当 secondPartRanges 没有时,直接将第一部分结果进行整合
if len(secondPartRanges) == 0 {
e.resultHandler.open(nil, firstResult)
return nil
}
// 当 secondPartRanges 存在值时,请求TiKV并获取返回的结果
var secondResult distsql.SelectResult
//发送请求
secondResult, err = e.buildResp(ctx, secondPartRanges)
if err != nil {
e.feedback.Invalidate()
return err
}
// 将两部分的结果进行整合
e.resultHandler.open(firstResult, secondResult)
return nil
}
SplitRangesAcrossInt64Boundary 其实就是将 ranges 列表进行拆分,通过看注释:
// SplitRangesAcrossInt64Boundary split the ranges into two groups:
// 1. signedRanges is less or equal than MaxInt64
// 2. unsignedRanges is greater than MaxInt64
//
// We do this because every key of tikv is encoded as an int64. As a result, MaxUInt64 is small than zero when
// interpreted as an int64 variable.
//
// This function does the following:
// 1. split ranges into two groups as described above.
// 2. if there's a range that straddles the int64 boundary, split it into two ranges, which results in one smaller and
// one greater than MaxInt64.
我们可以知道,因为 tikv 的每个 key 都是 int64,所以像 UInt64 这个无符号类型的最大值其实是大于 Int64 的,所以需要进行拆分。拆分的结果分为两部分,signedRanges 表示的是小于等于 MaxInt64 的集合,unsignedRanges 表示的是大于 MaxInt64 集合。
接下来会调用 buildResp 构建 kv.Request,然后调用 SelectResult 向 kv client 发送请求返回 SelectResult 结构体:
func (e *TableReaderExecutor) buildResp(ctx context.Context, ranges []*ranger.Range) (distsql.SelectResult, error) {
...
// build Request
kvReq, err := e.buildKVReq(ctx, ranges)
if err != nil {
return nil, err
}
e.kvRanges = append(e.kvRanges, kvReq.KeyRanges...)
// sends a DAG request, returns SelectResult
result, err := e.SelectResult(ctx, e.ctx, kvReq, retTypes(e), e.feedback, getPhysicalPlanIDs(e.plans), e.id)
if err != nil {
return nil, err
}
return result, nil
}
返回的 SelectResult 可以认为它是一个迭代器,因为下层是有很多 TiKV ,然后每个结果是一个 PartialResult,所以也可以说它是 PartialResult 的迭代器。
type SelectResult interface {
// NextRaw gets the next raw result.
NextRaw(context.Context) ([]byte, error)
// Next reads the data into chunk.
Next(context.Context, *chunk.Chunk) error
// Close closes the iterator.
Close() error
}
SelectResult 这个接口,代表了一次查询的所有结果的抽象,计算是以 Region 为单位进行,所以这里全部结果会包含所有涉及到的 Region 的结果。通过 SelectResult 的 next 方法可以拿到下一个 PartialResult 。
在 buildResp 方法中调用 SelectResult 方法里面最后会调用到 DistSQL 包提供的 Select API:
func Select(ctx context.Context, sctx sessionctx.Context, kvReq *kv.Request, fieldTypes []*types.FieldType, fb *statistics.QueryFeedback) (SelectResult, error) {
...
resp := sctx.GetClient().Send(ctx, kvReq, sctx.GetSessionVars().KVVars, sctx.GetSessionVars().StmtCtx.MemTracker, enabledRateLimitAction)
if resp == nil {
err := errors.New("client returns nil response")
return nil, err
}
...
return &selectResult{
label: "dag",
resp: resp,
rowLen: len(fieldTypes),
fieldTypes: fieldTypes,
ctx: sctx,
feedback: fb,
sqlType: label,
memTracker: kvReq.MemTracker,
encodeType: encodetype,
storeType: kvReq.StoreType,
}, nil
}
它提供了向 TiKV Client 发送请求并构建 selectResult 能力。
用一张官方的图来说明一下整个查询过程:
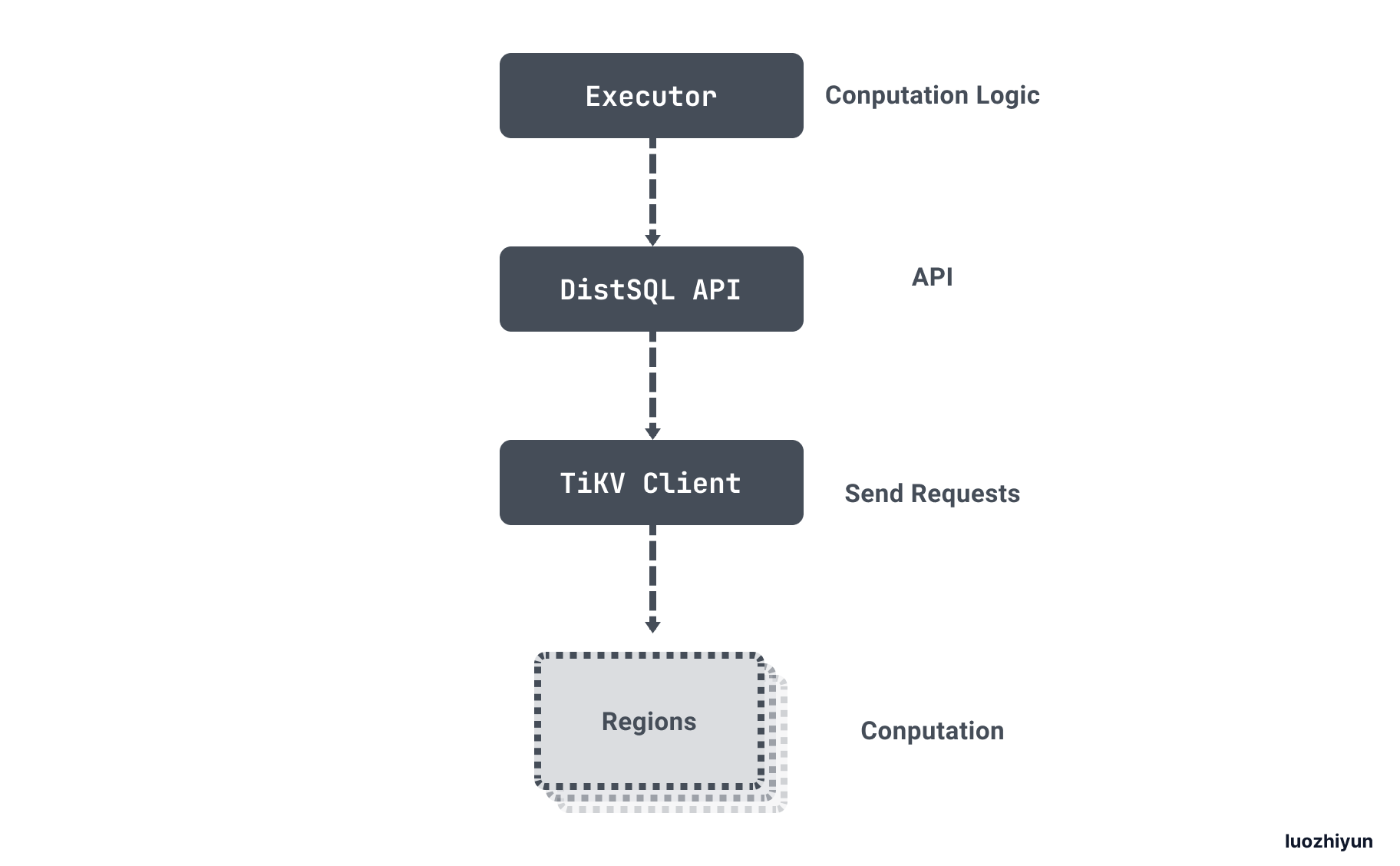
获取 TiKV 数据
我们继续顺着 Select 方法里面 Send 方法往下看。
func (c *CopClient) Send(ctx context.Context, req *kv.Request, variables interface{}, sessionMemTracker *memory.Tracker, enabledRateLimitAction bool) kv.Response {
...
ranges := NewKeyRanges(req.KeyRanges)
// 根据ranges构建task
tasks, err := buildCopTasks(bo, c.store.GetRegionCache(), ranges, req)
if err != nil {
return copErrorResponse{err}
}
// 构建 copIterator
it := &copIterator{
store: c.store,
req: req,
concurrency: req.Concurrency,
finishCh: make(chan struct{}),
vars: vars,
memTracker: req.MemTracker,
replicaReadSeed: c.replicaReadSeed,
rpcCancel: tikv.NewRPCanceller(),
resolvedLocks: util.NewTSSet(5),
}
it.tasks = tasks
// 设置并行度
if it.concurrency > len(tasks) {
it.concurrency = len(tasks)
}
if it.concurrency < 1 {
it.concurrency = 1
}
// 设置限流器和传输数据的 channel
if it.req.KeepOrder {
it.sendRate = util.NewRateLimit(2 * it.concurrency)
// 如果要求有序,那么就不用全局的 chanel
it.respChan = nil
} else {
capacity := it.concurrency
if enabledRateLimitAction {
capacity = it.concurrency * 2
}
// 如果无序,那么会将response数据放入到全局的 channel 中
it.respChan = make(chan *copResponse, capacity)
it.sendRate = util.NewRateLimit(it.concurrency)
}
it.actionOnExceed = newRateLimitAction(uint(it.sendRate.GetCapacity()))
if sessionMemTracker != nil {
sessionMemTracker.FallbackOldAndSetNewAction(it.actionOnExceed)
}
if !it.req.Streaming {
ctx = context.WithValue(ctx, tikv.RPCCancellerCtxKey{}, it.rpcCancel)
}
// 启动多个 goroutine 获取 response
it.open(ctx, enabledRateLimitAction)
return it
}
首先是调用 buildCopTasks 构建 coprocessor task。在调用 buildCopTasks 的时候会传入 RegionCache,因为我们的数据可能会分布在多个 region 中,所以我们可以根据它找到有哪些 region 包含了一个 key range 范围内的数据。然后按照 region 的 range 把 key range list 进行切分构建好 coprocessor task 返回。
获取到 task 列表之后会创建 copIterator, 是 kv.Response接口的实现,需要实现对应 Next方法,在上层调用 Next 的时候,返回一个 coprocessor response ,上层通过多次调用 Next 方法,获取多个 coprocessor response,直到所有结果获取完。
type Response interface {
// Next returns a resultSubset from a single storage unit.
// When full result set is returned, nil is returned.
Next(ctx context.Context) (resultSubset ResultSubset, err error)
// Close response.
Close() error
}
为了增大并行度,在调用 open 的时候构造多个 goroutine 充当 worker 来执行 task,多个 worker 从这一个 channel 读取 task,执行完成后,把结果发到 response channel,通过设置 worker 的数量控制并发度 。
需要注意的是在调用 open 执行 task 之前会校验 task 是不是有序的,如果是有序的,那么 worker 执行完 task 之后就不能直接放入到 response channel 中了,因为并发结果是无序的。所以通过给每一个 task 创建一个 channel,把 response 发送到这个 task 自己的 response channel 里,Next 的时候,就可以按照 task 的顺序获取 response,保证结果的有序。
下面我们来看看实现细节。先来看看 buildCopTasks:
func buildCopTasks(bo *Backoffer, cache *RegionCache, ranges *KeyRanges, req *kv.Request) ([]*copTask, error) {
...
rangesLen := ranges.Len()
//找到有哪些 region 包含了一个 key range 范围内的数据
locs, err := cache.SplitKeyRangesByLocations(bo, ranges)
if err != nil {
return nil, errors.Trace(err)
}
var tasks []*copTask
//根据返回的 LocationKeyRanges 来构建 task
for _, loc := range locs {
// 这里是因为一个 region 里面可能也包含多个 Range
rLen := loc.Ranges.Len()
for i := 0; i < rLen; {
nextI := mathutil.Min(i+rangesPerTask, rLen)
tasks = append(tasks, &copTask{
region: loc.Location.Region,
ranges: loc.Ranges.Slice(i, nextI),
respChan: make(chan *copResponse, 2),
cmdType: cmdType,
storeType: req.StoreType,
})
i = nextI
}
}
...
return tasks, nil
}
这里我们看到 buildCopTasks 里面会根据传入的 RegionCache 来对 ranges 进行拆分,返回的 LocationKeyRanges 对象里面包含了 KeyRanges ,因为一个 region 里面可能也包含多个 Range,所以这里用了两层 for 循环进行遍历,创建好 task 之后返回。
我们再回到 Send 方法中,继续往下看 open 方法:
func (it *copIterator) open(ctx context.Context, enabledRateLimitAction bool) {
taskCh := make(chan *copTask, 1)
it.wg.Add(it.concurrency)
// 根据并发数创建 worker
for i := 0; i < it.concurrency; i++ {
worker := &copIteratorWorker{
taskCh: taskCh,
wg: &it.wg,
store: it.store,
req: it.req,
respChan: it.respChan,
finishCh: it.finishCh,
vars: it.vars,
kvclient: tikv.NewClientHelper(it.store.store, it.resolvedLocks),
memTracker: it.memTracker,
replicaReadSeed: it.replicaReadSeed,
actionOnExceed: it.actionOnExceed,
}
go worker.run(ctx)
}
taskSender := &copIteratorTaskSender{
taskCh: taskCh,
wg: &it.wg,
tasks: it.tasks,
finishCh: it.finishCh,
sendRate: it.sendRate,
}
taskSender.respChan = it.respChan
it.actionOnExceed.setEnabled(enabledRateLimitAction)
failpoint.Inject("ticase-4171", func(val failpoint.Value) {
if val.(bool) {
it.memTracker.Consume(10 * MockResponseSizeForTest)
it.memTracker.Consume(10 * MockResponseSizeForTest)
}
})
// 创建 sender
go taskSender.run()
}
这里我们看到了分别会创建两类 goroutine,一种是 worker 一种是 sender。
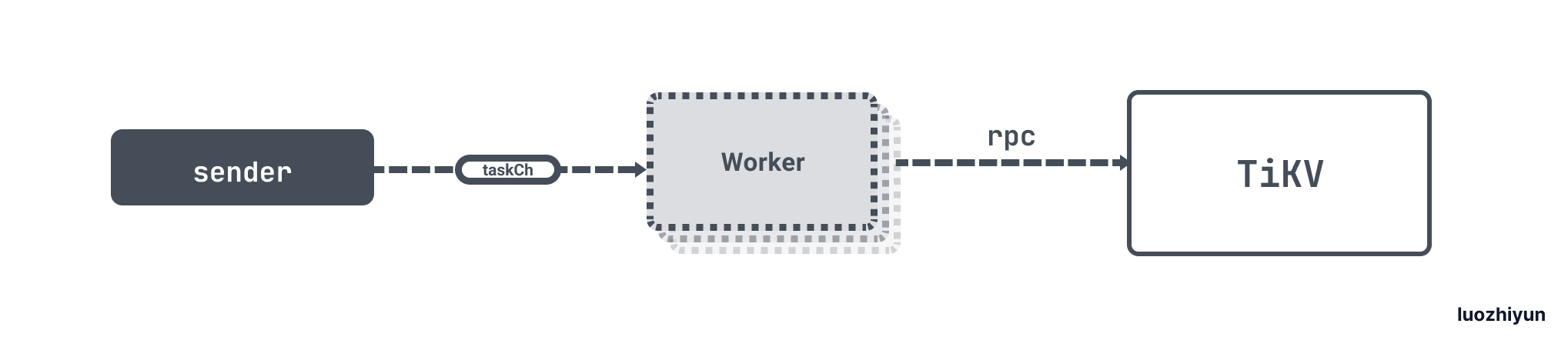
我们先来看看 sender:
func (sender *copIteratorTaskSender) run() {
for _, t := range sender.tasks {
// 使用限流器控制频率
exit := sender.sendRate.GetToken(sender.finishCh)
if exit {
break
}
// 发送task到taskCh中
exit = sender.sendToTaskCh(t)
if exit {
break
}
}
//发送完毕之后关闭 channel
close(sender.taskCh)
// Wait for worker goroutines to exit.
sender.wg.Wait()
if sender.respChan != nil {
close(sender.respChan)
}
}
sender 会将所有的 task 放入到 taskCh 中,发送完毕之后关闭 channel。下面再来看看 worker:
func (worker *copIteratorWorker) run(ctx context.Context) {
defer func() {
failpoint.Inject("ticase-4169", func(val failpoint.Value) {
if val.(bool) {
worker.memTracker.Consume(10 * MockResponseSizeForTest)
worker.memTracker.Consume(10 * MockResponseSizeForTest)
}
})
worker.wg.Done()
}()
for task := range worker.taskCh {
respCh := worker.respChan
// 这里是需要排序的时候为空,那么为每个 task 都创建一个 respChan
if respCh == nil {
respCh = task.respChan
}
// 发送rpc请求
worker.handleTask(ctx, task, respCh)
if worker.respChan != nil {
// 发送 finCopResp 到 respCh 中,告诉copIterator有一个task已经运行完毕了
worker.sendToRespCh(finCopResp, worker.respChan, false)
}
close(task.respChan)
if worker.vars != nil && worker.vars.Killed != nil && atomic.LoadUint32(worker.vars.Killed) == 1 {
return
}
select {
case <-worker.finishCh:
return
default:
}
}
}
worker 主要是处理 sender 发送过来的 taskCh 数据,通过遍历 taskCh 获取 task 之后调用 handleTask 发送 rpc 请求,返回的数据会放入到 respCh 中。需要注意这里如果是有序的 task ,那么 worker.respChan 为空,然后会为每个 task 创建一个 respChan,在获取数据的时候会根据每个 task 的 respChan 数据来做排序。
下面我们再来看看怎么获取数据:
上面我们也提到了,copIterator 其实就是一个迭代器,获取数据是通过调用 copIterator 的 Next 方法获取:
func (it *copIterator) Next(ctx context.Context) (kv.ResultSubset, error) {
var (
resp *copResponse
ok bool
closed bool
)
...
// 如果数据不需要排序,那么直接从 respChan 中获取数据
if it.respChan != nil {
// Get next fetched resp from chan
resp, ok, closed = it.recvFromRespCh(ctx, it.respChan)
if !ok || closed {
it.actionOnExceed.close()
return nil, nil
}
// 表示读到 respChan 最后一个数据
if resp == finCopResp {
it.actionOnExceed.destroyTokenIfNeeded(func() {
it.sendRate.PutToken()
})
return it.Next(ctx)
}
} else {
for {
if it.curr >= len(it.tasks) {
// Resp will be nil if iterator is finishCh.
it.actionOnExceed.close()
return nil, nil
}
// 如果数据是有序的,那么从 task 的 respChan 获取数据
task := it.tasks[it.curr]
resp, ok, closed = it.recvFromRespCh(ctx, task.respChan)
if closed {
return nil, nil
}
if ok {
break
}
it.actionOnExceed.destroyTokenIfNeeded(func() {
it.sendRate.PutToken()
})
it.tasks[it.curr] = nil
it.curr++
}
}
if resp.err != nil {
return nil, errors.Trace(resp.err)
}
err := it.store.CheckVisibility(it.req.StartTs)
if err != nil {
return nil, errors.Trace(err)
}
return resp, nil
}
获取数据根据是否有序也是分为两种,无序的数据直接从 copIterator 的 respChan 中获取数据,如果是有序的,那么需要获取到 task 里面的 respChan 来获取数据。
Reference
https://blog.minifish.org/posts/tidb4/
https://zhuanlan.zhihu.com/p/337939383
https://pingcap.com/zh/blog/mpp-smp-tidb
https://pingcap.com/zh/blog/tikv-source-code-reading-14
https://pingcap.com/zh/blog/tidb-source-code-reading-19

4.深入TiDB:执行计划执行过程详解的更多相关文章
- oracle获取执行计划及优缺点 详解
一.获取执行计划的6种方法(详细步骤已经在每个例子的开头注释部分说明了):1. explain plan for获取: 2. set autotrace on : 3. statistics_leve ...
- MySQL执行计划中key_len详解
(1).索引字段的附加信息:可以分为变长和定长数据类型讨论,当索引字段为定长数据类型,比如char,int,datetime,需要有是否为空的标记,这个标记需要占用1个字节:对于变长数据类型,比如:v ...
- mysql中SQL执行过程详解与用于预处理语句的SQL语法
mysql中SQL执行过程详解 客户端发送一条查询给服务器: 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果.否则进入下一阶段. 服务器段进行SQL解析.预处理,在优化器生成对应的 ...
- MySQL 语句执行过程详解
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...
- oracle-SQL语句执行原理和完整过程详解
SQL语句执行过程详解 一条sql,plsql的执行到底是怎样执行的呢? 一.SQL语句执行原理 第一步:客户端吧语句发个服务端执行 当我们在客户端执行select语句时,客户端会把这条SQL语句发送 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- ping命令执行过程详解
[TOC] ping命令执行过程详解 机器A ping 机器B 同一网段 ping通知系统建立一个固定格式的ICMP请求数据包 ICMP协议打包这个数据包和机器B的IP地址转交给IP协议层(一组后台运 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- “全栈2019”Java多线程第八章:放弃执行权yield()方法详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- 《手把手教你》系列基础篇(八十一)-java+ selenium自动化测试-框架设计基础-TestNG如何暂停执行一些case(详解教程)
1.简介 在实际测试过程中,我们经常会遇到这样的情况,开发由于某些原因导致一些模块进度延后,而你的自动化测试脚本已经提前完成,这样就会有部分模块测试,有部分模块不能进行测试.这就需要我们暂时不让一些t ...
随机推荐
- Pikachu-暴力破解模块
一.概述 "暴力破解"是一攻击具手段,在web攻击中,一般会使用这种手段对应用系统的认证信息进行获取. 其过程就是使用大量的认证信息在认证接口进行尝试登录,直到得到正确的结果. 为 ...
- Linux 进程间传递文件描述符
文章目录 文件描述符 文件数据结构 共享文件 UNIX域socket实现传递文件描述符 进程间传递打开的文件描述符,并不是传递文件描述符的值.先说一下文件描述符. 文件描述符 对内核来说,所有打开的文 ...
- STM32—位带操作
STM32中的位带操作: 名字为位带操作,实际上是对位的操作,位操作就是可以单独的对一个比特位读和写,这个在 51 单片机中非常常见. 51 单片机中通过关键字 sbit 来实现位定义, STM32 ...
- java多线程的一些面试题
8.callable与fature Callable与Runnable类似,但是Callable有返回值,并且有一个参数化的类型. Fature保存异步计算的结果.9.执行器 Executor.10. ...
- Ant的使用(一)
<?xml version="1.0" encoding="UTF-8"?> <project name="projectName& ...
- transient用法
1 import java.io.FileInputStream; 2 import java.io.FileNotFoundException; 3 import java.io.FileOutpu ...
- Fllink学习
1.Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处 ...
- C# 实现图片上传
C# 实现图片上传 C#实现图片上传: 通过页面form表单提交数据到动作方法,动作方法实现保存图片到指定路径,并修改其文件名为时间格式 页面设置 这里使用的模板MVC自带的模板视图 <h2&g ...
- Docker | 入门 & 基础操作
Dcoker 入门 确保docker 已经安装好了,如没有装好的可以参考:Docker | 安装 运行第一个容器 docker run -it ubuntu /bin/bash docker run ...
- MyBatis-Plus 代码生成器模板
MyBatis-Plus 代码生成器模板 maven 依赖 <!--Mysql--> <dependency> <groupId>mysql</groupId ...